A pap-smear analysis tool (PAT) for detection of cervical cancer from pap-smear images
Image analysis
De image analysis pipeline for the development of a pap-smear analysis tool for the detection of cervical cancer from pap-smears presented in this paper is afgebeeld in Fig. 1.

de benadering om cervicale kankerdetectie te bereiken van pap-smear images
Beeldverwerving
De benadering werd beoordeeld met behulp van drie datasets. Dataset 1 bestaat uit 917 enkele cellen van Harlev pap-smear beelden bereid door Jantzen et al. . De dataset bevat pap-uitstrijkje beelden genomen met een resolutie van 0,201 µm / pixel door ervaren cytopathologen met behulp van een microscoop verbonden met een frame grabber. De beelden werden gesegmenteerd met behulp van commerciële software van CHAMP en vervolgens ingedeeld in zeven klassen met verschillende kenmerken zoals weergegeven in Tabel 2. Van deze 200 beelden werden gebruikt voor training en 717 beelden voor testen.
Dataset 2 bestaat uit 497 volledige dia-Pap-uitstrijkjes, gemaakt door Norup et al. . Van deze 200 beelden werden gebruikt voor training en 297 beelden voor het testen. Bovendien werd de prestaties van de classificeerder geëvalueerd op Dataset 3 van monsters van 60 uitstrijkjes (30 normaal en 30 abnormaal) verkregen uit het Mbarara Regional Referral Hospital (MRRH). De monsters werden afgebeeld met behulp van een Olympus bx51 bright-field microscoop uitgerust met een 40×, 0.95 NA lens en een Hamamatsu ORCA-05G 1.4 Mpx monochrome camera, wat een pixelgrootte geeft van 0,25 µm met 8-bit grijze diepte. Elk beeld werd vervolgens verdeeld in 300 gebieden met elk gebied tussen 200 en 400 cellen. Op basis van de meningen van de cytopathologen, werden 10.000 objecten in beelden afgeleid van de 60 verschillende pap-uitstrijkjes dia ‘ s geselecteerd waarvan 8000 vrijliggende cervicale epitheliale cellen (3000 normale cellen uit normale uitstrijkjes en 5000 abnormale cellen uit abnormale uitstrijkjes) en de resterende 2000 waren puin objecten. Deze pap-uitstrijkje segmentatie werd bereikt met behulp van trainbare Weka segmentatie toolkit om een pixel niveau segmentatie classifier te construeren.
beeldverbetering
een contrast local adaptive histogram equalization (CLAHE) werd toegepast op de afbeelding met grijswaarden voor beeldverbetering . In CLAHE is de selectie van clip-limit die de gewenste vorm van het histogram van het beeld specificeert van het grootste belang, omdat het de kwaliteit van het verbeterde beeld kritisch beïnvloedt. De optimale waarde van de clip-limiet werd empirisch geselecteerd met behulp van de methode gedefinieerd door Joseph et al. . Een optimale clipgrenswaarde van 2.0 werd geschikt geacht voor het leveren van adequate beeldverbetering met behoud van de donkere functies voor de gebruikte datasets. De omzetting in grijstinten werd bereikt gebruikend een grijstintentechniek die gebruikend Eq wordt geà mplementeerd. 1 zoals gedefinieerd in .
waarbij R = rood, G = groen en B = blauwe kleurbijdragen aan de nieuwe afbeelding.
toepassing van CLAHE voor beeldversterking resulteerde in merkbare veranderingen in de beelden door de beeldintensiteit aan te passen waarbij de verduistering van de kern en de grenzen van het cytoplasma gemakkelijk identificeerbaar werden met behulp van een cliplimiet van 2,0.
Scene segmentatie
om scene segmentatie te bereiken, werd een pixel niveau classifier ontwikkeld met behulp van Trainable WEKA Segmentation (TWS) toolkit. De meerderheid van de cellen waargenomen in een pap-uitstrijkje zijn niet verrassend cervicale epitheliale cellen . Bovendien zijn variërende aantallen leukocyten, erytrocyten en bacteriën gewoonlijk duidelijk, terwijl kleine aantallen andere besmettende cellen en micro-organismen soms worden waargenomen. Echter, het pap-uitstrijkje bevat vier belangrijke types van plaveiselcel cervicale cellen-oppervlakkige, intermediaire, parabasale en basale-waarvan oppervlakkige en intermediaire cellen de overweldigende meerderheid in een conventionele uitstrijkje vertegenwoordigen; vandaar dat deze twee types worden meestal gebruikt voor een conventionele pap-uitstrijkje analyse . Een trainbare WEKA segmentatie werd gebruikt om de verschillende objecten op de dia te identificeren en te segmenteren. In dit stadium, werd een pixel niveau classifier opgeleid op celkernen, cytoplasma, achtergrond en puin identificatie met de hulp van een bekwame cytopathologist gebruikend Trainable Weka Segmentation (TWS) toolkit . Dit werd bereikt door lijnen/selectie door de gebieden van belang te trekken en deze toe te wijzen aan een bepaalde klasse. De pixels onder de lijnen / selectie werden beschouwd als de vertegenwoordiger van de kernen, cytoplasma, achtergrond en puin.
de contouren binnen elke klasse werden gebruikt om een feature vector te genereren, \(\mathop F\limits^{ \to }\) Die werd afgeleid van het aantal pixels dat bij elke contour hoort. De feature vector van elke afbeelding (200 van Dataset 1 en 200 van Dataset 2) werd gedefinieerd door Eq. 2.
waarbij Ni, Ci, Bi en Di het aantal pixels van de kern, cytoplasma, achtergrond en puin van afbeelding \(i\) zijn zoals weergegeven in Fig. 2.

Generation of the feature vector from the training images
elke pixel die uit de afbeelding wordt geëxtraheerd vertegenwoordigt niet alleen de intensiteit, maar ook een set afbeeldingseigenschappen die veel informatie inclusief textuur, randen en kleur binnen een pixeloppervlak van 0,201 µm2. Het kiezen van een geschikte feature vector voor de opleiding van de classifier was een grote uitdaging en een nieuwe taak in de voorgestelde aanpak. De pixel level classifier werd getraind met in totaal 226 trainingsfuncties van TWS. De classifier werd getraind met behulp van een set TWS-trainingsfuncties waaronder: (I) Ruisonderdrukking: de Kuwahara en bilaterale filters in de TWS-toolkit werden gebruikt om de classifier te trainen op ruisverwijdering. Dit zijn uitstekende filters voor het verwijderen van ruis met behoud van de randen, (ii) randdetectie: een Sobel-filter , Hessische matrix en Gabor-filter werden gebruikt voor het trainen van de classifier op grensdetectie in een afbeelding, en (iii) textuurfiltering: De gemiddelde, variantie -, mediaan -, maximum -, minimum-en entropiefilters werden gebruikt voor textuurfiltering.
verwijdering van vuil
De belangrijkste reden voor de huidige beperkingen van veel van de bestaande geautomatiseerde pap-smear analyse systemen is dat ze moeite hebben om de complexiteit van de pap-smear structuren te overwinnen, door te proberen de dia als geheel te analyseren, die vaak meerdere cellen en puin bevatten. Dit heeft het potentieel om het falen van het algoritme te veroorzaken en vereist hogere rekenkracht . De steekproeven worden behandeld in artefacten-zoals bloedcellen, overlappende en gevouwen cellen, en bacteriën—die de segmentatieprocessen belemmeren en een groot aantal verdachte voorwerpen produceren. Men heeft aangetoond dat classifiers ontworpen om tussen normale cellen en pre-kankercellen te onderscheiden gewoonlijk onvoorspelbare resultaten veroorzaken wanneer artefacten in het uitstrijkje bestaan . In deze tool, een techniek om baarmoederhals cellen te identificeren met behulp van een driefasige sequentiële eliminatie schema (afgebeeld in Fig. 3) wordt gebruikt.

driefasige sequentiële eliminatiebenadering voor afvalafstoting
het voorgestelde driefasige eliminatieschema verwijdert achtereenvolgens puin uit het uitstrijkje indien dit onwaarschijnlijk wordt geacht een baarmoederhals cel. Deze aanpak is gunstig omdat het in elke fase een lager-dimensionale beslissing mogelijk maakt.
Grootteanalyse
Grootteanalyse is een reeks procedures voor het bepalen van een reeks groottemetingen van deeltjes . Het gebied is één van de basiseigenschappen die op het gebied van geautomatiseerde cytologie worden gebruikt om cellen van puin te scheiden. De pap-smear analyse is een goed bestudeerd veld met veel voorkennis met betrekking tot Celeigenschappen . Een van de belangrijkste veranderingen bij de beoordeling van het kerngebied is echter dat kankercellen een aanzienlijke toename van de nucleaire omvang ondergaan . Daarom is het bepalen van een bovenste groottedrempel die diagnostische cellen niet systematisch uitsluit veel moeilijker, maar heeft het voordeel dat de zoekruimte wordt verminderd. De methode die in dit document wordt gepresenteerd is gebaseerd op een lagere grootte en bovenste grootte drempel van de cervicale cellen. De pseudo-code voor de aanpak wordt weergegeven in Eq. 3.
waar \(Area_{max} = 85,267\,{\upmu \text{m}}^{2}\) en \(Area_{min} = 625\,{\upmu \text{m}}^{2}\) afgeleid uit Tabel 2.
de objecten op de achtergrond worden beschouwd als puin en dus verwijderd van de afbeelding. Deeltjes die tussen \(Area_{min}\) en \(Area_{max}\) vallen, worden verder geanalyseerd tijdens de volgende stadia van textuur-en vormanalyse.
Shape analysis
de vorm van de objecten in een uitstrijkje is een belangrijk kenmerk in de differentiatie tussen cellen en puin . Er zijn een aantal methoden voor de detectie van vormbeschrijvingen en deze omvatten regio-gebaseerde en contour-gebaseerde benaderingen . Regio-gebaseerde methoden zijn minder gevoelig voor lawaai, maar meer rekenintensief, terwijl contour-gebaseerde methoden relatief efficiënt zijn om te berekenen, maar gevoeliger voor lawaai . In dit artikel is een regio-gebaseerde methode (perimeter2/gebied (P2A)) gebruikt . De p2a-descriptor werd gekozen op grond van de verdienste dat het de gelijkenis van een object met een cirkel beschrijft. Dit maakt het goed geschikt als een celkerndescriptor aangezien kernen over het algemeen cirkelvormig zijn in hun verschijning. De p2a wordt ook aangeduid als vorm compactheid en wordt gedefinieerd door Eq. 4.
waarbij c de waarde is van vormcompactheid, A het gebied is en p de omtrek van de kern. Puin werd verondersteld objecten te zijn met een P2A-waarde groter dan 0,97 of kleiner dan 0,15 volgens de trainingskenmerken (afgebeeld in Tabel 2).
Textuuranalyse
textuur is een zeer belangrijk kenmerk dat een onderscheid kan maken tussen kernen en puin. Beeldtextuur is een reeks metrics ontworpen om de waargenomen textuur van een beeld te kwantificeren . Binnen een uitstrijkje, is de verdeling van de gemiddelde nucleaire vlek intensiteit veel smaller dan de vlek intensiteit variatie tussen puin objecten . Dit feit werd gebruikt als basis om puin te verwijderen op basis van hun beeldintensiteit en kleurinformatie met behulp van Zernike moments (ZM) . Zernike moments worden gebruikt voor verschillende patroonherkenningstoepassingen en staan erom bekend dat ze robuust zijn met betrekking tot ruis en een goede reconstructie vermogen hebben. In dit werk, de ZM zoals gepresenteerd door Malm et al. van orde n met Herhaling I van functie \(f\left ({r, \ theta } \ right)\), in poolcoördinaten binnen een schijf gecentreerd in vierkant beeld \(I\left( {x,y} \right)\) van grootte \(M \keer m\) gegeven door Eq. 5 werd gebruikt.
\(v_{nl }^{*} \left( {r,\theta } \right)\) geeft de complex geconjugeerde van het Zernike polynoom \(v_{nl} \left( {r,\theta } \right)\). Om een textuurmaat te produceren, worden magnitudes van \(a_{nl}\) gecentreerd op elke pixel in de textuurafbeelding gemiddeld .
Feature extraction
het succes van een classificatiealgoritme hangt sterk af van de juistheid van de features uit de afbeelding. De cellen in de uitstrijkjes in de gebruikte dataset zijn verdeeld in zeven klassen op basis van kenmerken zoals grootte, Oppervlakte, vorm en helderheid van de kern en cytoplasma. De functies uit de beelden opgenomen morfologie functies eerder gebruikt door anderen . In dit artikel werden ook drie geometrische kenmerken (stevigheid, compactheid en excentriciteit) en zes tekstuele kenmerken (gemiddelde, standaardafwijking, variantie, gladheid, energie en entropie) geëxtraheerd uit de kern, resulterend in 29 kenmerken in totaal zoals weergegeven in Tabel 3.
Feature selection
Feature selection is het proces van het selecteren van subsets van de geëxtraheerde functies die de beste classificatieresultaten geven. Onder deze functies geëxtraheerd, sommige kunnen ruis bevatten, terwijl de gekozen classifier kan niet gebruik maken van anderen. Daarom moet een optimale set van functies worden bepaald, eventueel door alle combinaties te proberen. Echter, wanneer er veel functies, de mogelijke combinaties exploderen in aantal en dit verhoogt de computationele complexiteit van het algoritme. Functie selectie algoritmen zijn in grote lijnen ingedeeld in de filter, wrapper en embedded methoden .
De methode die door het gereedschap wordt gebruikt combineert gesimuleerde gloeiing met een wikkelbenadering. Deze aanpak is voorgesteld in, maar, in dit document, de prestaties van de functie selectie wordt geëvalueerd met behulp van een dubbele-strategie random forest algoritme . Het gesimuleerde ontharden is een probabilistische techniek voor het benaderen van het globale optimum van een bepaalde functie. De aanpak is zeer geschikt om ervoor te zorgen dat de optimale set van functies wordt geselecteerd. De zoektocht naar de optimale set wordt geleid door een fitnesswaarde . Wanneer het gesimuleerde ontharden wordt gebeëindigd, worden alle verschillende subsets van eigenschappen vergeleken en geschiktste (dat wil zeggen, degene die het beste presteert) geselecteerd. De fitness value search werd verkregen met een wrapper waarbij k-voudige kruisvalidatie werd gebruikt om de fout op het classificatiealgoritme te berekenen. Verschillende combinaties van de geëxtraheerde functies worden voorbereid, geëvalueerd en vergeleken met andere combinaties. Een voorspellend model wordt vervolgens gebruikt om een combinatie van functies te evalueren en een score toe te wijzen op basis van modelnauwkeurigheid. De door de wikkel gegeven fitnessfout wordt door het gesimuleerde gloeialgoritme als fitnessfout gebruikt. Een fuzzy C-means algoritme werd verpakt in een black box, waaruit een geschatte fout werd verkregen voor de verschillende feature combinaties zoals weergegeven in Fig. 4.

de fuzzy C-means is verpakt in een zwart kader waaruit een geschatte fout wordt verkregen
Fuzzy C-means staat toe dat gegevenspunten in de dataset behoren tot alle van de clusters, met lidmaatschappen in het interval (0-1) zoals weergegeven in EQ. 6.
waarbij \(M_{ik}\) het lidmaatschap is voor gegevenspunt k naar clustercentrum i, \(d_{jk}\) de afstand is van clustercentrum j naar gegevenspunt k en q € een exponent is die bepaalt hoe sterk de lidmaatschappen moeten zijn. Het fuzzy C-means algoritme werd geà mplementeerd met behulp van de fuzzy toolbox in Matlab.
de defuzzificatie
een fuzzy C-means algoritme vertelt ons niet welke informatie de clusters bevatten en hoe die informatie gebruikt moet worden voor classificatie. Het bepaalt echter hoe datapunten het lidmaatschap van de verschillende clusters krijgen toegewezen en dit fuzzy lidmaatschap wordt gebruikt om de klasse van een datapunt te voorspellen . Dit wordt overwonnen door defuzzificatie. Er bestaan een aantal defuzzificatiemethoden . Echter, in deze tool, elk cluster heeft een fuzzy lidmaatschap (0-1) van alle klassen in de afbeelding. Trainingsgegevens worden toegewezen aan het dichtstbijzijnde cluster. Het percentage trainingsgegevens van elke klasse die tot cluster A behoort, geeft het clusterlidmaatschap aan, cluster A = tot de verschillende klassen, waarbij i de insluiting is in cluster A en j in het andere cluster. De intensiteitsmaat wordt toegevoegd aan de lidmaatschapsfunctie voor elk cluster met behulp van een fuzzy clustering defuzzification algoritme. Een populaire aanpak voor defuzzificatie van fuzzy partitie is de toepassing van het maximale lidmaatschap graad principe waar gegevenspunt k is toegewezen aan klasse m als, en alleen als, zijn lidmaatschap graad \(M_{ik}\) aan cluster i, is de grootste. Chuang et al. voorgesteld aanpassen van de lidmaatschapsstatus van elk gegevenspunt met behulp van de lidmaatschapsstatus van zijn buren.
in de voorgestelde aanpak wordt een defuzzificatiemethode op basis van Bayesiaanse waarschijnlijkheid gebruikt om een probabilistisch model van de ledenfunctie voor elk gegevenspunt te genereren en het model toe te passen op de afbeelding om de classificatiegegevens te produceren. Het probabilistische model wordt als volgt berekend:
-
converteer de mogelijke verdelingen in de partitiematrix (clusters) naar kansverdelingen.
-
construeer een probabilistisch model van de datadistributies zoals in .
-
pas het model toe om de classificatiegegevens voor elk gegevenspunt te produceren met behulp van Eq. 7.
waar \(P\Left( {a_{I} } \right),i = 0 \ldots .c\) is de voorafgaande waarschijnlijkheid van \(A_{i}\) die kan worden berekend met behulp van de methode waarbij de voorafgaande waarschijnlijkheid altijd evenredig is met de massa van elke klasse.
het aantal te gebruiken clusters werd bepaald om ervoor te zorgen dat het gebouwde model de gegevens op de best mogelijke manier kan beschrijven. Als te veel clusters worden gekozen, dan is er een risico van overfitting van het lawaai in de gegevens. Als er te weinig clusters worden gekozen, dan kan een slechte classifier het resultaat zijn. Daarom werd een analyse van het aantal clusters uitgevoerd tegen de fout van de kruisvalidatietest. Een optimaal aantal van 25 clusters werd bereikt en overtraining vond plaats boven dit aantal clusters. Een defuzzificatie-exponent van 1.0930 werd verkregen met 25 clusters, tienvoudige cross-validatie en 60 herhalingen en werd gebruikt om de fitness fout voor functie selectie te berekenen waar een totaal van 18 functies van de 29 functies werden geselecteerd voor de bouw van de classifier. De geselecteerde kenmerken waren: nucleus gebied; nucleus grijs niveau; nucleus Kortste diameter; nucleus langste; nucleus perimeter; maxima in nucleus; minima in nucleus; cytoplasm gebied; cytoplasm grijs niveau; cytoplasm perimeter; nucleus tot cytoplasm ratio; nucleus excentriciteit, nucleus standaarddeviatie, nucleus grijs niveau variantie; nucleus grijs niveau entropie; nucleus relatieve positie; nucleus grijs niveau gemiddelde en nucleus grijze waarden energie.
Classificatieevaluatie
in dit artikel werd het hiërarchische model van de werkzaamheid van diagnostische beeldvormingssystemen, voorgesteld door Fryback en Thornbury, aangenomen als leidend principe voor de evaluatie van het instrument, zoals weergegeven in Tabel 4.
sensitiviteit meet het aandeel van de werkelijke positieven die correct als zodanig worden geïdentificeerd, terwijl specificiteit het aandeel van de werkelijke negatieven die correct als zodanig worden geïdentificeerd meet. Gevoeligheid en specificiteit worden beschreven door Eq. 8.
waarbij TP = True positieven, FN = False negatieven, TN = True negatieven en FP = False positieven.
GUI ontwerp en integratie
de hierboven beschreven beeldverwerkingsmethoden zijn geïmplementeerd in Matlab en worden uitgevoerd via een Java graphical user interface (GUI) getoond in Fig. 5. De tool heeft een paneel waar een pap-uitstrijkje afbeelding wordt geladen en de cytotechnicus selecteert een geschikte methode voor scène segmentatie (gebaseerd op TWS classifier), puin verwijderen (gebaseerd op de drie sequentiële eliminatie aanpak) en grens detectie (indien nodig, met behulp van Canny rand detectie methode), waarna functies worden geëxtraheerd met behulp van de extract features knop.
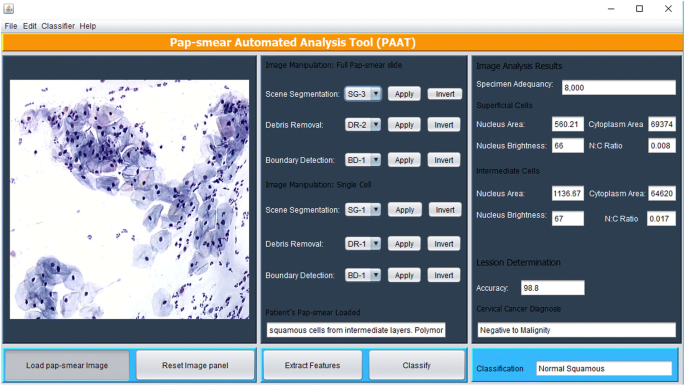
PAT grafische gebruikersinterface
het gereedschap scant door het uitstrijkje om alle objecten te analyseren die overbleven na het verwijderen van puin. De 18 functies beschreven in functie selectie worden geëxtraheerd uit elk object en gebruikt om elke cel te classificeren met behulp van de fuzzy C-means algoritme beschreven in de classificatiemethode. Willekeurig worden geëxtraheerde kenmerken van één oppervlakkige cel en één tussencel weergegeven in het paneel resultaten van de beeldanalyse. Zodra de functies zijn geëxtraheerd, drukt de cytotechnician (gebruiker) op de classificeerknop en het hulpmiddel zendt een diagnose uit (positief aan maligniteit of negatief aan maligniteit) en classificeert de diagnose aan één van de 7 klassen/stadia van baarmoederhalskanker volgens de trainingsdataset.