seznámení s Výztuží Učení prostřednictvím Markovovy Rozhodovací Proces
Tento článek byl publikován jako součást vědeckých Dat Blogathon.
Úvod
Výztuž Učení (RL) je učení metodiky, pomocí níž se žák učí se chovat v interaktivním prostředí s využitím vlastních akcí a odměny pro své akce. Student, často nazývaný agent, zjistí, které akce poskytují maximální odměnu tím, že je využijí a prozkoumají.

klíčovou otázkou je-jak se RL liší od učení pod dohledem a bez dozoru?
rozdíl je v perspektivě interakce. Supervised learning přímo řekne uživateli / agentovi, jakou akci musí provést, aby maximalizoval odměnu pomocí tréninkové datové sady označených příkladů. Na druhou stranu RL přímo umožňuje agentovi využívat odměny (pozitivní a negativní), které si vybere svou akci. Liší se tedy od učení bez dozoru, protože učení bez dozoru je především o hledání struktury skryté ve sbírkách neoznačených dat.
Posílení Učení, Formulace pomocí Markovovy Rozhodovací Proces (MDP)
základní prvky výztuže učení problém, jsou:
- životní Prostředí: vnější svět, s nímž agent interaguje
- Stav: Aktuální situace agent
- Odměna: Numerické signál zpětné vazby z prostředí,
- Podmínky: Metoda na mapě zástupce státu činy. Politika slouží k výběru akce v daném stavu
- Hodnota: Budoucí odměnu (odložená odměna), že agent by dostávat tím, že se akce v daném stavu
Markovovy Rozhodovací Proces (MDP) je matematický rámec k popisu prostředí, v posílení učení. Následující obrázek ukazuje interakci agent-prostředí v MDP:
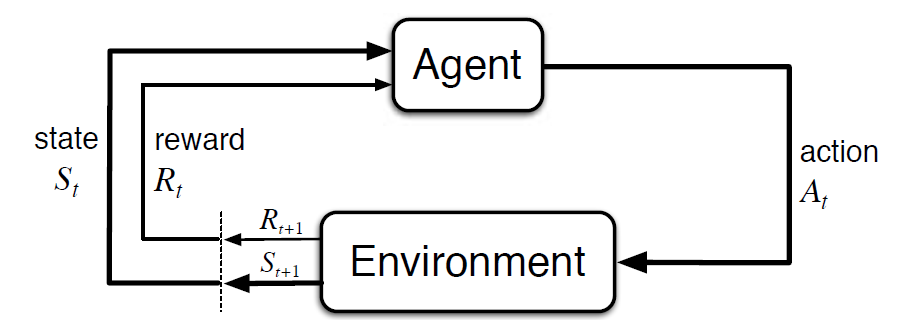
přesněji řečeno, agent a prostředí, komunikovat v každém diskrétním časovém kroku, t = 0, 1, 2, 3…Na každém kroku, agent získá informace o prostředí státu Svatého Založené na prostředí státu, v okamžiku t, agent vybere akci. V následujícím okamžiku agent také obdrží číselný signál odměny Rt+1. To tedy vede k sekvenci jako S0, A0, R1, S1, A1, R2,…
náhodné proměnné Rt a St mají dobře definované diskrétní rozdělení pravděpodobnosti. Tato rozdělení pravděpodobnosti závisí pouze na předchozím stavu a akci na základě Markovovy vlastnosti. Nechť S, A A R jsou sady stavů, akcí a odměn. Pak pravděpodobnost, že hodnoty St, Rt, a V přijímání hodnot s‘, r a s předchozí stav s je dána tím,
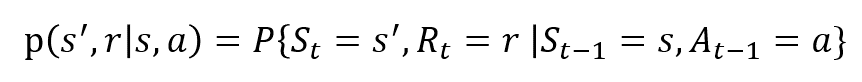
funkce p ovládací prvky dynamiky procesu.
pojďme to pochopit pomocí příkladu
pojďme nyní diskutovat o jednoduchém příkladu, kde lze RL použít k implementaci řídicí strategie pro proces ohřevu.
cílem je řídit teplotu místnosti v rámci stanovených teplotních limitů. Teplota uvnitř místnosti je ovlivněna vnějšími faktory, jako je venkovní teplota, generované vnitřní teplo atd.
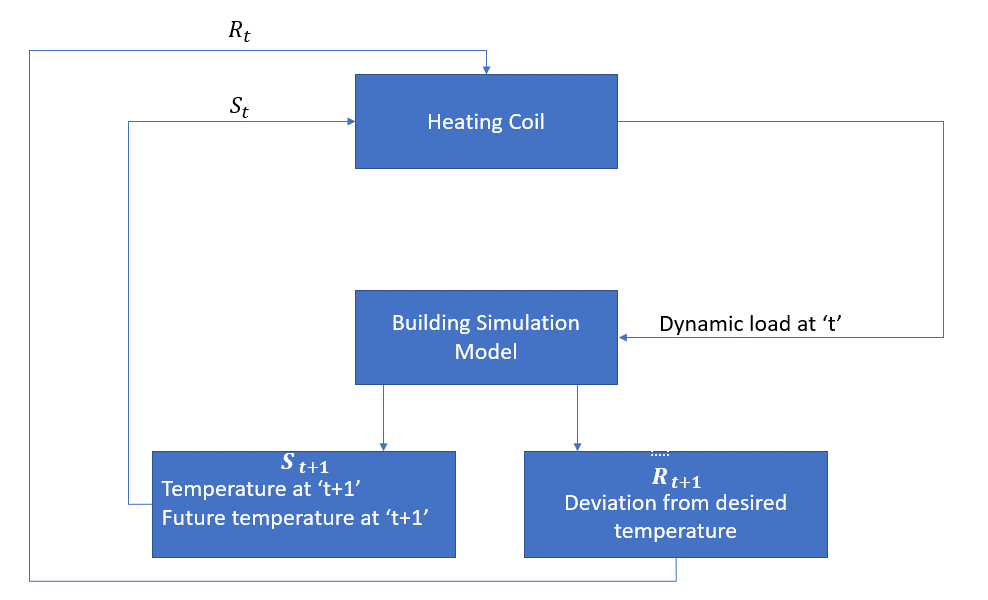
agent, v tomto případě, je ohřívací cívka, která má rozhodnout o množství tepla potřebné k regulaci teploty uvnitř místnosti tím, interakci s prostředím a zajistit, že teplota uvnitř místnosti je ve specifikovaném rozsahu. Odměnou jsou v tomto případě v podstatě náklady zaplacené za odchylku od optimálních teplotních limitů.
akce pro agenta je dynamické zatížení. Toto dynamické zatížení je pak přiváděno do simulátoru místnosti, což je v podstatě model přenosu tepla, který vypočítává teplotu na základě dynamického zatížení. V tomto případě je tedy prostředí simulačním modelem. Státní proměnná St obsahuje současné i budoucí odměny.
následující blokové schéma vysvětluje, jak MDP mohou být použity pro řízení teploty v místnosti:
Omezení této Metody
Výztuž učení učí od státu. Stát je vstup pro tvorbu politiky. Proto by měly být správně uvedeny státní vstupy. Také, jak jsme viděli, existuje více proměnných a dimenzionalita je obrovská. Takže jeho použití pro skutečné fyzické systémy by bylo obtížné!
Další Čtení
vědět více o RL, tyto materiály by mohly být užitečné:
- Posílení Učení: Úvod Richard.S. Sutton a Andrew.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- Video Přednášky Davida Stříbrná k dispozici na YouTube
- https://gym.openai.com/ je sada nástrojů pro další výzkum
můžete Si také přečíst tento článek na naší Mobilní APLIKACE ![]()
