Getting pureutuu vahvistaminen Learning via Markov Decision Process
Tämä artikkeli julkaistiin osana Data Science Blogathon.
Johdanto
vahvistaminen oppiminen (RL) on oppimismenetelmä, jonka avulla oppija oppii käyttäytymään interaktiivisessa ympäristössä omien tekojensa avulla ja palkitsee teoistaan. Oppija, jota usein kutsutaan agentiksi, huomaa hyödyntämällä ja tutkimalla, mitkä teot antavat suurimman palkkion.

avainkysymys on – miten RL eroaa valvotusta ja valvomattomasta oppimisesta?
ero tulee vuorovaikutusnäkökulmasta. Valvottu oppiminen kertoo käyttäjälle / agentille suoraan, mitä toimia hänen on tehtävä maksimoidakseen palkkion käyttämällä koulutustietokantaa merkityistä esimerkeistä. Toisaalta, RL suoraan mahdollistaa agentti hyödyntää palkintoja (positiivisia ja negatiivisia) se saa valita sen toimintaa. Se eroaa siis myös valvomattomasta oppimisesta, koska valvomattomassa oppimisessa on kyse rakenteen löytämisestä, joka on piilotettu merkitsemättömien tietojen kokoelmiin.
vahvistaminen oppimisen muotoilu Markov Decision Processin (MDP) kautta
vahvistamisen oppimisongelman peruselementit ovat:
- ympäristö: ulkomaailma, jonka kanssa agentti on vuorovaikutuksessa
- tila: agentin nykytilanne
- palkinto: numeerinen palautesignaali ympäristöstä
- politiikka: menetelmä agentin tilan kartoittamiseksi toimiin. Toimintaperiaatteella valitaan toimi tietyssä tilassa
- arvo: Future reward (delayed reward), jonka agentti saisi toteuttamalla toimen tietyssä tilassa
Markov Decision Process (MDP) on matemaattinen viitekehys, jolla kuvataan ympäristöä vahvistusoppimisessa. Seuraavassa kuvassa on aineen ja ympäristön vuorovaikutus MDP: ssä:
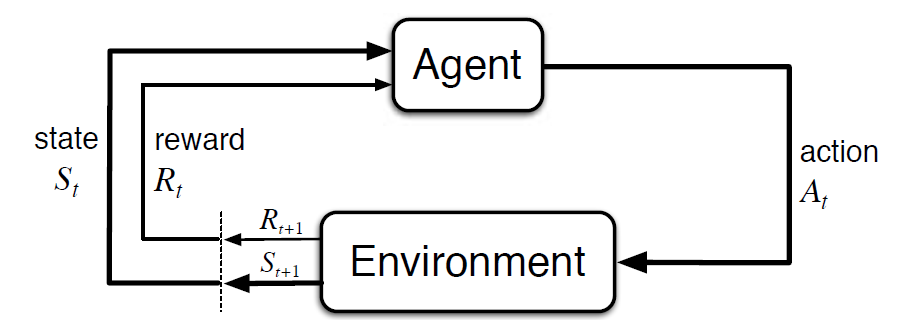
tarkemmin ottaen tekijä ja ympäristö vuorovaikuttavat jokaisessa diskreetissä aikavaiheessa, t = 0, 1, 2, 3…At joka kerta vaiheessa agentti saa tietoa ympäristön tilasta St. ympäristön tilan perusteella instant t, agentti valitsee toiminnon. Seuraavassa hetkessä agentti saa myös numeerisen palkitsemissignaalin Rt + 1. Näin saadaan S0, A0, R1, s1, A1, R2…
satunnaismuuttujilla Rt ja St on tarkoin määritellyt diskreetit todennäköisyysjakaumat. Nämä todennäköisyysjakaumat ovat riippuvaisia vain edeltävästä tilasta ja toiminnasta Markovin omaisuuden perusteella. Olkoon S, A ja R joukko valtioita, toimia ja palkintoja. Silloin todennäköisyys sille, että ST: n, Rt: n ja otettaessa arvot s’, r ja A aikaisemman tilan s kanssa saadaan,
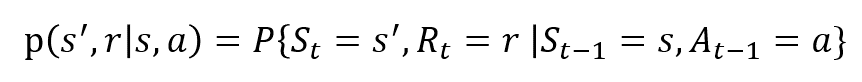
funktio P ohjaa prosessin dynamiikkaa.
Ymmärtäkäämme tämä esimerkin avulla
keskustellaanpa nyt yksinkertaisesta esimerkistä, jossa RL: ää voidaan käyttää lämmitysprosessin ohjausstrategian toteuttamiseen.
ideana on säädellä huoneen lämpötilaa määrätyissä lämpötilarajoissa. Huoneen sisälämpötilaan vaikuttavat ulkoiset tekijät, kuten ulkolämpötila, sisäinen lämpö jne.
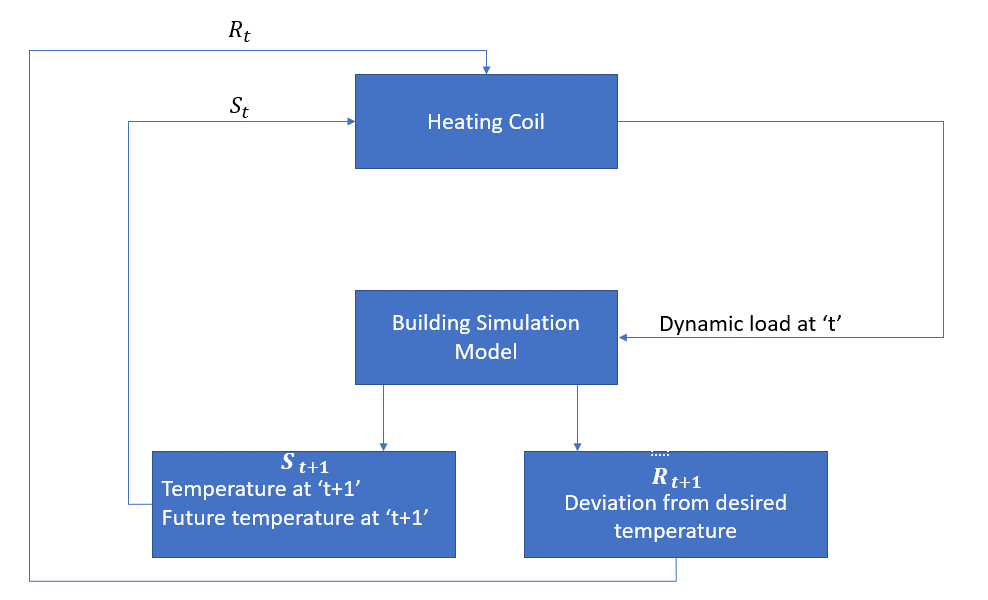
tässä tapauksessa tekijä on lämmityskela, jonka on päätettävä tarvittava lämpömäärä säätelemään huoneen sisälämpötilaa vuorovaikutuksessa ympäristön kanssa ja varmistettava, että huoneen sisälämpötila on määritellyllä alueella. Palkkio on tässä tapauksessa käytännössä hinta, joka maksetaan optimaalisista lämpötilarajoista poikkeamisesta.
aineen toiminta on dynaaminen kuormitus. Tämä dynaaminen kuormitus syötetään sitten huoneen simulaattoriin, joka on pohjimmiltaan lämmönsiirtomalli, joka laskee lämpötilan dynaamisen kuormituksen perusteella. Tässä tapauksessa ympäristö on simulaatiomalli. Valtion muuttuja St sisältää sekä nykyiset että tulevat palkkiot.
seuraavassa lohkokaaviossa selitetään, miten MDP: tä voidaan käyttää huoneen sisälämpötilan säätöön:
tämän menetelmän rajoitukset
vahvistaminen oppiminen oppii valtiolta. Valtio on politiikan tekemisen panos. Näin ollen valtion panokset olisi annettava oikein. Myös kuten olemme nähneet, muuttujia on useita ja dimensionaliteetti on valtava. Joten sen käyttäminen todellisiin fyysisiin järjestelmiin olisi vaikeaa!
lisätietoja
RL: stä voi olla avuksi seuraavissa materiaaleissa:
- vahvistaminen Learning: an Introduction by Richard.S. Sutton ja Andrew.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- David Silverin videoluentoja saatavilla YouTubessa
- https://gym.openai.com/ on työkalupakki jatkotutkimuksiin
voit lukea myös tämän artikkelin Mobiilisovelluksestamme ![]()
