De T-Test
De t-test beoordeelt of de gemiddelden van twee groepen statistisch van elkaar verschillen. Deze analyse is geschikt wanneer u de middelen van twee groepen wilt vergelijken, en vooral geschikt als de analyse voor de posttest-only twee-Groep gerandomiseerde experimentele ontwerp.
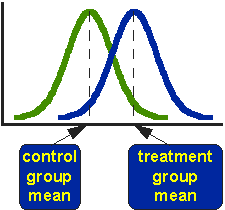
figuur 1. Geïdealiseerde distributies voor behandelde en vergelijking groep posttest waarden.
figuur 1 toont de verdelingen voor de behandelde (blauwe) en controle (groene) groepen in een studie. Eigenlijk toont de figuur de geïdealiseerde distributie-de werkelijke distributie zou meestal worden afgebeeld met een histogram of staafdiagram. De figuur geeft aan waar de middelen van de controlegroep en de behandelingsgroep zich bevinden. De vraag die de t-test adresseert is of de middelen statistisch verschillend zijn.
wat betekent het om te zeggen dat de gemiddelden voor twee groepen statistisch verschillend zijn? Denk aan de drie situaties in Figuur 2. Het eerste wat opvalt aan de drie situaties is dat het verschil tussen de middelen in alle drie hetzelfde is. Maar je moet ook opmerken dat de drie situaties er niet hetzelfde uitzien – ze vertellen heel verschillende verhalen. Het top voorbeeld toont een geval met matige variabiliteit van scores binnen elke groep. De tweede situatie toont de hoge variabiliteit geval. de derde toont het geval met lage variabiliteit. Het is duidelijk dat we concluderen dat de twee groepen het meest verschillend of verschillend lijken in het geval van de bodem of lage variabiliteit. Waarom? Omdat er relatief weinig overlap is tussen de twee klokvormige krommen. In het geval van hoge variabiliteit lijkt het groepsverschil het minst opvallend, omdat de twee klokvormige verdelingen zoveel overlappen.
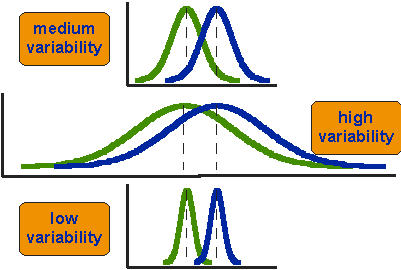
Figuur 2. Drie scenario ‘ s voor verschillen tussen middelen.
Dit leidt ons tot een zeer belangrijke conclusie: wanneer we kijken naar de verschillen tussen scores voor twee groepen, moeten we het verschil tussen hun middelen beoordelen in verhouding tot de spreiding of variabiliteit van hun scores. De t-test doet precies dit.
statistische analyse van de T-test
De formule voor de t-test is een verhouding. Het bovenste deel van de verhouding is gewoon het verschil tussen de twee gemiddelden. Het onderste deel is een maat voor de variabiliteit of spreiding van de scores. Deze formule is in wezen een ander voorbeeld van de signaal-tot-ruis metafoor in het onderzoek: het verschil tussen de middelen is het signaal dat, in dit geval, we denken dat ons programma of behandeling in de gegevens is geïntroduceerd; het onderste deel van de formule is een maat voor variabiliteit die in wezen ruis is die het moeilijker kan maken om het groepsverschil te zien. Figuur 3 toont de formule voor de T-test en hoe de teller en noemer gerelateerd zijn aan de verdelingen.
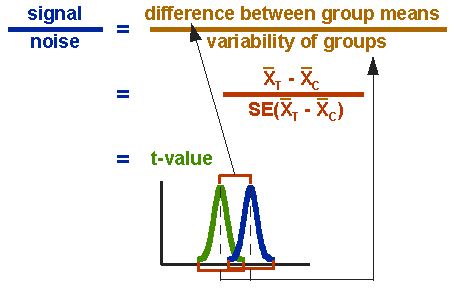
Figuur 3. Formule voor de t-test.
het bovenste deel van de formule is eenvoudig te berekenen – zoek gewoon het verschil tussen de middelen. Het onderste deel wordt de standaardfout van het verschil genoemd. Om het te berekenen nemen we de variantie voor elke groep en delen het door het aantal mensen in die groep. We voegen deze twee waarden toe en nemen dan hun vierkantswortel. De specifieke formule voor de standaardfout van het verschil tussen de middelen is::
$$ \ texttrm{SE} (\bar{X}_T-\bar{X}_C) = \sqrt {\frac {\texttrm{var}_T}{n_T}+\frac {\texttrm{var}_C}{n_C}}$$
onthoud dat de variantie gewoon het kwadraat van de standaardafwijking is.
de uiteindelijke formule voor de t-test is:
$$t = \frac{\bar{X}_T-\bar{X}_C}{\sqrt{\frac{\texttrm{var}_T}{n_T}+\frac{\texttrm{var}_C}{n_C}}}$$
de t-waarde wordt positief als het eerste gemiddelde groter is dan het tweede en negatief als het kleiner is. Zodra u de t-waarde berekent, moet u deze opzoeken in een significantietabel om te testen of de verhouding groot genoeg is om te zeggen dat het verschil tussen de groepen waarschijnlijk geen toevallige bevinding is geweest. Om de significantie te testen, moet u een risiconiveau instellen (het alfa-niveau genoemd). In het meeste sociaal onderzoek is de “vuistregel”om het alfaniveau in te stellen op .05. Dit betekent dat vijf van de honderd keer dat je een statistisch significant verschil tussen de middelen zou vinden, zelfs als er geen (dat wil zeggen, door “toeval”). Je moet ook de vrijheidsgraden (DF) bepalen voor de test. In de t-test is de vrijheidsgraad de som van de personen in beide groepen minus 2. Gegeven het alfaniveau, de df en de t-waarde, kunt u de t-waarde omhoog kijken in een standaard significantietabel (beschikbaar als bijlage in de achterkant van de meeste statistiekteksten) om te bepalen of de t-waarde groot genoeg is om significant te zijn. Als dat zo is, kun je concluderen dat het verschil tussen de middelen voor de twee groepen verschillend is (zelfs gezien de variabiliteit). Gelukkig drukken statistische computerprogramma ‘ s routinematig de resultaten van de significantietest af en besparen ze u de moeite om ze op te zoeken in een tabel.
De T-test, eenrichtingsanalyse van variantie (ANOVA) en een vorm van regressieanalyse zijn wiskundig equivalent (zie de statistische analyse van de alleen na de test gerandomiseerde experimentele opzet) en zouden identieke resultaten opleveren.