Regressionsbäume
Alle Regressionstechniken enthalten eine einzelne Ausgabe- (Antwort-) Variable und eine oder mehrere Eingangsvariablen (Prädiktorvariablen). Die Ausgangsvariable ist numerisch. Die allgemeine Methode zur Erstellung von Regressionsbäumen ermöglicht es, dass Eingabevariablen eine Mischung aus kontinuierlichen und kategorialen Variablen sind. Ein Entscheidungsbaum wird generiert, wenn jeder Entscheidungsknoten im Baum einen Test für den Wert einer Eingabevariablen enthält. Die Endknoten des Baums enthalten die vorhergesagten Werte der Ausgabevariablen. Ein Regressionsbaum kann als eine Variante von Entscheidungsbäumen betrachtet werden, die entworfen wurden, um reellwertige Funktionen zu approximieren, anstatt für Klassifizierungsmethoden verwendet zu werden.
Methodik
Ein Regressionsbaum wird durch einen Prozess erstellt, der als binäre rekursive Partitionierung bekannt ist. Hierbei handelt es sich um einen iterativen Prozess, der die Daten in Partitionen oder Zweige aufteilt und dann jede Partition in kleinere Gruppen aufteilt, während die Methode jeden Zweig nach oben bewegt.
Zunächst werden alle Datensätze im Trainingssatz (vorklassifizierte Datensätze, die zur Bestimmung der Struktur des Baums verwendet werden) in derselben Partition gruppiert. Der Algorithmus beginnt dann mit der Zuweisung der Daten in die ersten beiden Partitionen oder Zweige, wobei jede mögliche binäre Aufteilung für jedes Feld verwendet wird. Der Algorithmus wählt die Aufteilung aus, die die Summe der quadratischen Abweichungen vom Mittelwert in den beiden separaten Partitionen minimiert. Diese Aufteilungsregel wird dann auf jeden der neuen Zweige angewendet. Dieser Vorgang wird fortgesetzt, bis jeder Knoten eine benutzerdefinierte Mindestknotengröße erreicht und zu einem Terminalknoten wird. (Wenn die Summe der quadratischen Abweichungen vom Mittelwert in einem Knoten Null ist, wird dieser Knoten als Endknoten betrachtet, auch wenn er die Mindestgröße nicht erreicht hat.)
Den Baum beschneiden
Da der Baum aus dem Trainingssatz gewachsen ist, leidet ein voll entwickelter Baum typischerweise unter einer Überanpassung (dh es werden zufällige Elemente des Trainingssatzes erklärt, die wahrscheinlich nicht Merkmale der größeren Population sind). Diese Überanpassung führt zu einer schlechten Leistung bei realen Daten. Daher muss der Baum mit dem Validierungssatz beschnitten werden. XLMiner berechnet den Kostenkomplexitätsfaktor bei jedem Schritt während des Wachstums des Baumes und entscheidet über die Anzahl der Entscheidungsknoten im beschnittenen Baum. Der Kostenkomplexitätsfaktor ist der multiplikative Faktor, der auf die Größe des Baums angewendet wird (gemessen an der Anzahl der Endknoten).
Der Baum wird beschnitten, um die Summe zu minimieren aus: 1) der Varianz der Ausgabevariablen in den Validierungsdaten, die jeweils von einem Endknoten genommen werden; und 2) das Produkt aus dem Kostenkomplexitätsfaktor und der Anzahl der Endknoten. Wenn der Kostenkomplexitätsfaktor als Null angegeben ist, wird beim Beschneiden einfach der Baum gefunden, der bei Validierungsdaten in Bezug auf die Gesamtvarianz des Terminalknotens die beste Leistung erbringt. Größere Werte des Kostenkomplexitätsfaktors führen zu kleineren Bäumen. Das Beschneiden wird auf einer Last-In-First-Out-Basis durchgeführt, was bedeutet, dass der zuletzt gewachsene Knoten als erster eliminiert wird.
Ensemble-Methoden
XLMiner V2015 bietet drei leistungsstarke Ensemble-Methoden zur Verwendung mit Regressionsbäumen: Bagging (Bootstrap-Aggregation), Boosting und Random Trees. Der Regressionsbaumalgorithmus kann verwendet werden, um ein Modell zu finden, das zu guten Vorhersagen für die neuen Daten führt. Wir können die Statistiken und Verwirrungsmatrizen des aktuellen Prädiktors anzeigen, um festzustellen, ob unser Modell gut zu den Daten passt. Aber woher wissen wir, ob es einen besseren Prädiktor gibt, der nur darauf wartet, gefunden zu werden? Die Antwort ist, dass wir nicht wissen, ob ein besserer Prädiktor existiert. Ensemble-Methoden ermöglichen es uns jedoch, mehrere schwache Regressionsbaummodelle zu kombinieren, die zusammen ein neues, genaues, starkes Regressionsbaummodell bilden. Diese Methoden arbeiten, indem sie mehrere verschiedene Regressionsmodelle erstellen, indem sie verschiedene Stichproben des ursprünglichen Datensatzes entnehmen und dann ihre Ausgaben kombinieren. (Die Ergebnisse können durch mehrere Techniken kombiniert werden, z. B. Mehrheitsvotum für die Klassifizierung und Mittelwertbildung für die Regression) Diese Kombination von Modellen reduziert effektiv die Varianz im starken Modell. Die drei in XLMiner angebotenen Arten von Ensemble-Methoden (Bagging, Boosting und Random Trees) unterscheiden sich in drei Punkten: 1) die Auswahl des Trainingssatzes für jeden Prädiktor oder jedes schwache Modell; 2) wie die schwachen Modelle generiert werden; und 3) wie die Ausgänge kombiniert werden. Bei allen drei Methoden wird jedes schwache Modell auf dem gesamten Trainingssatz trainiert, um in einem Teil des Datensatzes kompetent zu werden.
Bagging (Bootstrap Aggregating) war einer der ersten Ensemble-Algorithmen, die jemals geschrieben wurden. Es ist ein einfacher Algorithmus, aber sehr effektiv. Bagging generiert mehrere Trainingssätze mithilfe von Zufallsstichproben mit Ersetzung (Bootstrap-Sampling), wendet den Regressionsbaumalgorithmus auf jeden Datensatz an und berechnet dann den Durchschnitt unter den Modellen, um die Vorhersagen für die neuen Daten zu berechnen. Der größte Vorteil von Bagging ist die relative Leichtigkeit, dass der Algorithmus parallelisiert werden kann, was ihn zu einer besseren Auswahl für sehr große Datensätze macht.
Boosting baut ein starkes Modell auf, indem es Modelle nacheinander trainiert, um sich auf Datensätze zu konzentrieren, die in früheren Modellen ungenau vorhergesagte Werte erhalten. Nach Abschluss werden alle Prädiktoren durch eine gewichtete Mehrheit kombiniert. XLMiner bietet drei Varianten des Boostings, wie sie vom AdaBoost-Algorithmus implementiert werden (einer der beliebtesten Ensemble-Algorithmen, die heute verwendet werden): M1 (Freund), M1 (Breiman) und SAMME (Stagewise Additive Modeling using a Multi-class Exponential).
Adaboost.M1 weist zunächst jedem Datensatz oder jeder Beobachtung ein Gewicht (wb(i)) zu. Diese Gewichtung ist ursprünglich auf 1 / n festgelegt und wird bei jeder Iteration des Algorithmus aktualisiert. Mit diesem ersten Trainingssatz (Tb) wird ein ursprünglicher Regressionsbaum erstellt und ein Fehler berechnet als
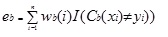
wobei die Funktion I() 1 zurückgibt, wenn true und 0, wenn nicht.
Der Fehler des Regressionsbaums in der b-ten Iteration wird verwendet, um die Konstante zu berechnen ?b. Diese Konstante wird verwendet, um das Gewicht (wb (i)) zu aktualisieren. In AdaBoost.M1 (Freund) wird die Konstante als
ab= ln((1-eb)/eb)
In AdaBoost berechnet.M1 (Breiman), die Konstante wird berechnet als
ab= 1/2ln((1-eb)/eb)
In SAMME wird die Konstante berechnet als
ab= 1/2ln((1-eb)/eb + ln(k-1) wobei k die Anzahl der Klassen ist
wobei die Anzahl der Kategorien gleich 2 ist, verhält sich SAMME genauso wie AdaBoost Breiman.
In jeder der drei Implementierungen (Freund, Breiman oder SAMME) lautet das neue Gewicht für die (b + 1) -te Iteration

Danach werden die Gewichte alle auf die Summe von 1 angepasst. Infolgedessen werden die den Beobachtungen zugewiesenen Gewichte, denen ungenaue Vorhersagewerte zugewiesen wurden, erhöht, und die den Beobachtungen zugewiesenen Gewichte, denen genaue Vorhersagewerte zugewiesen wurden, werden verringert. Diese Anpassung zwingt das nächste Regressionsmodell, die Datensätze, denen ungenaue Vorhersagen zugewiesen wurden, stärker zu betonen. (Das ? die Konstante wird auch in der endgültigen Berechnung verwendet, wodurch das Regressionsmodell mit dem geringsten Fehler mehr Einfluss hat.) Dieser Vorgang wiederholt sich, bis b = Anzahl der schwachen Lernenden. Der Algorithmus berechnet dann den gewichteten Durchschnitt unter allen schwachen Lernenden und weist diesen Wert dem Datensatz zu. Boosting liefert im Allgemeinen bessere Modelle als Bagging; Es hat jedoch einen Nachteil, da es nicht parallelisierbar ist. Wenn die Anzahl der schwachen Lernenden groß ist, wäre ein Boosting daher nicht geeignet.
Die Random Trees Methode (Random Forests) ist eine Variante des Bagging. Diese Methode trainiert mehrere schwache Regressionsbäume mit einer festen Anzahl zufällig ausgewählter Features (sqrt für die Klassifizierung und Anzahl der Features / 3 für die Vorhersage), nimmt dann den Durchschnittswert für die schwachen Lernenden und weist diesen Wert dem starken Prädiktor zu. Typischerweise kann die Anzahl der erzeugten schwachen Bäume je nach Größe und Schwierigkeit des Trainingssatzes zwischen mehreren hundert und mehreren Tausend liegen. Zufällige Bäume sind parallelisierbar, da sie eine Variante des Absackens sind. Da Tandom Trees jedoch in jeder Iteration eine begrenzte Anzahl von Features auswählt, ist die Leistung von Zufallsbäumen schneller als das Absacken.
Regressionsbaum-Ensemble-Methoden sind sehr leistungsfähige Methoden und führen in der Regel zu einer besseren Leistung als ein einzelner Baum. Diese Funktionserweiterung in XLMiner V2015 bietet genauere Vorhersagemodelle und sollte gegenüber der Einzelbaummethode berücksichtigt werden.