Familiarizarse con el Aprendizaje por Refuerzo a través del Proceso de Decisión de Markov
Este artículo se publicó como parte del Blogathon de Ciencia de Datos.
Introducción
El aprendizaje por refuerzo (RL) es una metodología de aprendizaje mediante la cual el alumno aprende a comportarse en un entorno interactivo utilizando sus propias acciones y recompensas por sus acciones. El aprendiz, a menudo llamado agente, descubre qué acciones dan la recompensa máxima explotándolas y explorándolas.

Una pregunta clave es: ¿en qué se diferencia RL del aprendizaje supervisado y no supervisado?
La diferencia viene en la perspectiva de interacción. El aprendizaje supervisado le dice al usuario/agente directamente qué acción tiene que realizar para maximizar la recompensa utilizando un conjunto de datos de entrenamiento de ejemplos etiquetados. Por otro lado, RL permite directamente al agente hacer uso de las recompensas (positivas y negativas) que obtiene para seleccionar su acción. Por lo tanto, también es diferente del aprendizaje no supervisado porque el aprendizaje no supervisado se trata de encontrar estructuras ocultas en colecciones de datos sin etiquetar.
Formulación de Aprendizaje por refuerzo a través del Proceso de Decisión de Markov (MDP)
Los elementos básicos de un problema de aprendizaje por refuerzo son:
- Entorno: El mundo exterior con el que interactúa el agente
- Estado: Situación actual del agente
- Recompensa: Señal de retroalimentación numérica del entorno
- Política: Método para asignar el estado del agente a acciones. Una política se utiliza para seleccionar una acción en un estado dado
- Valor: Recompensa futura (recompensa retrasada) que un agente recibiría al realizar una acción en un estado dado
El proceso de Decisión de Markov (MDP) es un marco matemático para describir un entorno en el aprendizaje por refuerzo. La siguiente figura muestra la interacción entre el agente y el entorno en MDP:
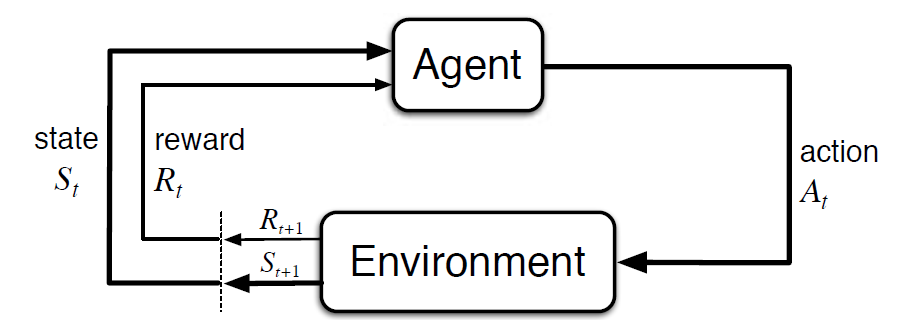
Más específicamente, el agente y el entorno interactúan en cada paso de tiempo discreto, t = 0, 1, 2, 3…At cada paso de tiempo, el agente obtiene información sobre el estado del entorno St. Basado en el estado del entorno en el instante t, el agente elige una acción En. En el siguiente instante, el agente también recibe una señal de recompensa numérica Rt+1. Esto da lugar a una secuencia como S0, A0, R1, S1, A1, R2
Las variables aleatorias Rt y St tienen distribuciones de probabilidad discretas bien definidas. Estas distribuciones de probabilidad dependen solo del estado y la acción precedentes en virtud de la Propiedad de Markov. Sean S, A y R los conjuntos de estados, acciones y recompensas. Entonces la probabilidad de que los valores de Pt, Rt y En tomar los valores de s’, r y con el estado anterior de s está dada por,
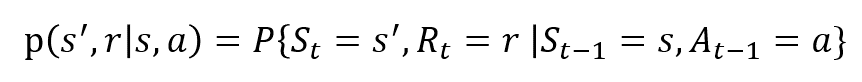
La función p controla la dinámica del proceso.
Entendamos esto Usando un ejemplo
Ahora discutamos un ejemplo simple donde RL se puede usar para implementar una estrategia de control para un proceso de calentamiento.
La idea es controlar la temperatura de una habitación dentro de los límites de temperatura especificados. La temperatura dentro de la habitación está influenciada por factores externos como la temperatura exterior, el calor interno generado, etc.
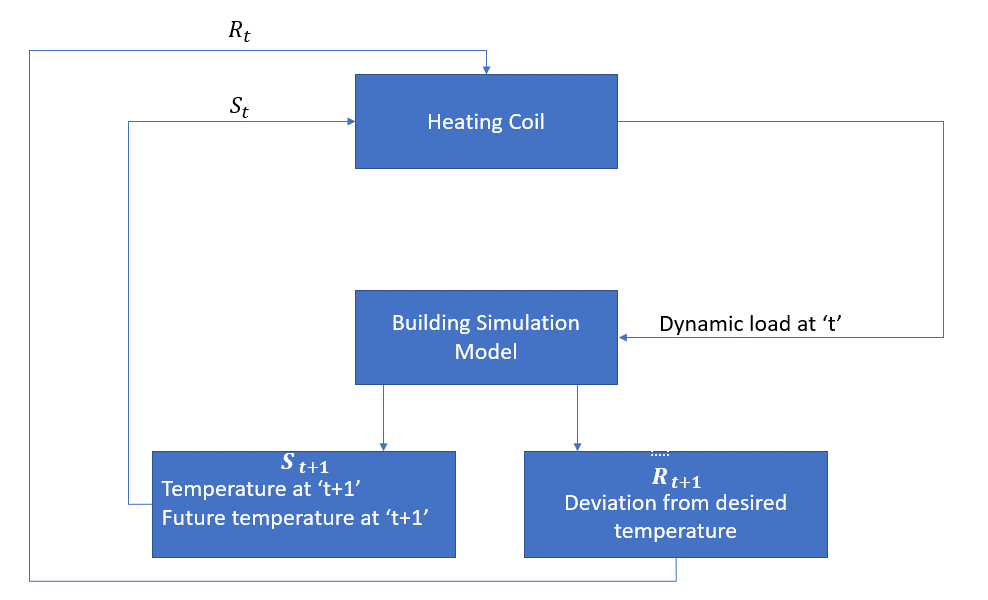
El agente, en este caso, es el serpentín calefactor que tiene que decidir la cantidad de calor necesaria para controlar la temperatura dentro de la habitación interactuando con el entorno y asegurarse de que la temperatura dentro de la habitación esté dentro del rango especificado. La recompensa, en este caso, es básicamente el costo pagado por desviarse de los límites de temperatura óptimos.
La acción para el agente es la carga dinámica. Esta carga dinámica se alimenta al simulador de habitación, que es básicamente un modelo de transferencia de calor que calcula la temperatura en función de la carga dinámica. En este caso, el entorno es el modelo de simulación. La variable de estado St contiene las recompensas presentes y futuras.
El siguiente diagrama de bloques explica cómo se puede usar MDP para controlar la temperatura dentro de una habitación:
Limitaciones de este método
Aprendizaje por refuerzo aprende del estado. El Estado es el insumo para la formulación de políticas. Por lo tanto, las entradas del Estado deben darse correctamente. También como hemos visto, hay múltiples variables y la dimensionalidad es enorme. ¡Así que usarlo para sistemas físicos reales sería difícil!
Lectura adicional
Para saber más sobre RL, los siguientes materiales podrían ser útiles:
- Aprendizaje por refuerzo: Una Introducción de Richard.S. Sutton y Andrew.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- Conferencias en vídeo de David Silver disponibles en YouTube
- https://gym.openai.com/ es un kit de herramientas para una mayor exploración
También puede leer este artículo en nuestra aplicación móvil ![]()
