Detekce objektů pro Nechápavé Části 3: R-CNN Rodinu
V Části 3, budeme zkoumat čtyři detekce objektů modely: R-CNN, Fast R-CNN, Rychlejší R-CNN, a Maska R-CNN. Tyto modely jsou vysoce příbuzné a nové verze vykazují velké zlepšení rychlosti ve srovnání se staršími.
V sérii „Object Detection for Dummies“, začali jsme se základními pojmy ve zpracování obrazu, jako jsou gradientní vektory a PRASE, v Části 1. Pak jsme představili klasické konvoluční neuronové sítě architektura, návrhy pro klasifikaci a pioneer modely pro rozpoznávání objektů, Overfeat a DPM, v Části 2. Ve třetím příspěvku této série se chystáme přezkoumat sadu modelů v rodině R-CNN („CNN založená na regionu“).
odkazy na všechny příspěvky v sérii: .
zde je seznam článků obsažených v tomto příspěvku 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
R-CNN
R-CNN (Girshick et al., 2014) is short for „Region-based Convolutional Neural Networks“. The main idea is composed of two steps. Nejprve pomocí selektivního vyhledávání identifikuje zvládnutelný počet kandidátů na oblast objektů ohraničujícího pole („oblast zájmu „nebo“ návratnost investic“). A pak extrahuje funkce CNN z každé oblasti nezávisle na klasifikaci.
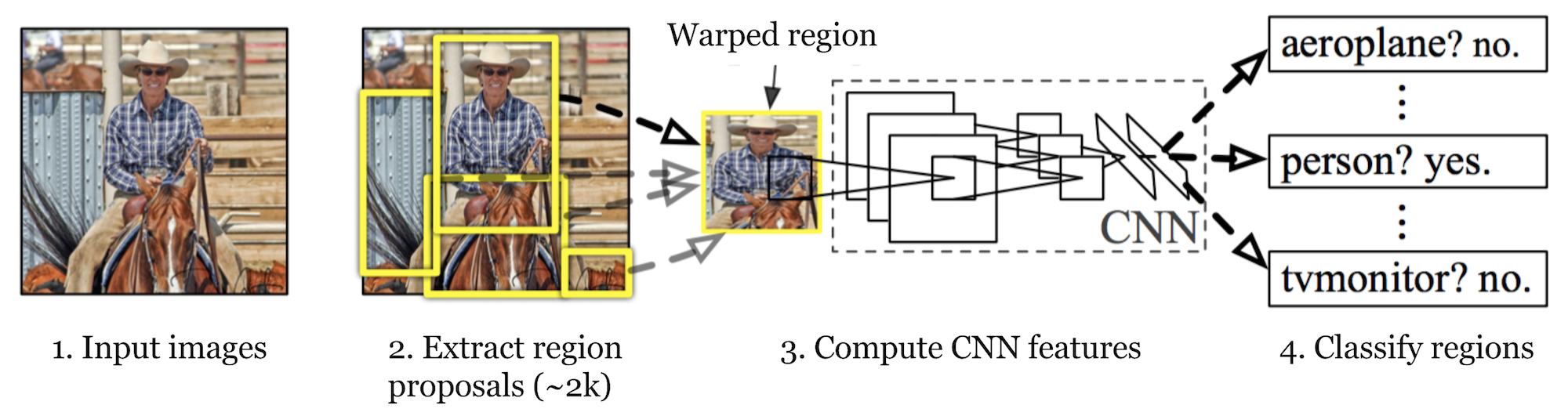
Obr. 1. Architektura R-CNN. (Zdroj obrázku: Girshick et al., 2014)
Model Workflow
Jak R-CNN práce mohou být shrnuty následovně:
- Pre-train CNN sítě na klasifikaci snímku úkoly; například, VGG nebo ResNet vyškoleni na ImageNet dataset. Klasifikační úkol zahrnuje n třídy.
poznámka: pre-vyškolený AlexNet najdete v Caffe Model Zoo. Nemyslím si, že ji najdete v Tensorflow, ale Tensorflow-slim model library poskytuje předem vyškolený ResNet, VGG a další.
- Navrhnout kategorie-nezávislé regiony zájmu o selektivní vyhledávání (~2k kandidátů na obrázku). Tyto oblasti mohou obsahovat cílové objekty a mají různé velikosti.
- krajští kandidáti jsou pokřiveni, aby měli pevnou velikost, jak požaduje CNN.
- pokračujte v dolaďování CNN na deformovaných regionech pro třídy K + 1; další třída odkazuje na pozadí (žádný předmět zájmu). Ve fázi jemného doladění bychom měli použít mnohem menší míru učení a mini-šarže přebírá pozitivní případy, protože většina navrhovaných regionů je jen pozadí.
- vzhledem ke každé oblasti obrazu generuje jedno dopředné šíření prostřednictvím CNN vektorový prvek. Tento vektor funkcí je pak spotřebován binárním SVM vyškoleným pro každou třídu nezávisle.
pozitivní vzorky jsou navrhované regiony s IoU (průnik přes unii) překrývají práh >= 0,3, a negativní vzorky jsou irelevantní ostatní. - Chcete-li snížit chyby lokalizace, regresní model je vyškolen k opravě předpokládaného detekčního okna na korekčním offsetu ohraničujícího pole pomocí funkcí CNN.
Vymezovací Rámeček Regrese
Vzhledem k předpokládané vymezovacího rámečku souřadnicové \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (střed souřadnic, šířka, výška) a jeho odpovídající pozemní pravdy box souřadnice \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , na regressor je nakonfigurován tak, aby učit scale-invariantní transformace mezi dvěma center a log-transformace mezi šířek a výšek. Všechny transformační funkce berou jako vstup \(\mathbf{p}\).
\
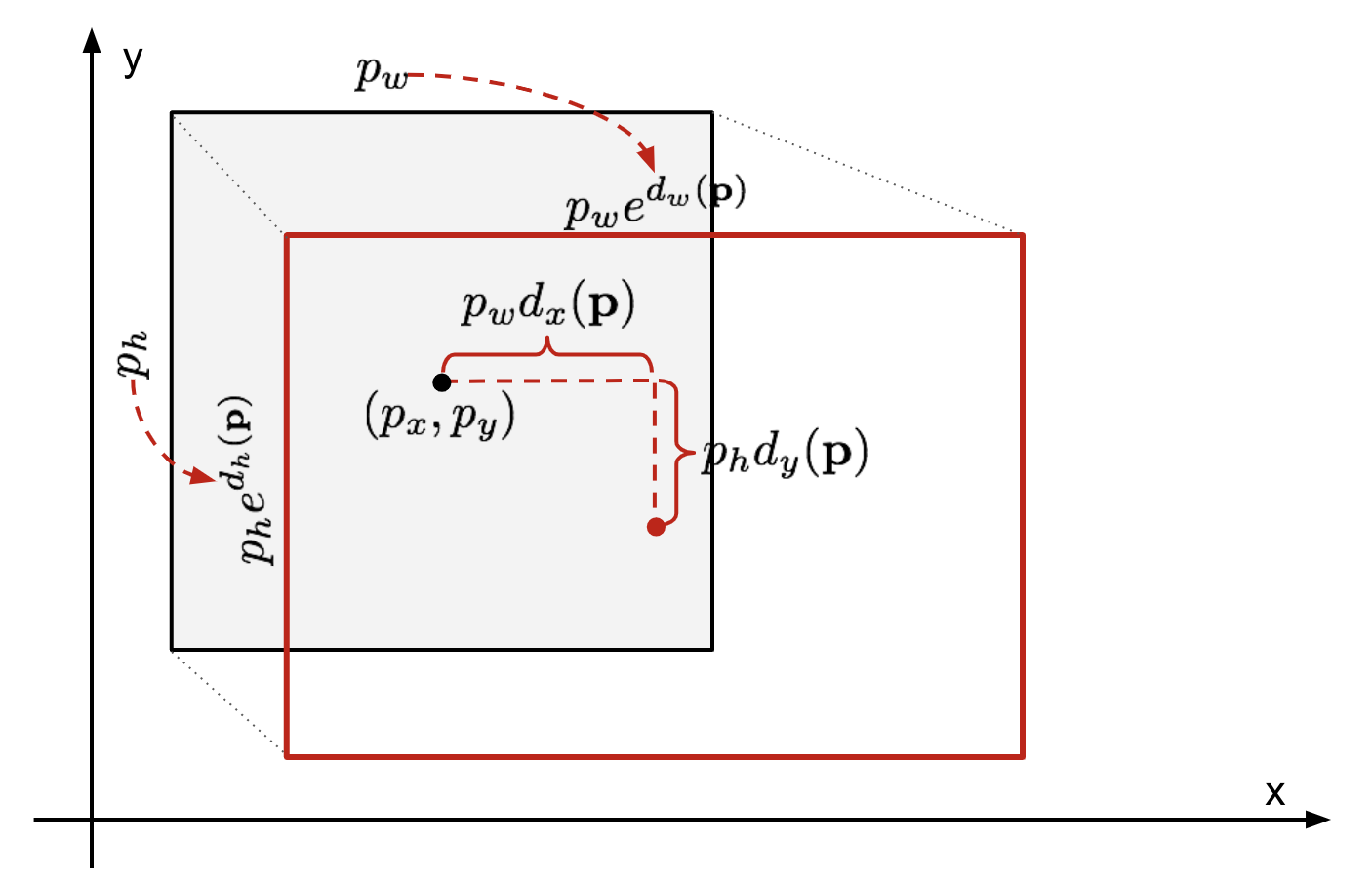
Obr. 2. Ilustrace transformace mezi předpověděl a pozemní pravdu bounding boxy.
zřejmý přínos z použití takové transformace je, že všechny vymezovacího rámečku korekční funkce, \(d_i(\mathbf{p})\), kde \(i \in \{ x, y, w, h \}\), může mít jakoukoliv hodnotu mezi . Cíle pro ně se učit, jsou:
\
standardní regresní model může vyřešit problém tím, že minimalizuje SSE ztrátou s regularizace:
\
regularizace termín je zde zásadní a RCNN papíru vybral nejlepší λ pomocí křížové validace. Je také pozoruhodné, že ne všechny předpokládané ohraničující boxy mají odpovídající uzemňovací krabice. Pokud například nedochází k překrývání, nemá smysl spouštět regresi bbox. Zde je pro trénink regresního modelu bbox uchováván pouze předpovězený box s blízkým pozemním boxem s alespoň 0,6 IoU.
běžné triky
několik triků se běžně používá v rcnn a dalších detekčních modelech.
Non-maximální potlačení
pravděpodobně model je schopen najít více ohraničujících polí pro stejný objekt. Potlačení Non-max pomáhá zabránit opakované detekci stejné instance. Poté, co dostaneme sadu odpovídajících ohraničujících polí pro stejnou kategorii objektů: Seřadit všechny ohraničující políčka podle skóre spolehlivosti.Zlikvidujte krabice s nízkým skóre spolehlivosti.I když existuje zbývající ohraničující rámeček, opakujte následující:lačně vyberte ten s nejvyšším skóre.Přeskočte zbývající pole s vysokým IoU (tj. > 0.5) s dříve vybraným.

Obr. 3. Více ohraničujících polí detekuje auto na obrázku. Po non-maximální potlačení, jen ty nejlepší zbytky a zbytek jsou ignorovány, protože mají velké přesahy s vybraným. (Zdroj obrázku: papír DPM)
tvrdá negativní těžba
považujeme ohraničující krabice bez objektů za negativní příklady. Ne všechny negativní příklady lze stejně těžko identifikovat. Například, pokud je drží čisté prázdné pozadí, je pravděpodobné, že „snadné negativní“, ale pokud pole obsahuje divně hlučný textury nebo částečný objekt, mohlo by to být těžké být uznána a tyto jsou „tvrdé negativní“.
tvrdé negativní příklady lze snadno špatně klasifikovat. Tyto falešně pozitivní vzorky můžeme explicitně najít během tréninkových smyček a zahrnout je do tréninkových údajů, abychom zlepšili klasifikátor.
Rychlost Zúžení
při Pohledu přes R-CNN učení kroků, můžete snadno zjistit, že školení R-CNN model je drahé a pomalé, jako následující kroky zahrnují spoustu práce:
- Systémem selektivní vyhledávání navrhnout 2000 regionu kandidáty pro každý obraz;
- Generování CNN funkci vektor pro každý obraz regionu (N obrázky * 2000).
- celý proces zahrnuje tři modely samostatně bez větších sdílené výpočty: konvoluční neuronové sítě pro klasifikaci snímku a funkce extrakce; horní SVM klasifikátor pro identifikaci cílové objekty; a regresní model pro utahování regionu bounding boxy.
Fast R-CNN
, Aby se R-CNN rychleji, Girshick (2015) lepší postup výcviku sjednocením tří samostatných modelů do jednoho společně vyškoleni rámce a rostoucí sdílené výpočty výsledky, pojmenovaný Fast R-CNN. Namísto extrahování vektorů funkcí CNN nezávisle pro každý návrh regionu, tento model je agreguje do jednoho průchodu CNN vpřed přes celý obrázek a návrhy regionů sdílejí tuto matici funkcí. Pak je stejná matice funkcí rozvětvena, aby byla použita pro učení klasifikátoru objektů a regresoru ohraničujícího pole. Závěrem lze říci, že sdílení výpočtů urychluje R-CNN.
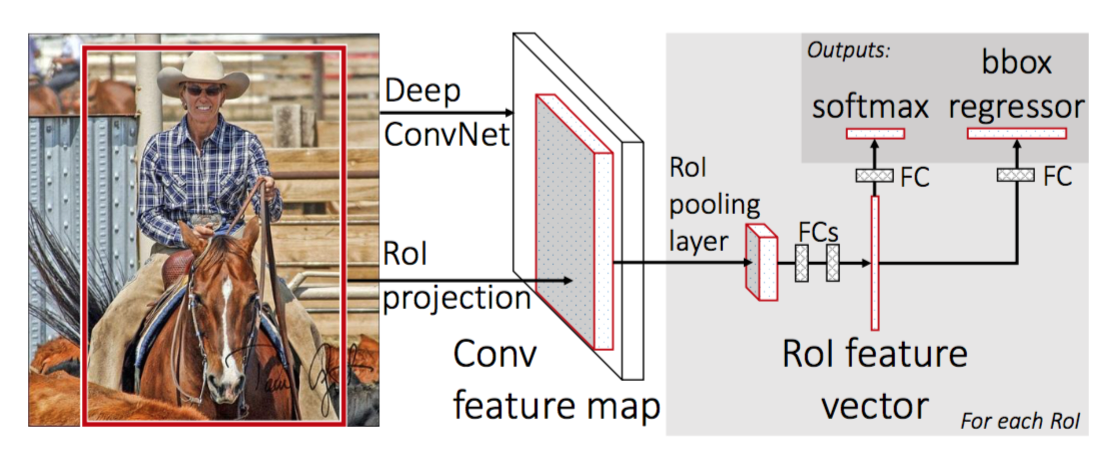
Obr. 4. Architektura rychlého R-CNN. (Zdroj obrázku: Girshick, 2015)
RoI Sdružování
To je typ max sdružování převést funkce v předpokládané oblasti obrázek libovolné velikosti, h x w, do malé pevné okno, H x W vstupní oblast je rozdělena do H x W sítí, přibližně každé podokno velikosti h/H x w/W. Pak platí max-pooling v každé mřížce.
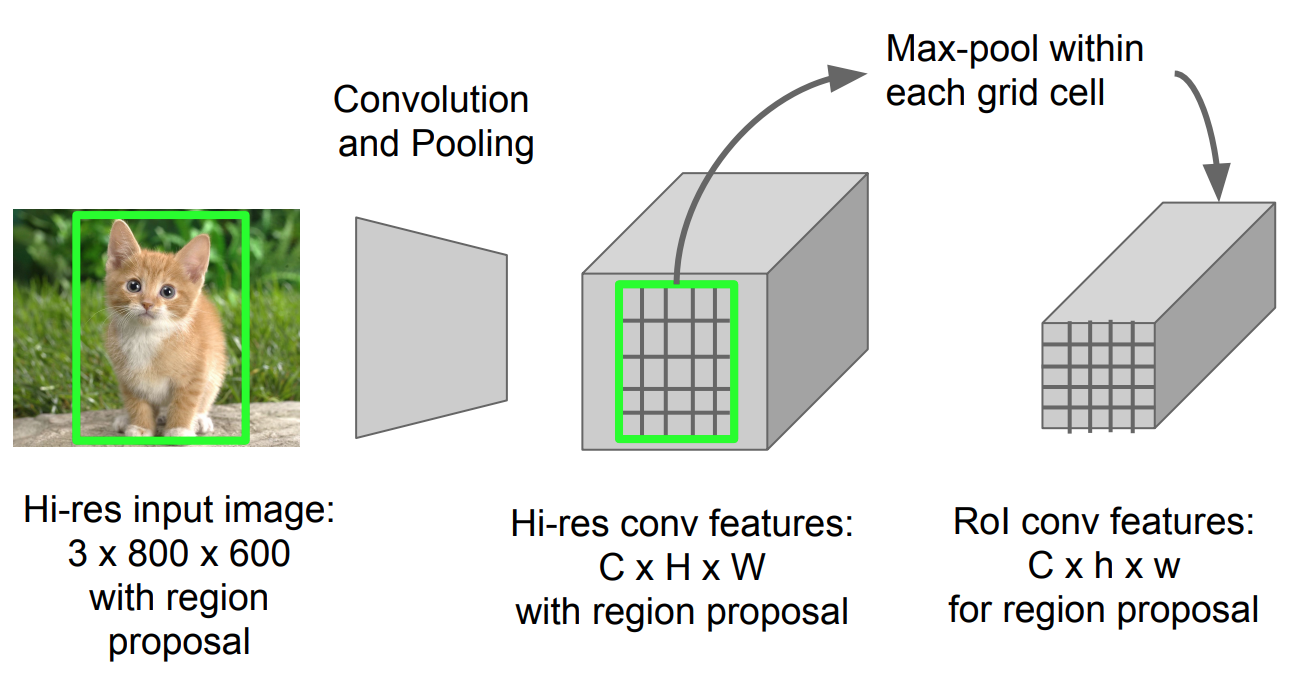
Obr. 5. RoI pooling (Zdroj obrázku: Stanford CS231n slides.
Model Workflow
Jak rychle funguje R-CNN je shrnuto následovně; mnoho kroků je stejných jako v R-CNN:
- nejprve předcvičte konvoluční neuronovou síť na úlohách klasifikace obrazu.
- Navrhněte regiony selektivním vyhledáváním (~2k kandidátů na obrázek).
- Alter the pre-trained CNN:
- nahraďte Poslední max pooling vrstvu pre-trained CNN s RoI pooling vrstvou. Sdružovací vrstva RoI vytváří vektory regionálních návrhů s pevnou délkou. Sdílení výpočtu CNN má velký smysl, protože mnoho regionálních návrhů stejných obrázků se velmi překrývá.
- nahraďte Poslední plně připojenou vrstvu a poslední vrstvu softmax (třídy k) plně připojenou vrstvou a softmax přes třídy K + 1.
- Nakonec model větví do dvou výstupních vrstev:
- softmax odhad K + 1 tříd (stejné jako u R-CNN, +1 je „pozadí“ třídy), výstup diskrétní rozdělení pravděpodobnosti za RoI.
- regresní model ohraničujícího pole, který předpovídá offsety vzhledem k původní návratnosti investic pro každou z tříd K.
Ztráta Funkce
model je optimalizován pro ztrátu spojení dvou úkolů (klasifikace + lokalizace):
| Symbol | Vysvětlení |
| \(u\) | True třídy label, \(u \u 0, 1, \dots, K\); podle konvence, catch-all pozadí třídy má \(u = 0\). |
| \(p\) | Diskrétní rozdělení pravděpodobnosti (za RoI) přes K + 1 tříd: \(p = (p_0, \dots, p_K)\), vypočtené pomocí softmax přes K + 1 výstupy plně propojené vrstvy. |
| \(v\) | Pravý vymezovací rámeček \(v = (v_x, v_y, v_w, v_h)\). |
| \(t^u\) | předpokládaná korekce ohraničujícího pole, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Viz výše. |
ztráta funkce shrnuje náklady na klasifikaci a vymezovací rámeček předpověď: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box}\). Pro“ background “ RoI je \(\mathcal{L}_\ text{box}\) ignorován funkcí indikátoru \(\mathbb{1} \), definovanou jako:
\ = \begin{případů} 1 & \text{pokud } u \geq 1\\ 0 & \text{jinak}\end{případů}\]
celková ztráta funkce je:
\ \mathcal{L}_\text{box}(t^u, v) \\\mathcal{L}_\text{cls}(p, u) &= -\log p_u \\\mathcal{L}_\text{box}(t^u, v) &= \sum_{i \in \{x, y, w, h\}} L_1^\text{hladké} (t^u_i – v_i)\end{align*}\]
vymezovací rámeček ztrátu \(\mathcal{L}_{box}\) by měly měřit rozdíl mezi \(t^u_i\) a \(v_i\) pomocí robustní ztráta funkce. Hladká ztráta L1 je zde přijata a tvrdí se, že je méně citlivá na odlehlé hodnoty.
\
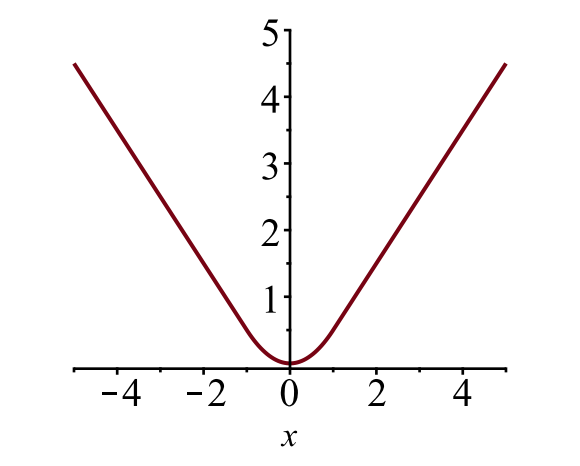
Obr. 6. Graf hladké ztráty L1, \(y = L_1^\text{smooth} (x)\). (Zdroj obrázku: odkaz)
rychlostní překážka
Fast R-CNN je mnohem rychlejší jak v tréninku, tak v době testování. Zlepšení však není dramatické, protože návrhy regionů jsou generovány Samostatně jiným modelem a to je velmi drahé.
rychlejší R-CNN
intuitivním řešením zrychlení je integrace algoritmu návrhu regionu do modelu CNN. Faster R-CNN (Ren et al., 2016) dělá přesně toto: postavit jediný, jednotný model složený z RPN (region proposal network) a rychlé R-CNN se sdílenými konvolučními vrstvami funkcí.

Obr. 7. Ukázka rychlejšího modelu R-CNN. (Zdroj obrázku: Ren et al., 2016)
Model Workflow
- Pre-train sítě CNN o úlohách klasifikace obrazu.
- doladit RPN (region proposal network) end-to-end pro úkol region proposal, který je inicializován pomocí pre-train image classifier. Pozitivní vzorky mají IoU (intersection-over-union) > 0.7, zatímco negativní vzorky mají IoU < 0.3.
- posuňte malé prostorové okno n x n nad mapu funkcí conv celého obrázku.
- ve středu každého posuvného okna předpovídáme více oblastí různých měřítek a poměrů současně. Kotva je kombinací (posuvné okno Centrum, měřítko, poměr). Například 3 stupnice + 3 poměry => k=9 kotev v každé posuvné poloze.
- trénujte rychlý model detekce objektů R-CNN pomocí návrhů generovaných současným RPN
- poté použijte rychlou síť R-CNN k inicializaci školení RPN. Při zachování sdílených konvolučních vrstev doladěte pouze vrstvy specifické pro RPN. V této fázi mají RPN a detekční síť sdílené konvoluční vrstvy!
- konečně doladit jedinečné vrstvy Fast R-CNN
- krok 4-5 lze opakovat trénovat RPN a rychlé R-CNN alternativně v případě potřeby.
ztrátová funkce
rychlejší R-CNN je optimalizována pro funkci ztráty více úkolů, podobně jako rychlá R-CNN.
| Symbol | Vysvětlení |
| \(p_i\) | Předpovídal pravděpodobnost kotvu jsem být objekt. |
| \(p^ * _i\) | základní označení pravdy (binární) o tom, zda je kotva I objektem. |
| \(t_i\) | předpověděl čtyři parametrizované souřadnice. |
| \(t^ * _i\) | souřadnice pozemních pravd. |
| \(N_ \ text{cls}\) | normalizační termín, nastavený na velikost mini-šarže (~256) v papíru. |
| \(N_\text{box}\) | období Normalizace, nastavit počet kotevních míst (~2400) v novinách. |
| \(\lambda\) | vyvážení parametr nastaven na ~10 v novinách (tak, že jak \(\mathcal{L}_\text{cls}\) a \(\mathcal{L}_\text{box}\) jsou podmínky zhruba se stejnou váhou). |
multi-task ztráta funkce kombinuje ztráty, klasifikace a vymezovací rámeček regrese:
\
, kde \(\mathcal{L}_\text{cls}\) je log ztráta funkce více než dvou tříd, jak můžeme snadno přeložit multi-třídy klasifikace do binární klasifikace tím, že předpovídá vzorek byl cílový objekt versus ne. \(L_1^\text{smooth}\) je hladká ztráta L1.
\
Mask R-CNN
Mask R-CNN (He et al., 2017) rozšiřuje rychlejší R-CNN na segmentaci obrazu na úrovni pixelů. Klíčovým bodem je oddělit klasifikaci a úkoly predikce masky na úrovni pixelů. Na základě rámce rychlejší R-CNN přidala třetí větev pro předpovídání masky objektu paralelně se stávajícími větvemi pro klasifikaci a lokalizaci. Větev masky je malá plně připojená síť aplikovaná na každou návratnost investic, předpovídající segmentační masku způsobem pixel-to-pixel.
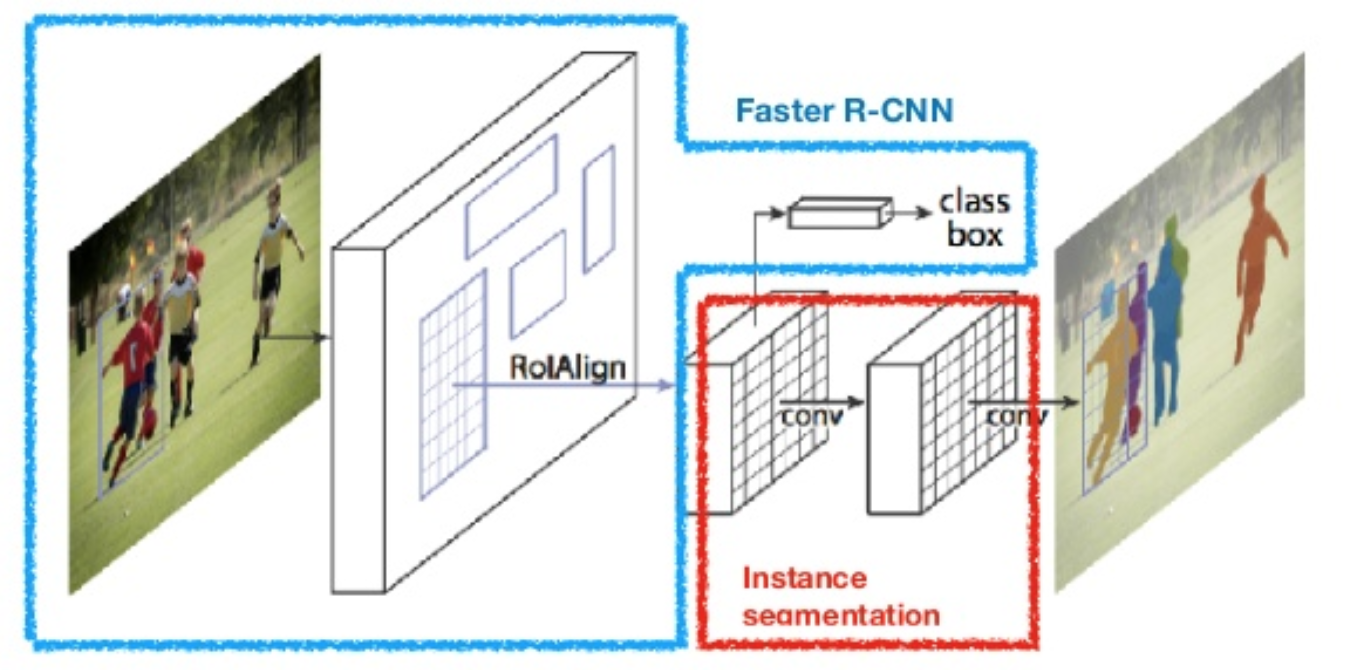
Obr. 8. Maska R-CNN je rychlejší model R-CNN se segmentací obrazu. (Zdroj obrázku: on et al., 2017)
Protože pixel-úroveň segmentace vyžaduje mnohem víc jemnozrnné zarovnání než vymezovací rámeček, masku R-CNN zlepšuje Návratnost investic sdružování vrstvu (s názvem „RoIAlign vrstva“) tak, že Návratnost investic může být lépe a přesněji mapován do oblasti původního obrazu.

Obr. 9. Předpovědi podle masky R-CNN na testovací sadě COCO. (Zdroj obrázku: on et al., 2017)
RoIAlign
vrstva RoIAlign je navržena tak, aby opravila nesouosost umístění způsobenou kvantizací ve sdružování RoI. RoIAlign odstraní hašovací kvantizaci, například použitím x / 16 namísto, takže extrahované funkce mohou být správně zarovnány se vstupními pixely. Bilineární interpolace se používá pro výpočet hodnot umístění s plovoucí desetinnou čárkou ve vstupu.
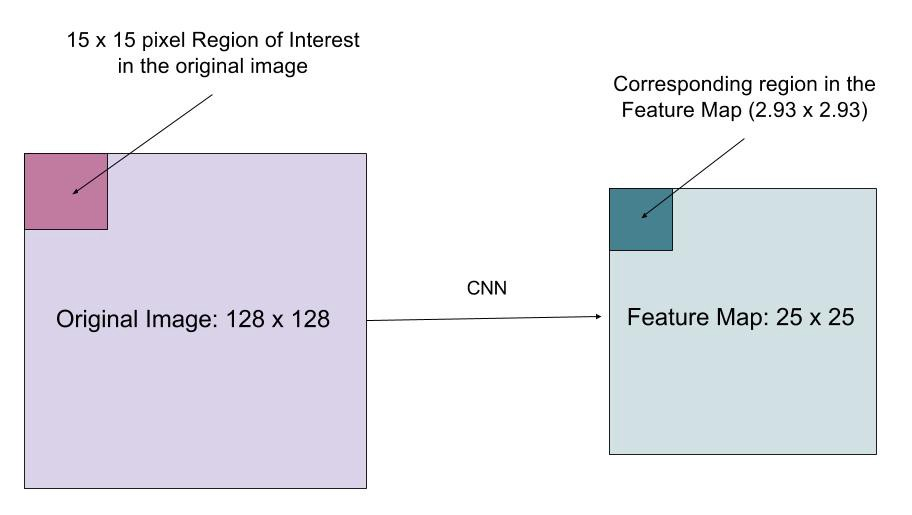
Obr. 10. Oblast zájmu je mapována přesně z původního obrázku na mapu funkcí bez zaokrouhlení na celá čísla. (Zdroj obrázku: odkaz)
Ztráta Funkce
multi-task ztráta funkce Maska R-CNN kombinuje ztrátu klasifikace, lokalizace a segmentace maska: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box} + \mathcal{L}_\text{maska}\), kde \(\mathcal{L}_\text{cls}\) a \(\mathcal{L}_\text{box}\) jsou stejné jako v Rychlejší R-CNN.
větev masky generuje masku o rozměru m x m pro každou návratnost investic a každou třídu; celkem třídy K. Celkový výstup má tedy velikost \(K \ cdot m^2\). Protože se model snaží naučit masku pro každou třídu, mezi třídami neexistuje konkurence pro generování masek.
\(\mathcal{L}_\text{maska}\) je definována jako průměrná binární cross-entropy ztráty, pouze včetně k-tého masku v případě, že oblast je spojena s pozemní pravdu třídy k.
\\]
, kde \(y_{ij}\) je označení buňky (i, j) v pravém maska pro region o velikosti m x m; \(\hat{y}_{ij}^k\) je předpokládaná hodnota stejné buňky v masce se naučil na zemi-pravdu třídy k.
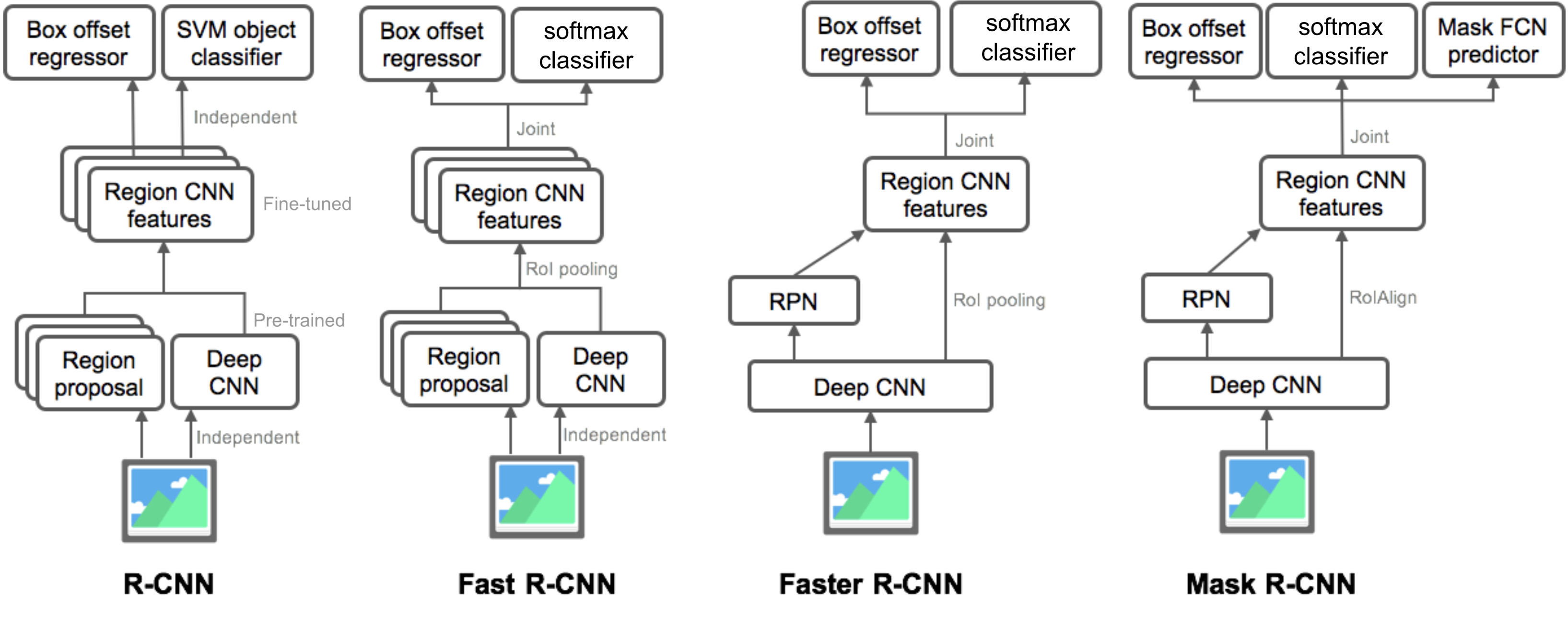
souhrn modelů z rodiny R-CNN
zde ilustruji modely R-CNN, Fast R-CNN, Faster R-CNN a Mask R-CNN. Porovnáním malých rozdílů můžete sledovat, jak se jeden model vyvíjí na další verzi.
Citováno jako:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}Odkaz
Ross Girshick, Jeff Donahue, Trevor Darrell, a Jitendra Malik. „Bohaté hierarchie funkcí pro přesnou detekci objektů a sémantickou segmentaci.“V Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), PP.580-587. 2014.
Ross Girshick. „Rychlá R-CNN.“V Proc. IEEE Intl. Conf. o počítačovém vidění, s. 1440-1448. 2015.
Shaoqing Ren, Kaiming He, Ross Girshick a Jian Sun. „Rychlejší R-CNN: směrem k detekci objektů v reálném čase pomocí sítí regionálních návrhů.“In Advances in neural information processing systems (NIPS), PP.91-99. 2015.
Kaiming He, Georgia Gkioxari, Piotr Dollár a Ross Girshick. „Maska R-CNN.“arXiv předtisk arXiv: 1703.06870, 2017.
Joseph Redmon, Santosh Divvala, Ross Girshick a Ali Farhadi. „Podíváte se pouze jednou: sjednocená detekce objektů v reálném čase.“V Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), PP.779-788. 2016.
„Stručná historie CNN v segmentaci obrazu: od R-CNN po masku R-CNN“ od Athelas.
hladká ztráta L1: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf