Reinforcement Learning via Markov Decision Process in den Griff bekommen
Dieser Artikel wurde im Rahmen des Data Science Blogathon veröffentlicht.
Einführung
Reinforcement Learning (RL) ist eine Lernmethode, mit der der Lernende lernt, sich in einer interaktiven Umgebung zu verhalten, indem er seine eigenen Handlungen und Belohnungen für seine Handlungen verwendet. Der Lernende, oft Agent genannt, entdeckt, welche Aktionen die maximale Belohnung bringen, indem er sie ausnutzt und erforscht.

Eine Schlüsselfrage ist – wie unterscheidet sich RL vom überwachten und unbeaufsichtigten Lernen?
Der Unterschied liegt in der Interaktionsperspektive. Überwachtes Lernen teilt dem Benutzer / Agenten direkt mit, welche Aktion er ausführen muss, um die Belohnung anhand eines Trainingsdatensatzes mit markierten Beispielen zu maximieren. Auf der anderen Seite ermöglicht RL dem Agenten direkt, Belohnungen (positiv und negativ) zu nutzen, um seine Aktion auszuwählen. Es unterscheidet sich daher auch vom unbeaufsichtigten Lernen, da es beim unbeaufsichtigten Lernen darum geht, eine Struktur zu finden, die in Sammlungen unbeschrifteter Daten verborgen ist.
Reinforcement Learning Formulierung via Markov Decision Process (MDP)
Die Grundelemente eines Reinforcement Learning Problems sind:
- Environment: Die Außenwelt, mit der der Agent interagiert
- State: Aktuelle Situation des Agenten
- Reward: Numerisches Rückkopplungssignal aus der Umgebung
- Policy: Methode, um den Zustand des Agenten Aktionen zuzuordnen. Eine Richtlinie wird verwendet, um eine Aktion in einem bestimmten Zustand auszuwählen
- Wert: Zukünftige Belohnung (verzögerte Belohnung), die ein Agent erhalten würde, wenn er eine Aktion in einem bestimmten Zustand ausführt
Der Markov-Entscheidungsprozess (MDP) ist ein mathematisches Framework zur Beschreibung einer Umgebung im Verstärkungslernen. Die folgende Abbildung zeigt die Interaktion zwischen Agent und Umgebung in MDP:
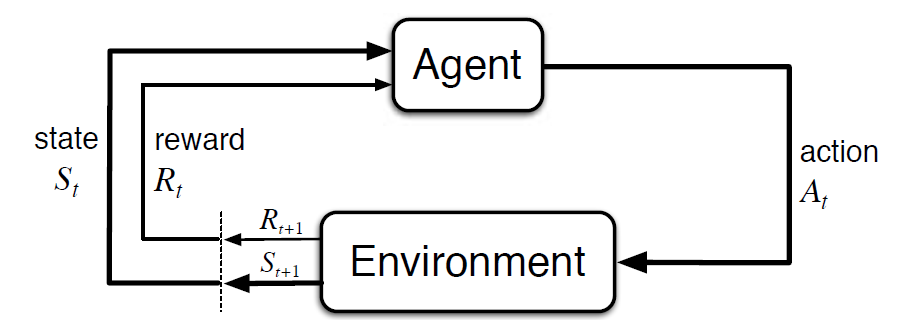
Genauer gesagt interagieren der Agent und die Umgebung bei jedem diskreten Zeitschritt, t = 0, 1, 2, 3…At in jedem Zeitschritt erhält der Agent Informationen über den Umgebungszustand St. Basierend auf dem Umgebungszustand zum Zeitpunkt t wählt der Agent eine Aktion At. Im folgenden Moment erhält der Agent auch ein numerisches Belohnungssignal Rt+1. Dies führt somit zu einer Sequenz wie S0, A0, R1, S1, A1, R2…
Die Zufallsvariablen Rt und St haben gut definierte diskrete Wahrscheinlichkeitsverteilungen. Diese Wahrscheinlichkeitsverteilungen sind aufgrund der Markov-Eigenschaft nur vom vorhergehenden Zustand und Handeln abhängig. Lassen Sie S, A und R die Mengen von Zuständen, Aktionen und Belohnungen sein. Dann ist die Wahrscheinlichkeit, dass die Werte von St, Rt und At die Werte s‘, r und a mit dem vorherigen Zustand s annehmen, gegeben durch
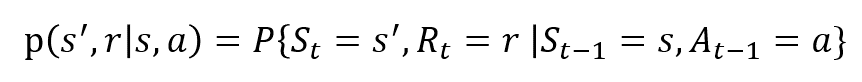
Die Funktion p steuert die Dynamik des Prozesses.
Lassen Sie uns dies anhand eines Beispiels verstehen
Lassen Sie uns nun ein einfaches Beispiel diskutieren, in dem RL verwendet werden kann, um eine Steuerungsstrategie für einen Heizprozess zu implementieren.
Die Idee ist, die Temperatur eines Raumes innerhalb der angegebenen Temperaturgrenzen zu steuern. Die Temperatur im Raum wird durch äußere Faktoren wie Außentemperatur, die erzeugte innere Wärme usw. beeinflusst.
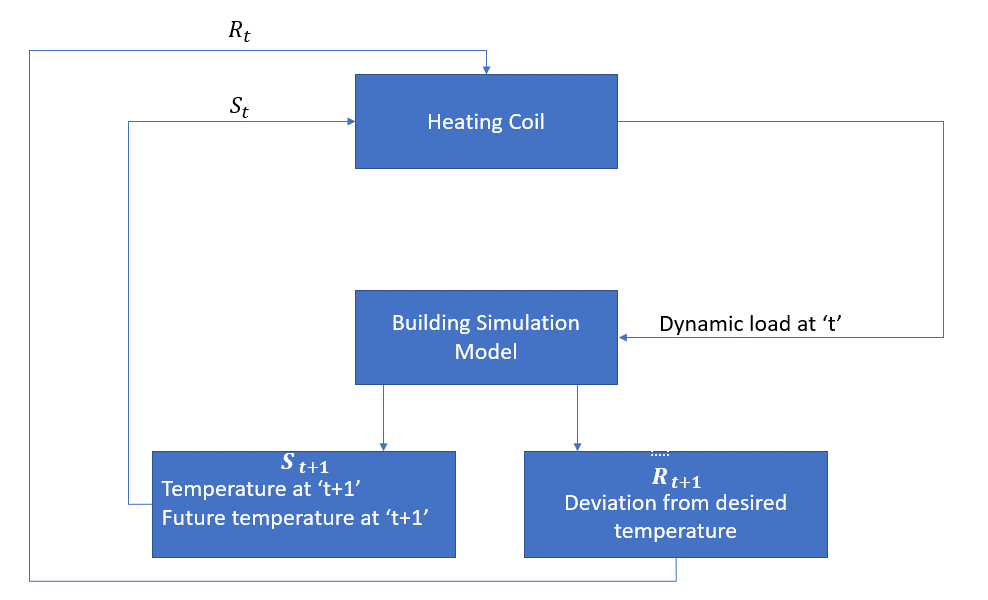
Das Mittel ist in diesem Fall die Heizschlange, die die Wärmemenge bestimmen muss, die erforderlich ist, um die Temperatur im Raum durch Interaktion mit der Umgebung zu steuern und sicherzustellen, dass die Temperatur im Raum innerhalb des angegebenen Bereichs liegt. Die Belohnung sind in diesem Fall im Wesentlichen die Kosten, die für das Abweichen von den optimalen Temperaturgrenzen gezahlt werden.
Die Aktion für den Agenten ist die dynamische Last. Diese dynamische Last wird dann dem Raumsimulator zugeführt, der im Grunde ein Wärmeübertragungsmodell ist, das die Temperatur basierend auf der dynamischen Last berechnet. In diesem Fall ist die Umgebung das Simulationsmodell. Die Zustandsvariable St enthält sowohl die gegenwärtigen als auch die zukünftigen Belohnungen.
Das folgende Blockdiagramm erklärt, wie MDP zur Steuerung der Temperatur in einem Raum verwendet werden kann:
Einschränkungen dieser Methode
Verstärkungslernen lernt vom Zustand. Der Staat ist der Input für die Politikgestaltung. Daher sollten die Statuseingaben korrekt angegeben werden. Wie wir gesehen haben, gibt es mehrere Variablen und die Dimensionalität ist riesig. Es wäre also schwierig, es für echte physische Systeme zu verwenden!
Weiterführende Literatur
Um mehr über RL zu erfahren, könnten die folgenden Materialien hilfreich sein:
- Reinforcement Learning: Eine Einführung von Richard.S.Sutton und Andrew.G.Barto: http://incompleteideas.net/book/the-book-2nd.html
- Videovorträge von David Silver auf YouTube verfügbar
- https://gym.openai.com/ ist ein Toolkit für weitere Erkundungen
Sie können diesen Artikel auch in unserer mobilen APP lesen ![]()
