Blog
in een vorige blogpost hebben we besproken hoe supermarkten gegevens gebruiken om de behoeften van de consument beter te begrijpen en uiteindelijk hun totale uitgaven te verhogen. Een van de belangrijkste technieken die door de grote retailers wordt gebruikt, is Market Basket Analysis (MBA), die associaties tussen producten blootlegt door te zoeken naar combinaties van producten die vaak samen voorkomen in transacties. Met andere woorden, het stelt de supermarkten in staat om relaties te identificeren tussen de producten die mensen kopen. Klanten die bijvoorbeeld een potlood en papier kopen, kopen waarschijnlijk een rubber of liniaal.
“Market Basket Analysis stelt retailers in staat relaties te identificeren tussen de producten die mensen kopen.”
Retailers kunnen de inzichten uit MBA op een aantal manieren gebruiken, waaronder:
- groeperen van producten die samen voorkomen in het ontwerp van de lay-out van een winkel om de kans op cross-selling te vergroten;
- aansturen van online-aanbevelingsmotoren (“klanten die dit product hebben gekocht hebben dit product ook bekeken”); en
- Targeting marketing campagnes door het verzenden van promotionele coupons naar klanten voor producten die verband houden met items die ze onlangs gekocht.
gegeven hoe populair en waardevol MBA is, dachten we dat we de volgende stap-voor-stap handleiding zouden maken die beschrijft hoe het werkt en hoe u uw eigen Marktmandanalyse zou kunnen uitvoeren.
Hoe werkt de analyse van de Marktkorf?
om een MBA uit te voeren hebt u eerst een gegevensverzameling van transacties nodig. Elke transactie vertegenwoordigt een groep items of producten die samen zijn gekocht en vaak aangeduid als een “itemset”. Bijvoorbeeld, een itemset kan zijn: {potlood, papier, nietjes, rubber} in welk geval al deze items zijn gekocht in een enkele transactie.
in een MBA worden de transacties geanalyseerd om de regels van associatie vast te stellen. Een regel zou bijvoorbeeld kunnen zijn: {pencil, paper} = > {rubber}. Dit betekent dat als een klant een transactie heeft die een potlood en papier bevat, ze waarschijnlijk ook geïnteresseerd zijn in het kopen van een rubber.
alvorens een regel toe te passen, moet een detailhandelaar weten of er voldoende bewijs is om aan te nemen dat het tot een gunstig resultaat zal leiden. We meten daarom de sterkte van een regel door de volgende drie metrics te berekenen (let op andere metrics zijn beschikbaar, maar dit zijn de drie meest gebruikte):
Ondersteuning: het percentage transacties dat alle items in een itemset bevat (bijvoorbeeld potlood, papier en rubber). Hoe hoger de ondersteuning hoe vaker de itemset optreedt. Regels met een hoge steun krijgen de voorkeur omdat ze waarschijnlijk van toepassing zullen zijn op een groot aantal toekomstige transacties.
vertrouwen: de waarschijnlijkheid dat een transactie die de items aan de linkerkant van de regel bevat (in ons voorbeeld, potlood en papier) ook het item aan de rechterkant bevat (een rubber). Hoe hoger het vertrouwen, hoe groter de kans dat het item aan de rechterkant zal worden gekocht of, met andere woorden, hoe groter het rendement dat u kunt verwachten voor een bepaalde regel.
Lift: de waarschijnlijkheid van alle items in een regel die samen voorkomen (ook bekend als de ondersteuning) gedeeld door het product van de waarschijnlijkheden van de items aan de linker-en rechterkant die zich voordoen alsof er geen associatie tussen hen. Bijvoorbeeld, als potlood, papier en rubber samen voorkwamen in 2,5% van alle transacties, potlood en papier in 10% van de transacties en rubber in 8% van de transacties, dan zou de lift: 0.025/(0.1*0.08) = 3.125. Een lift van meer dan 1 suggereert dat de aanwezigheid van potlood en papier verhoogt de kans dat een rubber zal ook optreden in de transactie. Over het geheel genomen vat lift de sterkte van de associatie tussen de producten aan de linker-en rechterkant van de regel samen; hoe groter de lift hoe groter de band tussen de twee producten.
om een Marktmandanalyse uit te voeren en potentiële regels te identificeren, wordt vaak een algoritme voor datamining, het “Apriori-algoritme” genoemd, gebruikt, dat in twee stappen werkt:
- systematisch itemsets identificeren die vaak voorkomen in de dataset met een ondersteuning die groter is dan een vooraf gespecificeerde drempelwaarde.
- Bereken de betrouwbaarheid van alle mogelijke regels gezien de frequente itemsets en houd alleen die met een betrouwbaarheid groter dan een vooraf gespecificeerde drempel.
de drempels waarop de ondersteuning en het vertrouwen moeten worden ingesteld, zijn door de gebruiker gespecificeerd en zullen waarschijnlijk verschillen tussen de reeksen transactiegegevens. R heeft wel standaardwaarden, maar we raden je aan hiermee te experimenteren om te zien hoe ze het aantal geretourneerde regels beïnvloeden (meer hierover hieronder). Tot slot, hoewel het Apriori algoritme geen lift gebruikt om regels vast te stellen, zul je in het volgende zien dat we lift gebruiken bij het verkennen van de regels die het algoritme retourneert.
Marktkorfanalyse uitvoeren in R
om aan te tonen hoe een MBA moet worden uitgevoerd.We hebben ervoor gekozen om R te gebruiken en, in het bijzonder, het arules-pakket. Voor degenen die geïnteresseerd zijn hebben we de R-code die we aan het einde van deze blog gebruikt.
Hier volgen we hetzelfde voorbeeld dat gebruikt wordt in het Arulesviz vignet en gebruiken we een dataset van boodschappen die 9.835 individuele transacties bevat met 169 items. Het eerste wat we doen is kijken naar de posten in de transacties en, in het bijzonder, plot de relatieve frequentie van de 25 meest voorkomende posten in Figuur 1. Dit is gelijk aan de ondersteuning van deze items waar elke itemset slechts het ene item bevat. Deze bar plot illustreert de boodschappen die vaak worden gekocht in deze winkel, en het is opmerkelijk dat de ondersteuning van zelfs de meest voorkomende items is relatief laag (bijvoorbeeld, het meest voorkomende item komt voor in slechts ongeveer 2,5% van de transacties). We gebruiken deze inzichten om de minimumdrempel te informeren bij het uitvoeren van het Apriori-algoritme; we weten bijvoorbeeld dat om het algoritme een redelijk aantal regels te laten retourneren we de ondersteuningsdrempel ruim onder 0.025 moeten instellen.
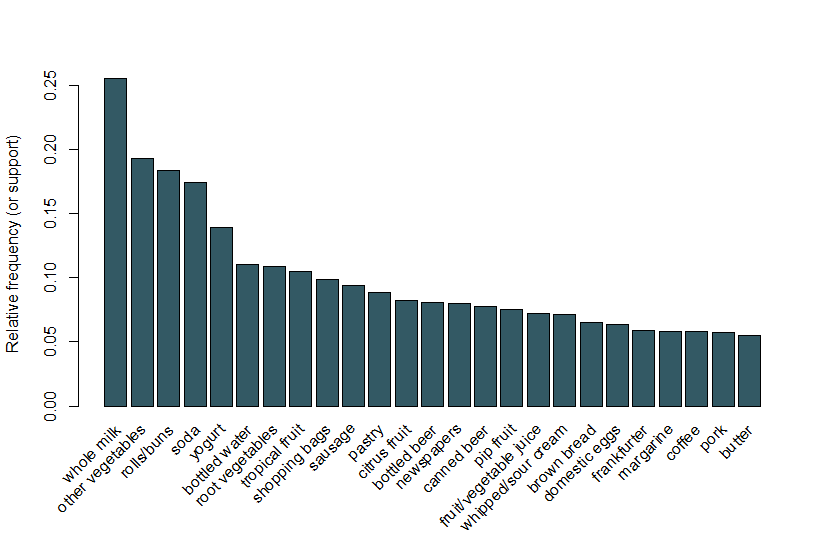
figuur 1 een staafdiagram van de ondersteuning van de 25 meest gekochte items.
door een ondersteuningsdrempel van 0,001 en een betrouwbaarheid van 0,5 in te stellen, kunnen we het Apriori-algoritme uitvoeren en een set van 5,668 resultaten verkrijgen. Deze drempelwaarden zijn zo gekozen dat het aantal teruggestuurde regels hoog is, maar dit aantal zou afnemen als we een van beide drempelwaarden zouden verhogen. We raden aan om met deze drempels te experimenteren om de meest geschikte waarden te verkrijgen. Er zijn te veel regels te kunnen bekijken ze allemaal individueel, kunnen we kijken naar de vijf regels met de grootste lift:
| de Regel | Ondersteuning | Vertrouwen | Lift |
| {instant levensmiddelen,frisdrank}=>{hamburger vlees} | 0.001 | 0.632 | 19.00 |
| {frisdrank, popcorn}=>{zoute snacks} | 0.001 | 0.632 | 16.70 |
| {flour, baking powder}=>{sugar} | 0.001 | 0.556 | 16.41 |
| {ham, processed cheese}=>{white bread} | 0.002 | 0.633 | 15.05 |
| {whole milk, instant food products}=>{hamburger meat} | 0.002 | 0.500 | 15.04 |
Table 1: The five rules with the largest lift.
These rules seem to make intuitive sense. Bijvoorbeeld, de eerste regel zou kunnen vertegenwoordigen het soort items gekocht voor een BBQ, de tweede voor een filmavond en de derde voor het bakken.
in plaats van de drempels te gebruiken om de regels terug te brengen tot een kleinere set, is het gebruikelijk dat een grotere set regels wordt geretourneerd, zodat er een grotere kans is om relevante regels te genereren. Als alternatief kunnen we visualisatietechnieken gebruiken om de teruggestuurde regels te inspecteren en de regels te identificeren die waarschijnlijk nuttig zijn.
met behulp van het arulesviz-pakket zetten we de regels uit op basis van vertrouwen, ondersteuning en lift in Figuur 2. Deze plot illustreert de relatie tussen de verschillende metrics. Het is aangetoond dat de optimale regels zijn die liggen op wat bekend staat als de “ondersteuning-vertrouwen grens”. In wezen zijn dit de regels die aan de rechterrand van het perceel liggen waar steun, vertrouwen of beide maximaal zijn. De plot-functie in het arulesviz-pakket heeft een nuttige interactieve functie waarmee u individuele regels kunt selecteren (door op het bijbehorende gegevenspunt te klikken), waardoor de regels aan de rand gemakkelijk kunnen worden geïdentificeerd.
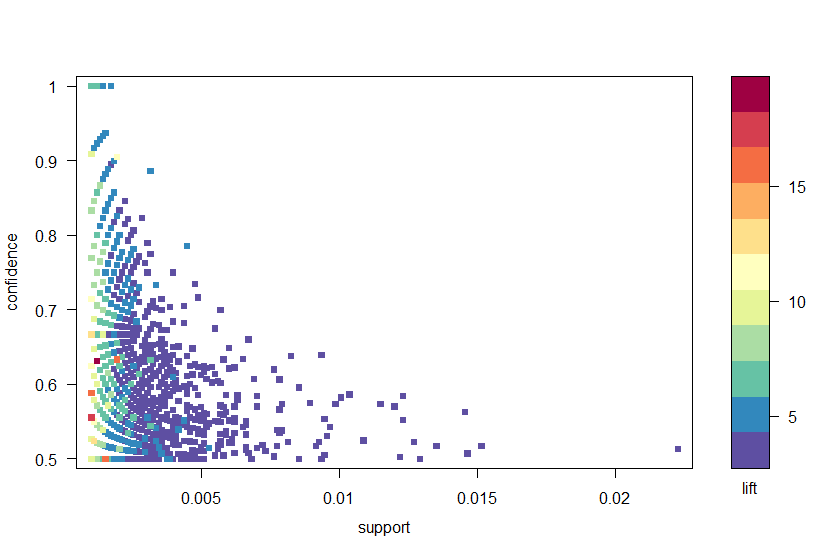
Figuur 2: een spreidingsdiagram van de betrouwbaarheids -, ondersteunings-en liftwaarden.
er zijn veel andere plots beschikbaar om de regels te visualiseren, maar een andere figuur die we zouden aanraden is de grafisch gebaseerde visualisatie (zie Figuur 3) van de top tien regels in termen van lift (u kunt meer dan tien toevoegen, maar dit soort grafieken kunnen gemakkelijk rommelig worden). In deze grafiek vertegenwoordigen de items gegroepeerd rond een cirkel een itemset en de pijlen geven de relatie in regels aan. Bijvoorbeeld, een regel is dat de aankoop van suiker wordt geassocieerd met de aankoop van meel en bakpoeder. De grootte van de cirkel geeft het betrouwbaarheidsniveau weer dat verbonden is met de regel en de kleur het niveau van de lift (hoe groter de cirkel en hoe donkerder de grijze hoe beter).
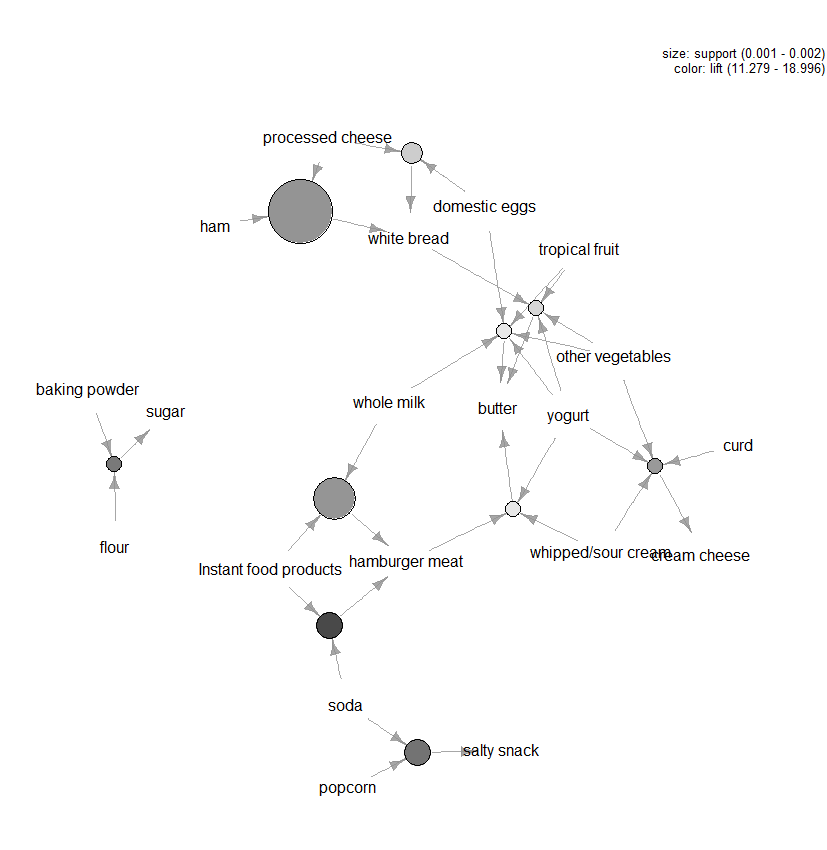
Figuur 3: grafisch gebaseerde visualisatie van de top tien regels in termen van lift.
Market Basket Analysis is een nuttig instrument voor retailers die de relaties tussen de producten die mensen kopen beter willen begrijpen. Er zijn veel tools die kunnen worden toegepast bij het uitvoeren van MBA en de lastigste aspecten van de analyse zijn het instellen van het vertrouwen en ondersteuning drempels in de Apriori algoritme en het identificeren van welke regels zijn de moeite waard nastreven. Typisch dit laatste wordt gedaan door het meten van de regels in termen van statistieken die samenvatten hoe interessant ze zijn, met behulp van visualisatie technieken en ook meer formele multivariate statistieken. Uiteindelijk is de sleutel tot MBA om waarde te halen uit uw transactiegegevens door het opbouwen van een begrip van de behoeften van uw consumenten. Dit soort informatie is van onschatbare waarde als u geïnteresseerd bent in marketingactiviteiten zoals cross-selling of gerichte campagnes.
Als u meer wilt weten over hoe u uw transactiegegevens kunt analyseren, neem dan contact met ons op en wij helpen u graag verder.
R Code
library("arules")
library("arulesViz")
#Load data set:
data("Groceries")
summary(Groceries)
#Look at data:
inspect(Groceries)
LIST(Groceries)
#Calculate rules using apriori algorithm and specifying support and confidence thresholds:
rules = apriori(Groceries, parameter=list(support=0.001, confidence=0.5))
#Inspect the top 5 rules in terms of lift:
inspect(head(sort(rules, by ="lift"),5))
#Plot a frequency plot:
itemFrequencyPlot(Groceries, topN = 25)
#Scatter plot of rules:
library("RColorBrewer")
plot(rules,control=list(col=brewer.pal(11,"Spectral")),main="")
#Rules with high lift typically have low support.
#The most interesting rules reside on the support/confidence border which can be clearly seen in this plot.