Miten semanttinen segmentointi tehdään syväoppimisen
avulla tämä artikkeli on kattava yleiskatsaus, joka sisältää vaiheittaisen oppaan syväoppimisen kuvasegmentointimallin toteuttamiseksi.
jaoimme uuden blogin semanttisesta segmentoinnista täällä: a 2021 guide to semanttinen segmentointi
nykyään semanttinen segmentointi on yksi tietokonenäön keskeisistä ongelmista. Isossa kuvassa semanttinen segmentointi on yksi korkean tason tehtävistä, joka tasoittaa tietä kohti täydellistä kohtausten ymmärtämistä. Kohtauksen ymmärtämisen tärkeyttä tietokonenäköongelmana korostaa se, että yhä useammat sovellukset ravitsevat päättelemällä tietoa kuvista. Jotkin näistä sovelluksista sisältävät itseohjautuvia ajoneuvoja, ihmisen ja tietokoneen vuorovaikutusta, virtuaalitodellisuutta jne. Syväoppimisen yleistyttyä viime vuosina monia semanttisen segmentoinnin ongelmia on pyritty ratkaisemaan käyttämällä syväarkkitehtuureja, useimmiten Convolutionaalisia Neuroverkkoja, jotka päihittävät muut lähestymistavat suurella marginaalilla tarkkuudessa ja tehokkuudessa.
- mitä on Semanttinen segmentointi?
- mitä ovatko olemassa olevat semanttisen segmentoinnin lähestymistavat?
- 1 — Aluepohjainen semanttinen segmentointi
- 2 — täysin Convolutionaalinen Verkkoperusteinen semanttinen segmentointi
- 3 — heikosti valvottu semanttinen segmentointi
- semanttisen segmentoinnin tekeminen täysin Convolutionaalisella verkolla
- vaihe 1
- Vaihe 2
- Step 3
- Vaihe 4
- Vaihe 5
- saatat olla kiinnostunut uusimmista postauksistamme:
mitä on Semanttinen segmentointi?
semanttinen segmentointi on luonnollinen vaihe etenemisessä karkeasta hienoon päättelyyn:alkuperä voi sijaita luokittelussa, jossa tehdään ennuste kokonaiselle syötteelle.Seuraava vaihe on lokalisointi / havaitseminen, jotka antavat luokkien lisäksi lisätietoa kyseisten luokkien paikkatietojen sijainnista.Lopuksi semanttinen segmentointi saavuttaa hienorakeisen päättelyn tekemällä tiheän ennustuksen päättelemällä merkinnät jokaiselle pikselille niin, että jokainen pikseli merkitään sen sulkevan objektimalmin alueen luokalla.
on myös syytä tarkastella joitakin vakiomuotoisia syväverkkoja, jotka ovat antaneet merkittävän panoksen tietokonenäön alalla, sillä niitä käytetään usein semanttisten segmentointijärjestelmien pohjana:
- alexnet: Toronton uraauurtava syvä CNN, joka voitti IMAGEnet-kilpailun 2012 testitarkkuudella 84,6%. Se koostuu 5 convolutionary kerrokset, max-pooling niistä, ReLUs kuin ei-linearities, 3 täysin convolutionary kerrokset, ja dropout.
- VGG-16: Tämä Oxfordin malli voitti vuoden 2013 ImageNet-kilpailun 92,7 prosentin tarkkuudella. Se käyttää kasaa konvoluutiokerroksia, joissa on pieniä vastaanottavia kenttiä ensimmäisissä kerroksissa muutaman suuren vastaanottavan kentän sijaan.
- GoogLeNet: tämä Googlen verkko voitti vuoden 2014 ImageNet-kilpailun 93,3 prosentin tarkkuudella. Se koostuu 22 kerroksesta ja vastikään käyttöön otetusta rakennuspalikasta nimeltä inception module. Moduuli koostuu verkko-verkko-kerroksesta, yhdistämisoperaatiosta, suurikokoisesta konvoluutiokerroksesta ja pienikokoisesta konvoluutiokerroksesta.
- ResNet: tämä Microsoftin malli voitti vuoden 2016 ImageNet-kilpailun 96,4 prosentin tarkkuudella. Se on tunnettu syvyytensä (152 kerrosta) ja jäännöslohkojen käyttöönoton vuoksi. Jäännöslohkot käsittelevät todella syvän arkkitehtuurin koulutuksen ongelmaa ottamalla käyttöön identiteetin ohitusliitännät, jotta kerrokset voivat kopioida tuotantopanoksensa seuraavalle tasolle.
mitä ovatko olemassa olevat semanttisen segmentoinnin lähestymistavat?
yleinen semanttinen segmentointiarkkitehtuuri voidaan laajasti ajatella kooderiverkostona, jota seuraa dekooderiverkko:
- kooderi on yleensä valmiiksi koulutettu luokitusverkosto, kuten VGG / ResNet, jota seuraa dekooderiverkko.
- dekooderin tehtävänä on semanttisesti projisoida kooderin oppimat erottelevat ominaisuudet (alempi resoluutio) pikseliavaruuteen (korkeampi resoluutio), jotta saadaan tiheä luokitus.
toisin kuin luokittelu, jossa hyvin syvän verkon lopputulos on ainoa tärkeä asia, semanttinen segmentointi edellyttää pikselitason syrjintää, mutta myös mekanismia, jolla kooderin eri vaiheissa opitut erottelevat ominaisuudet projisoidaan pikseliavaruuteen. Eri lähestymistavat käyttävät erilaisia mekanismeja osana dekoodausmekanismia. Tarkastellaanpa kolmea pääasiallista lähestymistapaa:
1 — Aluepohjainen semanttinen segmentointi
aluepohjaiset menetelmät noudattavat yleensä ”segregation using recognition”-putkea, jossa ensin poimitaan vapaamuotoiset alueet kuvasta ja kuvataan ne, minkä jälkeen tehdään alueluokitus. Testiaikana aluekohtaiset ennustukset muutetaan pikseliennusteiksi, yleensä merkitsemällä pikseli sen sisältävän korkeimman pisteytysalueen mukaan.
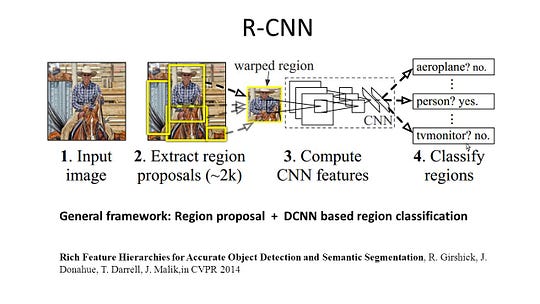
r-CNN (Regions with CNN feature) on yksi aluekohtaisten menetelmien edustusteos. Se suorittaa semanttisen segmentoinnin kohteen havaitsemisen tulosten perusteella. Tarkemmin sanottuna R-CNN käyttää ensin valikoivaa hakua poimiakseen suuren määrän objektiehdotuksia ja laskee sitten CNN: n ominaisuudet jokaiselle niistä. Lopuksi se luokittelee jokaisen alueen käyttäen luokkakohtaista lineaarista SVMs: ää. Verrattuna perinteisiin CNN-rakenteisiin, jotka on tarkoitettu lähinnä kuvien luokitteluun, R-CNN voi käsitellä monimutkaisempia tehtäviä, kuten objektien havaitsemista ja kuvien segmentointia, ja siitä tulee jopa yksi tärkeä perusta molemmille kentille. Lisäksi R-CNN voidaan rakentaa minkä tahansa CNN: n vertailurakenteiden, kuten Alexnetin, VGG: n, GoogLeNet: n ja Resnetin päälle.
kuvan segmentointitehtävää varten R-CNN poimi kullekin alueelle 2 erilaista ominaisuutta: täyden alueen ominaisuus ja etualan ominaisuus, ja totesi, että se voisi johtaa parempaan suorituskykyyn, kun ne yhdistetään alueen ominaisuudeksi. R-CNN saavutti merkittäviä suorituskykyparannuksia erittäin syrjivien CNN-ominaisuuksien käytön ansiosta. Se kärsii kuitenkin myös parista segmentointitehtävän haittapuolesta:
- ominaisuus ei ole yhteensopiva segmentointitehtävän kanssa.
- ominaisuus ei sisällä tarpeeksi paikkatietoa tarkkaa rajanvetoa varten.
- segmenttipohjaisten ehdotusten tekeminen vie aikaa ja vaikuttaisi suuresti lopulliseen suoritukseen.
näiden pullonkaulojen vuoksi ongelmiin on ehdotettu viimeaikaista tutkimusta, kuten SDS: ää, Hyperkolumneja, Mask R-CNN: ää.
2 — täysin Convolutionaalinen Verkkoperusteinen semanttinen segmentointi
alkuperäinen täysin Convolutionaalinen Verkko (FCN) oppii kartoituksen pikseleistä pikseleihin ilman, että alueehdotuksia poimitaan. FCN-verkkoputki on klassisen CNN: n jatke. Pääajatuksena on saada klassinen CNN ottamaan syötteenä mielivaltaisen kokoisia kuvia. CNNs: n rajoitus hyväksyä ja tuottaa merkintöjä vain tietyn kokoisille tuotantopanoksille tulee täysin kytketyistä kerroksista, jotka ovat kiinteitä. Päinvastoin, FCNs: llä on vain convolutionaalisia ja yhdistäviä kerroksia, jotka antavat heille mahdollisuuden tehdä ennusteita mielivaltaisen kokoisista panoksista.
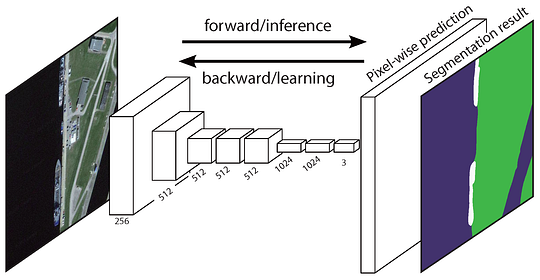
resoluutio output ominaisuus kartat on alas otos. Siksi FCN: n suorat ennustukset ovat tyypillisesti matalaresoluutioisia, jolloin objektin rajat ovat suhteellisen sumeita. Tämän ongelman ratkaisemiseksi on ehdotettu useita kehittyneempiä FCN-pohjaisia lähestymistapoja, kuten SegNet, DeepLab-CRF ja Dilated Convolutions.
3 — heikosti valvottu semanttinen segmentointi
useimmat merkitykselliset semanttisen segmentoinnin menetelmät perustuvat suureen määrään kuvia, joissa on pikselimäinen segmentointinaamio. Näiden naamioiden merkitseminen manuaalisesti on kuitenkin melko aikaa vievää, turhauttavaa ja kaupallisesti kallista. Siksi on viime aikoina ehdotettu joitakin heikosti valvottuja menetelmiä, jotka on omistettu semanttisen segmentoinnin täyttämiseen käyttämällä merkittyjä rajauslaatikoita.

esimerkiksi Boxsup käytti bounding box-merkintää valvontana kouluttaakseen verkkoa ja parantaakseen iteratiivisesti arvioituja semanttisen segmentoinnin naamareita. Se käsitteli yksinkertaisesti heikkoa valvonnan rajoittamista syöttömerkintämelun ongelmana ja tutki rekursiivista koulutusta ilmoitusten poistamisstrategiana. Pikselitasomerkinnät tulkitsivat segmentointitehtävää moniasteisen oppimiskehyksen sisällä ja lisäsivät ylimääräisen kerroksen rajoittamaan mallia antaakseen enemmän painoarvoa tärkeille pikseleille kuvatason luokittelussa.
semanttisen segmentoinnin tekeminen täysin Convolutionaalisella verkolla
tässä osiossa käydään läpi vaiheittainen toteutus semanttisen segmentoinnin suosituimmasta arkkitehtuurista-täysin Convolutionaalisesta verkosta (FCN). Toteutamme sen käyttämällä TensorFlow-kirjastoa Python 3: ssa yhdessä muiden riippuvuuksien, kuten Numpy: n ja Scipy.In tässä harjoituksessa merkitään tien Pikselit kuviin FCN: n avulla. Teemme yhteistyötä kitti-Tieaineiston kanssa tie – / kaistatunnistukseen. Tämä on yksinkertainen harjoitus Udacityn itsestään ajavan auton Nano-degree-ohjelmasta, josta voit oppia lisää asennuksesta tässä GitHub repossa.

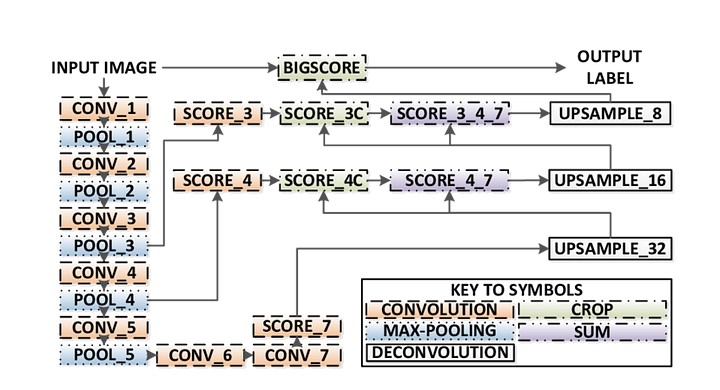
tässä ovat FCN-arkkitehtuurin keskeiset piirteet:
- FCN siirtää tietoa vgg16: sta semanttisen segmentoinnin suorittamiseen.
- vgg16: n täysin yhdistetyt kerrokset muunnetaan täysin konvolatiivisiksi kerroksiksi käyttäen 1×1 konvoluutiota. Tämä prosessi tuottaa luokan läsnäololämpökartan matalalla resoluutiolla.
- näiden matalaresoluutioisten semanttisten ominaisuuksien karttojen upsampling tapahtuu transponoitujen konvoluutioiden avulla (alustetaan bilineaarisilla interpolointisuodattimilla).
- jokaisessa vaiheessa upsamplingprosessia tarkennetaan lisäämällä ominaisuuksia karkeammista, mutta korkeamman resoluution ominaisuuskartoista alemmista kerroksista vgg16: ssa.
- Skip-yhteys otetaan käyttöön jokaisen konvoluutiolohkon jälkeen, jotta seuraava lohko voi poimia abstraktimpia, luokkasensitiivisempiä ominaisuuksia aiemmin yhdistetyistä ominaisuuksista.
FCN: stä on olemassa 3 versiota (FCN-32, FCN-16, FCN-8). Toteutamme FCN-8: n, kuten yksityiskohtainen vaihe vaiheelta alla:
- kooderi: kooderina käytetään valmiiksi koulutettua VGG16: ta. Dekooderi alkaa Vgg16: n kerroksesta 7.
- FCN Layer-8: vgg16: n viimeinen täysin kytketty kerros korvataan 1×1-konvoluutiolla.
- FCN Layer-9: FCN Layer-8 on 2-kertainen, jotta mitat vastaavat VGG 16: n Kerrosta 4 käyttäen transponoitua konvoluutiota parametreilla: (kernel=(4,4), stride=(2,2), paddding=’same’). Tämän jälkeen VGG16: n kerroksen 4 ja FCN Layer-9 väliin lisättiin ohitusliitäntä.
- FCN Layer-10: FCN Layer-9 on nostettu 2 kertaa vastaamaan mittoja Vgg16: n Layer 3: n kanssa käyttäen transponoitua konvoluutiota parametreilla: (kernel=(4,4), stride=(2,2), paddding= ”same”). Tämän jälkeen VGG 16: n kerroksen 3 ja FCN Layer-10 väliin lisättiin ohitusliitäntä.
- FCN Layer-11: FCN Layer-10 on upsampled 4 kertaa vastaamaan mitat tulo kuvan koon niin saamme todellinen kuva takaisin ja syvyys on yhtä monta luokkaa, käyttäen transponed konvoluutio parametrit: (kernel=(16,16), stride=(8,8), paddding=’sama’).
vaihe 1
ensin ladataan valmiiksi koulutettu VGG-16-malli TensorFlow ’ hun. Kun otetaan käyttöön TensorFlow-istunto ja polku VGG-kansioon (joka on ladattavissa täältä), palautamme tensorien monikappaleen VGG-mallista, mukaan lukien kuvan syöttö, keep_prob (keskeyttämisnopeuden hallitsemiseksi), kerros 3, Kerros 4 ja kerros 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7vgg16 funktio
Vaihe 2
nyt keskitytään luomaan kerrokset FCN: lle käyttäen VGG-mallin tensoreita. Koska tensorit VGG layer output ja useita luokkia luokitella, palaamme Tensor viimeinen kerros, että lähtö. Erityisesti käytämme 1×1 konvoluutiota kooderikerroksiin ja lisäämme sitten dekooderikerroksia verkkoon skip-yhteyksillä ja upsamplingilla.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11Layers function
Step 3
seuraava askel on optimoida neuroverkkomme eli rakentaa tensorivirtaushäviöfunktioita ja optimointitoimintoja. Tässä käytämme cross entropiaa häviöfunktiona ja Adam optimointialgoritmina.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opoptimoi funktio
Vaihe 4
tässä määritellään train_nn-funktio, joka ottaa huomioon tärkeät parametrit, kuten aikakausien määrän, eräkoon, häviöfunktion, optimointitoiminnon sekä syöttökuvien paikkamerkit, etikettikuvat, oppimisnopeuden. Koulutusprosessia varten asetimme myös keep_probability-arvon 0.5: een ja learning_rate-arvon 0.001: een. Jotta pysyisimme ajan tasalla, tulostamme tappion myös harjoituksissa.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Vaihe 5
vihdoin, on aika kouluttaa verkko! Tässä ajo-funktiossa rakennamme ensin verkkomme load_vgg -, layers-ja optimointitoiminnolla. Sitten koulutamme verkon train_nn-funktiolla ja tallennamme päättelytiedot tietueita varten.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)Suorita funktio
parametreistamme valitsemme epochs = 40, batch_size = 16, num_classes = 2 ja image_shape = (160, 576). Kun olet tehnyt 2 trial passs kanssa dropout = 0.5 ja dropout = 0.75, huomasimme, että 2nd trial tuottaa parempia tuloksia paremman keskimääräisen tappiot.

Katso koko Koodi tästä linkistä: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
If you nautti this piece, I ’ d love it share it 👏 and spread the knowledge.
saatat olla kiinnostunut uusimmista postauksistamme:
- AWS Textract
- Data Extraction
Aloita Nanonettien käyttö automaatioon
kokeile mallia tai pyydä demo tänään!
TRY NOW
