Regresní Stromy
Všechny regresní techniky obsahují jeden výstup (odezva) variabilní a jeden nebo více vstupních (prediktor) proměnných. Výstupní proměnná je číselná. Obecná metodika vytváření regresních stromů umožňuje, aby vstupní proměnné byly směsí spojitých a kategorických proměnných. Rozhodovací strom je generován, když každý rozhodovací uzel ve stromu obsahuje test na hodnotě nějaké vstupní proměnné. Koncové uzly stromu obsahují předpokládané hodnoty výstupní proměnné.
Regresní strom mohou být považovány jako varianta, rozhodovací stromy, jejichž cílem je přiblížit skutečný-oceněný funkce, místo toho, aby použili pro klasifikaci metod.
Metodika
regresní strom je postaven přes proces známý jako binární rekurzivní dělení, které je iterativní proces, který rozdělí data do oddílů nebo větve, a pak pokračuje v rozdělení každého oddílu na menší skupiny jako metoda pohybuje nahoru každé pobočce.
zpočátku jsou všechny záznamy v tréninkové sadě (předem klasifikované záznamy, které se používají k určení struktury stromu) seskupeny do stejného oddílu. Algoritmus pak začne přidělovat data do prvních dvou oddílů nebo větví, pomocí každého možného binárního rozdělení na každém poli. Algoritmus vybere rozdělení, které minimalizuje součet čtvercových odchylek od průměru ve dvou samostatných oddílech. Toto pravidlo rozdělení se pak použije na každou z nových větví. Tento proces pokračuje, dokud každý uzel nedosáhne uživatelem zadané minimální velikosti uzlu a nestane se koncovým uzlem. (Pokud je součet čtvercových odchylek od průměru v uzlu nulový, pak je tento uzel považován za koncový uzel, i když nedosáhl minimální velikosti.)
Prořezávání Stromu
Protože strom se pěstuje z trénovací množiny, plně vyvinutý strom obvykle trpí over-fitting (tedy, je to vysvětlení náhodných prvků z trénovací množiny, které nejsou pravděpodobné, že bude funkcí větší počet obyvatel). Toto nadměrné přizpůsobení má za následek špatný výkon v reálných datech. Proto musí být strom ořezán pomocí ověřovací sady. XLMiner vypočítá faktor složitosti nákladů v každém kroku během růstu stromu a rozhodne o počtu rozhodovacích uzlů v prořezaném stromu. Faktor složitosti nákladů je multiplikativní faktor, který se aplikuje na velikost stromu (měřeno počtem terminálních uzlů).
strom je stříhat, aby se minimalizovalo součet: 1) výstupní proměnné rozptyl v ověřování údajů, vzít jeden terminál uzlu v čase; a 2) produkt na náklady, složitost faktor a počet koncových uzlů. Pokud je faktor složitosti nákladů specifikován jako nula,pak prořezávání jednoduše najde strom, který nejlépe funguje na validačních datech, pokud jde o celkový rozptyl terminálních uzlů. Větší hodnoty faktoru složitosti nákladů vedou k menším stromům. Prořezávání se provádí na základě last – in first-out, což znamená, že poslední pěstovaný uzel je první, který podléhá eliminaci.
Ensemble Methods
XLMiner v2015 nabízí tři výkonné metody ensemble pro použití s regresními stromy: pytlování (agregace bootstrap), posilování a náhodné stromy. Algoritmus regresního stromu lze použít k nalezení jednoho modelu, který má za následek dobré předpovědi pro nová data. Můžeme zobrazit statistiky a matrice zmatku současného prediktoru, abychom zjistili, zda je náš model vhodný k datům; ale jak bychom věděli, zda existuje lepší prediktor, který čeká na nalezení? Odpověď zní, že nevíme, zda existuje lepší prediktor. Ensemble metody nám však umožňují kombinovat více modelů slabých regresních stromů, které společně tvoří nový, přesný, silný regresní stromový model. Tyto metody fungují tak, že vytvářejí více různých regresních modelů, odebírají různé vzorky původní datové sady a poté kombinují jejich výstupy. (Výstupy mohou být kombinovány několika technikami, například většinovým hlasováním pro klasifikaci a průměrováním pro regresi) tato kombinace modelů účinně snižuje rozptyl silného modelu. Tři typy metod ensemble nabízené v XLMiner (pytlování, posilování a náhodné stromy) se liší ve třech položkách: 1) Výběr tréninkové sady pro každý prediktor nebo slabý model; 2) Jak jsou generovány slabé modely; a 3) Jak jsou výstupy kombinovány. Ve všech třech metodách je každý slabý model vyškolen na celé tréninkové sadě, aby se stal zdatným v určité části datové sady.
pytlování (bootstrap aggregating) byl jeden z prvních algoritmů souboru, který byl kdy napsán. Je to jednoduchý algoritmus, ale velmi efektivní. Pytlování generuje několik tréninkových Množin pomocí náhodného výběru s opakováním (bootstrapu), platí regresní strom algoritmus pro každý soubor dat, pak se bere průměr mezi modely pro výpočet předpovědi pro nová data. Největší výhodou pytlování je relativní snadnost, že algoritmus lze paralelizovat, což je lepší volba pro velmi velké datové sady.
Zvýšení staví silný model postupně vzdělávacích modelů, soustředit se na záznamy dostávají nepřesné předpokládané hodnoty u předchozích modelů. Po dokončení jsou všechny prediktory kombinovány váženým většinovým hlasováním. XLMiner nabízí tři varianty posílení implementované algoritmem AdaBoost (jeden z nejpopulárnějších algoritmů souboru, který se dnes používá): M1 (Freund), M1 (Breiman), a MOHU (Stagewise Aditivní Modelování, pomocí Multi-class Exponenciální).
AdaBoost.M1 nejprve přiřadí váhu (wb (i)) každému záznamu nebo pozorování. Tato váha je původně nastavena na hodnotu 1 / n A bude aktualizována při každé iteraci algoritmu. Původní regresní strom je vytvořen pomocí tohoto prvního Školení Set (Tb) a chyba se vypočítá jako
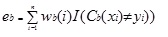
kde, I() vrací 1, pokud je pravdivý a 0 pokud ne.
chyba regresního stromu v iteraci bth se používá k výpočtu konstanty ?b. Tato konstanta se používá k aktualizaci hmotnosti (wb (i). V Adaboostu.M1 (Freund), konstanta se vypočítá jako
ab= ln ((1-eb)/eb)
V AdaBoost.M1 (Breiman), konstanta se vypočítá jako
ab= 1/2ln((1-eb)/eb)
V SAMÝ, konstanta se vypočítá jako
ab= 1/2ln((1-eb)/eb + ln(k-1), kde k je počet tříd
kde, počet kategorií se rovná 2, MOHU se chová stejně jako AdaBoost Breiman.
V každém ze tří provedení (Freund, Breiman, nebo MOHU), nová váha pro (b + 1)th iterace bude

Poté, váhy jsou upravovány, aby součet 1. Jako výsledek, váhy přiřazené pozorováním, kterým byly přiřazeny nepřesné předpovězené hodnoty, se zvýší, a váhy přiřazené pozorováním, kterým byly přiřazeny přesné předpovězené hodnoty, se sníží. Tato úprava nutí další regresní model klást větší důraz na záznamy, kterým byly přiřazeny nepřesné předpovědi. (Tohle ? konstanta se také používá v konečném výpočtu, což dá regresnímu modelu s NEJNIŽŠÍ chybou větší vliv.) Tento proces se opakuje, dokud b = počet slabých žáků. Algoritmus pak vypočítá vážený průměr mezi všemi slabými studenty a přiřadí tuto hodnotu záznamu. Posílení obecně přináší lepší modely než pytlování; má však nevýhodu, protože není rovnoběžné. V důsledku toho, pokud je počet slabých studentů velký, posílení by nebylo vhodné.
metoda náhodných stromů (náhodné lesy) je variací pytlování. Tato metoda funguje tak, že vzdělávání více slabý regresní stromy pomocí pevného počtu náhodně vybraných funkcí (sqrt pro klasifikaci a řadu funkcí/3 pro predikci), pak se bere průměrná hodnota pro slabé žáky a přiřadí tuto hodnotu na silný prediktor. Obvykle se počet generovaných slabých stromů může pohybovat od několika set do několika tisíc v závislosti na velikosti a obtížnosti tréninkové sady. Náhodné stromy jsou rovnoběžné, protože jsou variantou pytlování. Nicméně, protože tandom trees vybírá omezené množství funkcí v každé iteraci, výkon náhodných stromů je rychlejší než pytlování.
regresní strom Ensemble metody jsou velmi výkonné metody, a obvykle za následek lepší výkon než jeden strom. Tato funkce navíc v XLMiner V2015 poskytuje přesnější modely predikce, a měly by být považovány za metodu jediného stromu.