få styr på forstærkning læring via Markov beslutningsproces
denne artikel blev offentliggjort som en del af Data Science Blogathon.
introduktion
forstærkning læring (RL) er en læringsmetode, hvor eleven lærer at opføre sig i et interaktivt miljø ved hjælp af sine egne handlinger og belønninger for sine handlinger. Eleven, ofte kaldet agent, opdager, hvilke handlinger der giver den maksimale belønning ved at udnytte og udforske dem.

et centralt spørgsmål er – hvordan er RL forskellig fra overvåget og uovervåget læring?
forskellen kommer i interaktionsperspektivet. Overvåget læring fortæller brugeren / agenten direkte, hvilken handling han skal udføre for at maksimere belønningen ved hjælp af et træningsdatasæt med mærkede eksempler. På den anden side giver RL direkte agenten mulighed for at gøre brug af belønninger (positive og negative), det får til at vælge sin handling. Det adskiller sig således også fra uovervåget læring, fordi uovervåget læring handler om at finde struktur skjult i samlinger af umærkede data.
forstærkning af Læringsformulering via Markov Decision Process (MDP)
de grundlæggende elementer i et forstærkningsindlæringsproblem er:
- miljø: omverdenen, som agenten interagerer med
- tilstand: agentens nuværende situation
- belønning: numerisk feedbacksignal fra miljøet
- politik: metode til at kortlægge agentens tilstand til handlinger. En politik bruges til at vælge en handling i en given tilstand
- værdi: fremtidig belønning (forsinket belønning), som en agent ville modtage ved at tage en handling i en given tilstand
Markov Decision Process (MDP) er en matematisk ramme til at beskrive et miljø i forstærkningslæring. Følgende figur viser agent – miljø interaktion i MDP:
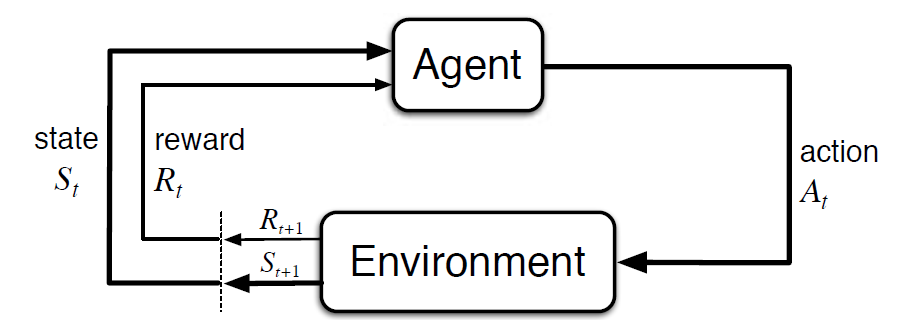
mere specifikt interagerer agenten og miljøet ved hvert diskret tidstrin, t = 0, 1, 2, 3…At hver gang Trin, agenten får oplysninger om miljøtilstanden St .. baseret på miljøtilstanden ved øjeblikkelig t, agenten vælger en handling kl. I det følgende øjeblik modtager agenten også et numerisk belønningssignal Rt + 1. Dette giver således anledning til en sekvens som S0, A0, R1, S1, A1, R2…
de tilfældige variabler Rt og St har veldefinerede diskrete sandsynlighedsfordelinger. Disse sandsynlighedsfordelinger er kun afhængige af den foregående tilstand og handling i kraft af Markov ejendom. Lad S, A og R være sæt af stater, handlinger og belønninger. Derefter er sandsynligheden for, at værdierne for St, Rt og ved at tage værdier s’, r og A med tidligere tilstand S er givet af
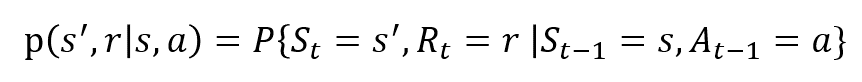
funktionen p styrer dynamikken i processen.
lad os forstå dette ved hjælp af et eksempel
lad os nu diskutere et simpelt eksempel, hvor RL kan bruges til at implementere en kontrolstrategi for en opvarmningsproces.
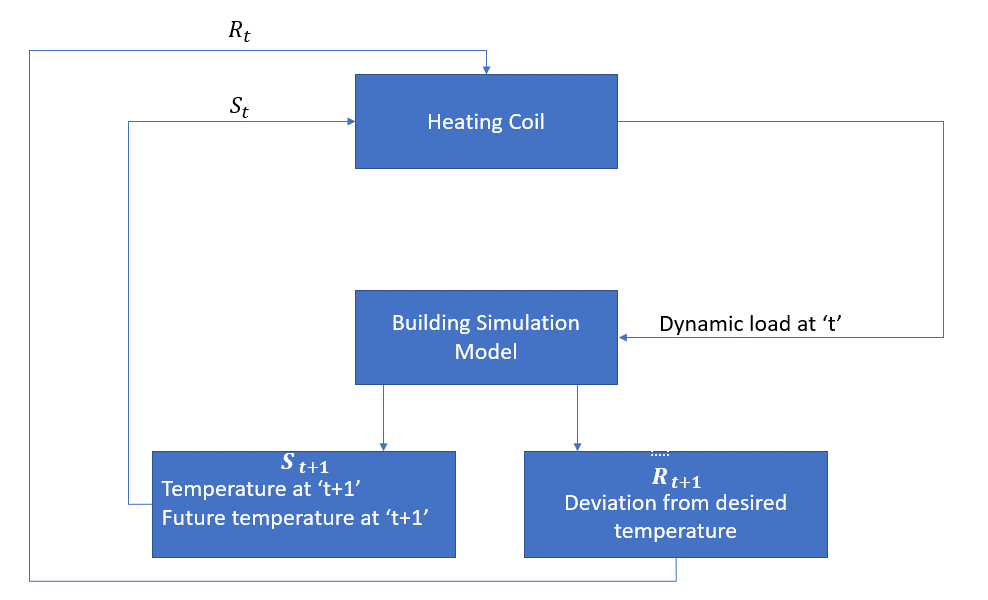
ideen er at kontrollere temperaturen i et rum inden for de angivne temperaturgrænser. Temperaturen inde i rummet påvirkes af eksterne faktorer som udetemperatur, den indre varme, der genereres osv.
midlet er i dette tilfælde varmespolen, der skal bestemme den mængde varme, der kræves for at kontrollere temperaturen inde i rummet ved at interagere med miljøet og sikre, at temperaturen inde i rummet er inden for det specificerede interval. Belønningen er i dette tilfælde dybest set de omkostninger, der betales for at afvige fra de optimale temperaturgrænser.
handlingen for agenten er den dynamiske belastning. Denne dynamiske belastning føres derefter til rumsimulatoren, som dybest set er en varmeoverførselsmodel, der beregner temperaturen baseret på den dynamiske belastning. Så i dette tilfælde er miljøet simuleringsmodellen. Statens variabel St indeholder de nuværende såvel som fremtidige belønninger.
følgende blokdiagram forklarer, hvordan MDP kan bruges til at kontrollere temperaturen inde i et rum:
begrænsninger af denne metode
forstærkning læring lærer af staten. Staten er input til politisk beslutningstagning. Derfor skal statens input gives korrekt. Også som vi har set, er der flere variabler, og dimensionaliteten er enorm. Så det ville være svært at bruge det til rigtige fysiske systemer!
yderligere læsning
for at vide mere om RL kan følgende materialer være nyttige:
- forstærkning læring: En introduktion af Richard.S. Sutton og Andreas.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- videoforelæsninger af David Silver tilgængelig på YouTube
- https://gym.openai.com/ er et værktøjssæt til yderligere udforskning
du kan også læse denne artikel på vores mobilapp ![]()
