Object Detection for Dummies Osa 3: R-CNN Family
osassa 3 tarkastelisimme neljää objektin tunnistusmallia: R-CNN, Fast R-CNN, Faster R-CNN ja Mask R-CNN. Nämä mallit ovat hyvin samankaltaisia ja uudet versiot osoittavat suurta nopeusparannusta vanhempiin verrattuna.
”Object Detection for Dummies” – sarjassa aloitimme kuvankäsittelyn peruskäsitteistä, kuten gradienttivektoreista ja HOGISTA, osassa 1. Sitten esittelimme klassisia convolutionaalisia neuroverkkoarkkitehtuurimalleja luokitteluun ja pioneerimalleja objektien tunnistamiseen, Overfeat ja DPM, osassa 2. Sarjan kolmannessa postauksessa käydään läpi R-CNN: n (”Region-based CNN”) perheen malleja.
Linkit kaikkiin sarjan julkaisuihin: .
tässä on luettelo tämän postauksen kattamista papereista 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
R-CNN
R-CNN (Girshick et al., 2014) is short for ”Region-based Convolutional Neural Networks”. The main idea is composed of two steps. Ensinnäkin, käyttämällä selektiivistä hakua, se tunnistaa hallittavan määrän bounding-box objektin alueen ehdokkaita (”region of interest” tai ”RoI”). Ja sitten se poimii CNN ominaisuuksia kunkin alueen itsenäisesti luokittelu.
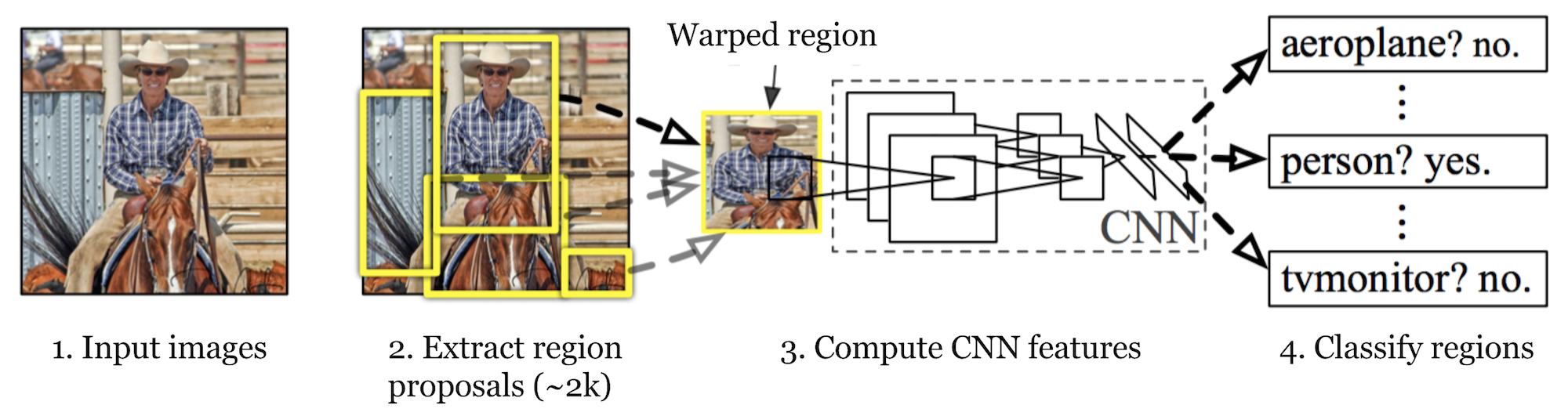
Fig. 1. R-CNN: n arkkitehtuuria. (Kuvan lähde: Girshick et al., 2014)
Model Workflow
How R-CNN works voidaan tiivistää seuraavasti:
- valmentaa CNN-verkkoa kuvien luokittelutehtävissä; esimerkiksi VGG tai ResNet koulutetaan ImageNet-aineistolla. Luokittelutehtävään kuuluu N-luokat.
HUOM: Caffe Model Zoosta löytyy ennalta koulutettu AlexNet. En usko, että sitä löytyy Tensorflow ’ sta, mutta TensorFlow-slim-mallikirjasto tarjoaa valmiiksi koulutetut ResNet, VGG ja muut.
- ehdottaa kategorisesti itsenäisiä kiinnostavia alueita valikoivalla haulla (~2k ehdokkaita kuvaa kohden). Näillä alueilla voi olla kohdekohteita ja ne ovat erikokoisia.
- Aluekandidaatit ovat vääntyneet CNN: n vaatimaan kiinteään kokoon.
- Jatka CNN: n vääntyneiden ehdotusalueiden hienosäätöä K + 1-luokille; ylimääräinen yksi luokka viittaa taustaan (ei kiinnostuksen kohteena). Hienosäätövaiheessa pitäisi käyttää paljon pienempää oppimistahtia ja mini-erä ylinäyttelee positiivisia tapauksia, koska useimmat ehdotetut alueet ovat vain taustatietoja.
- jokaisen kuva-alueen perusteella yksi eteenpäin etenemisestä CNN: n kautta tuottaa ominaisuusvektorin. Tämän ominaisuusvektorin kuluttaa sitten binäärinen SVM, joka on koulutettu kullekin luokalle itsenäisesti.
positiiviset näytteet ovat ehdotettuja alueita, joilla IoU (intersection over union) limittyy kynnysarvo >= 0,3, ja negatiiviset näytteet ovat merkityksettömiä muita. - lokalisointivirheiden vähentämiseksi regressiomalli koulutetaan korjaamaan ennustettu havaitsemisikkuna rajaavan laatikon korjaus offset käyttäen CNN: n ominaisuuksia.
Rajauslaatikon regressio
kun otetaan huomioon ennustettu rajauslaatikon koordinaatti \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (keskikoordinaatti, leveys, korkeus) ja sitä vastaavat maatotuuslaatikon koordinaatit \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , regressori on konfiguroitu oppimaan asteikko-invariantti muunnos kahden keskuksen välillä ja log-asteikon muunnos välillä leveyksiä ja korkeuksia. Kaikki muunnosfunktiot ottavat \(\mathbf{p}\) tulona.
\
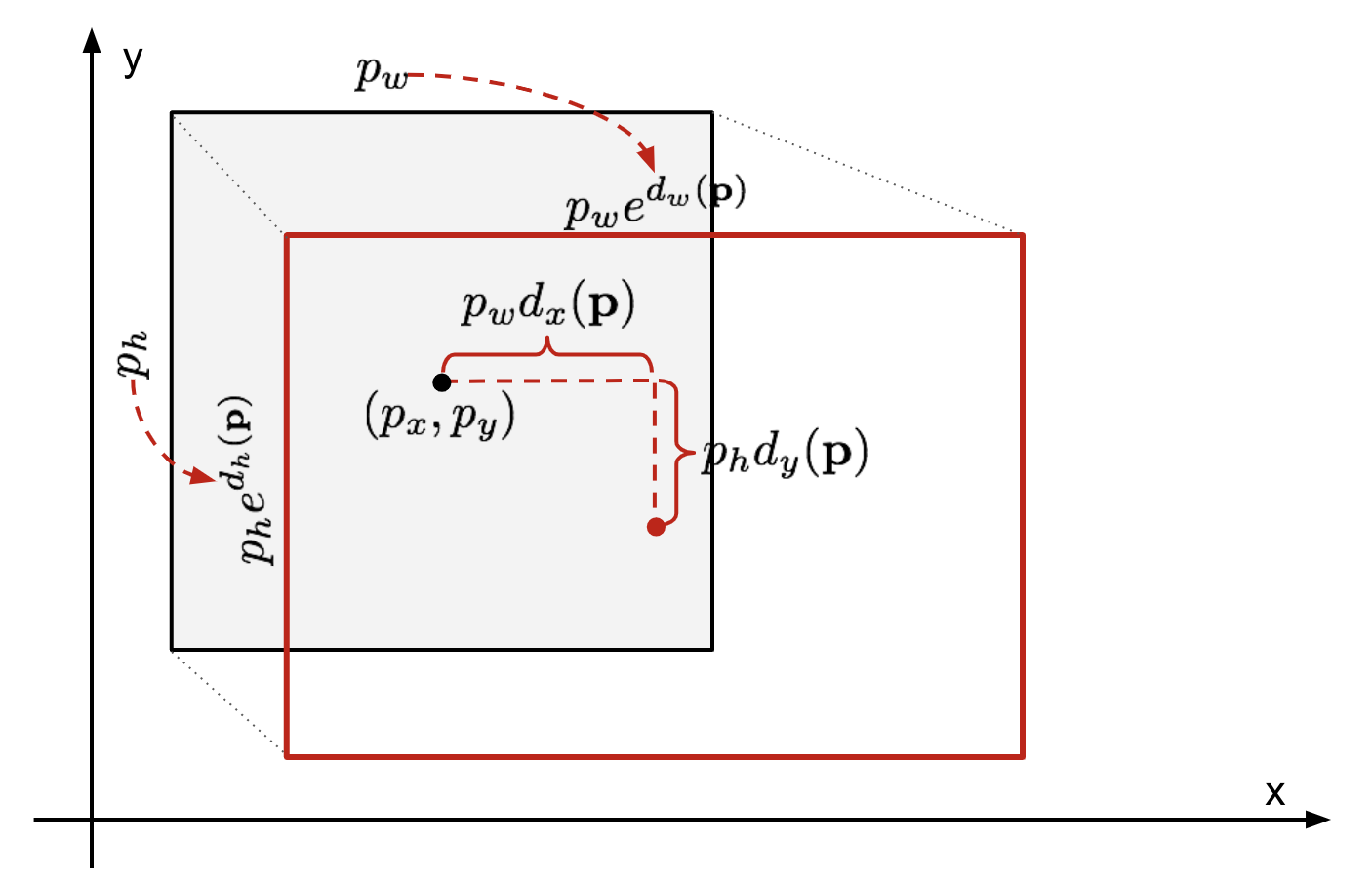
kuva. 2. Havainnekuva muunnoksesta ennustetun ja maahan totuuden rajaavat laatikot.
ilmeinen hyöty tällaisen muunnoksen soveltamisesta on, että kaikki rajaavan laatikon korjausfunktiot, \(d_i(\mathbf{p})\), missä \(i \in \{ x, y, w, h\}\), voivat ottaa minkä tahansa arvon välillä . Niiden oppimistavoitteet ovat:
\
standardiregressiomalli voi ratkaista ongelman minimoimalla SSE-häviön regularisoinnilla:
\
regularisointitermi on tässä kriittinen ja RCNN-paperi valitsi parhaan λ ristivalidoinnilla. Huomionarvoista on myös, että kaikissa ennustetuissa rajauslaatikoissa ei ole vastaavia maalaatikoita. Esimerkiksi, jos ei ole päällekkäisyyttä, se ei ole järkevää ajaa bbox regressio. Tässä, vain ennustettu laatikko lähellä ground truth box vähintään 0.6 IoU pidetään koulutusta bbox regressiomalli.
yleisiä temppuja
useita temppuja käytetään yleisesti RCNN: ssä ja muissa tunnistusmalleissa.
Ei-maksimaalinen suppressio
todennäköisesti malli pystyy löytämään samalle kohteelle useita rajauslaatikoita. Non-max-vaimennus auttaa välttämään saman esiintymän toistuvaa havaitsemista. Kun saamme joukon täsmääviä rajausruutuja samaan objektiluokkaan: Lajittele kaikki rajausruudut luottamuspisteiden mukaan.Hävitä laatikot, joiden luotettavuuspisteet ovat heikot.Vaikka rajauslaatikkoa on jäljellä, toista Seuraava:Valitse ahnaasti se, jolla on korkein pistemäärä.Ohita loput laatikot, joissa on korkea IoU (eli > 0,5), joissa on aiemmin valittu yksi.

Fig. 3. Useat rajauslaatikot havaitsevat kuvan auton. Kun ei-maksimaalinen tukahduttaminen, vain paras jää ja loput jätetään huomiotta, koska niillä on suuria päällekkäisyyksiä valitun kanssa. (Kuvan lähde: DPM-paperi)
kova negatiivinen louhinta
pidämme negatiivisina esimerkkeinä bounding boxeja, joissa ei ole esineitä. Kaikkia kielteisiä esimerkkejä ei ole yhtä vaikea tunnistaa. Esimerkiksi, jos siinä on puhdas tyhjä tausta, Se on todennäköisesti ”helppo negatiivinen”; mutta jos laatikko sisältää outoa meluisaa tekstuuria tai osittaista kohdetta, sitä voi olla vaikea tunnistaa ja nämä ovat ”kovia negatiivisia”.
kovat negatiiviset esimerkit luokitellaan helposti väärin. Voimme nimenomaan löytää nämä väärät positiiviset näytteet harjoitussilmukoiden aikana ja sisällyttää ne harjoitustietoihin luokittajan parantamiseksi.
nopeuden pullonkaula
r-CNN: n oppimisvaiheita tarkasteltaessa voisi helposti todeta, että R-CNN: n mallin koulutus on kallista ja hidasta, sillä seuraavat vaiheet vaativat paljon työtä:
- selektiivisen haun suorittaminen 2000 alueen ehdokkaan ehdottamiseksi jokaista kuvaa varten;
- CNN: n ominaisuusvektorin luominen jokaista kuva-aluetta varten (n images * 2000).
- koko prosessiin kuuluu kolme mallia erikseen ilman paljon yhteistä laskentaa: convolutionaalinen neuroverkko kuvan luokitteluun ja piirteiden poistoon, top SVM-luokittelija kohdeobjektien tunnistamiseen ja regressiomalli alueen rajauslaatikoiden kiristämiseen.
Fast R-CNN
R-CNN: n nopeuttamiseksi Girshick (2015) paransi harjoitusmenettelyä yhdistämällä kolme itsenäistä mallia yhdeksi yhteisesti koulutetuksi kehykseksi ja lisäämällä yhteisiä laskentatuloksia, jotka nimettiin Fast R-CNN: ksi. Sen sijaan, että CNN: n ominaisuusvektorit otettaisiin toisistaan riippumatta kullekin alueehdotukselle, tämä malli kokoaa ne yhteen CNN: n eteenpäin syöttämäksi koko kuvan päälle ja alueehdotukset jakavat tämän ominaisuusmatriisin. Sitten sama ominaisuus matriisi haarautuu käytettäväksi objektin luokittelijan ja bounding-box regressorin oppimiseen. Yhteenvetona, laskenta jakaminen nopeuttaa R-CNN.
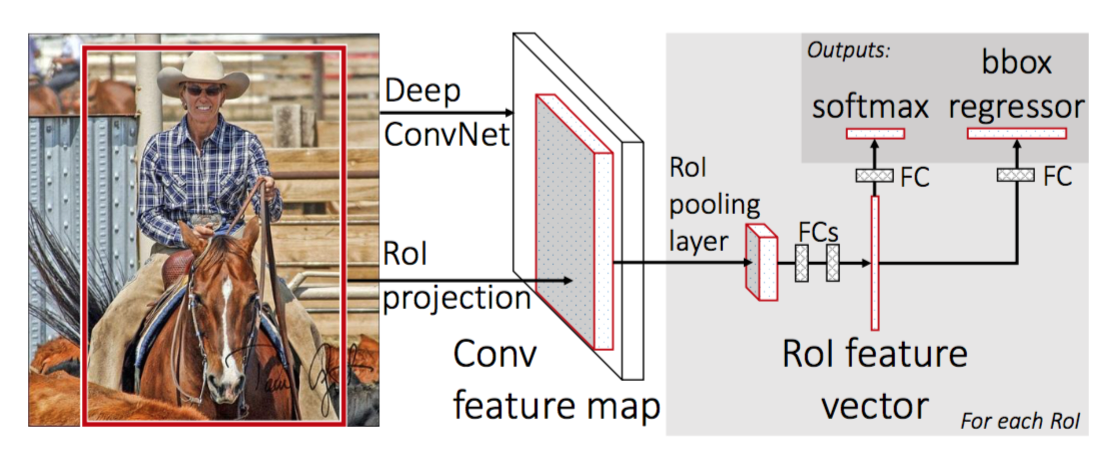
Fig. 4. Fast R-CNN: n arkkitehtuuri. (Kuvan lähde: Girshick, 2015)
RoI-Pooling
se on tyyppi max-pooling muuntaa ominaisuuksia projisoidun alueen kuvan tahansa koko, h x w, pieni kiinteä ikkuna, H x W. tuloalue on jaettu H x W ruudut, suunnilleen jokainen osa ikkunan koko H/H x w/W. sitten sovelletaan max-pooling kussakin ruudukossa.
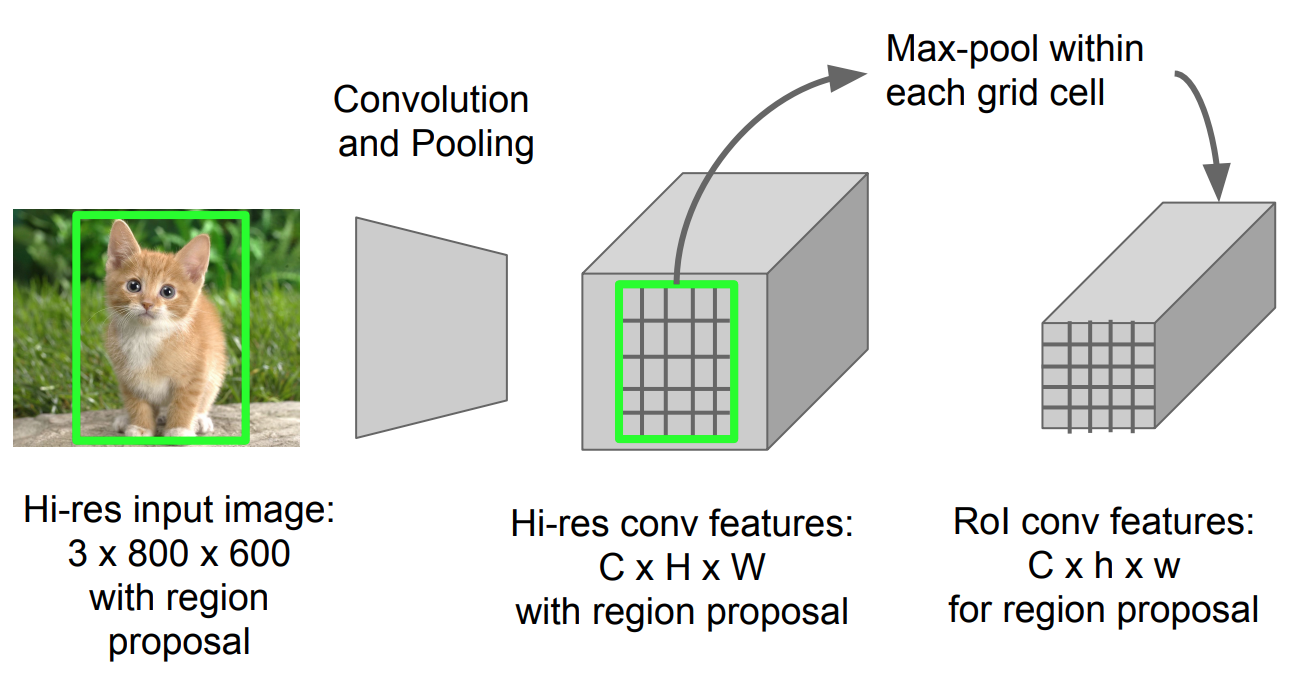
Fig. 5. RoI pooling (Kuvan lähde: Stanford CS231n slides.)
Model Workflow
how Fast R-CNN works on tiivistetty seuraavasti; monet vaiheet ovat samat kuin R-CNN:
- ensin koulutetaan konvolatiivista neuroverkkoa kuvanluokitustehtävissä.
- ehdottaa alueita valikoivalla haulla (~2k ehdokkaita kuvaa kohden).
- muuta ennalta koulutettu CNN:
- korvaa ennalta koulutetun CNN: n viimeinen Max-poolauskerros RoI-poolauskerroksella. RoI: n yhdistämiskerroksen tuotokset ovat kiinteämittaisia ja niissä on alueehdotusten vektoreita. CNN: n laskennan jakaminen käy järkeen, sillä monet samojen kuvien alueehdotukset ovat pitkälti päällekkäin.
- korvaa viimeinen täysin kytketty kerros ja viimeinen softmax-kerros (K-luokat) täysin liitetyllä kerroksella ja softmax K + 1-luokkien päällä.
- lopulta malli haarautuu kahdeksi lähtökerrokseksi:
- softmax-estimaattori K + 1-luokista (sama kuin R-CNN: ssä, +1 on ”tausta” – luokka), joka ulottaa diskreetin todennäköisyysjakauman RoI: ta kohti.
- bounding-box-regressiomalli, joka ennustaa jokaiselle K-luokalle poikkeamia suhteessa alkuperäiseen RoI: hen.
Häviöfunktio
malli on optimoitu kahta tehtävää (luokittelu + lokalisointi) yhdistävälle häviölle:
| symboli | selitys | True class label, \(u \in 0, 1, \Dots, k\); käytännön mukaan catch-all background-luokka on \(U = 0\). |
| \(p\) | diskreetti todennäköisyysjakauma (per RoI) K + 1-luokissa: \(p = (p_0, \dots, p_K)\), laskettuna softmax: lla täysin yhdistetyn kerroksen K + 1-lähdöistä. |
| \(v\) | True bounding box \(v = (v_x, v_y, v_w, v_h)\). |
| \(t^u\) | ennustettu rajauskentän korjaus, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Katso yllä. |
tappiofunktio summaa luokittelun ja bounding box-ennustuksen kustannukset: \(\mathcal{L} = \mathcal{l}_\text{cls} + \mathcal{l}_\text{box}\). ”Background” RoI: lle \(\mathcal{L}_\text{box}\) jätetään huomiotta indikaattorifunktio \(\mathbb{1} \), joka määritellään seuraavasti:
\ = \begin{cases} 1 & \text{if } u \geq 1\\ 0 & \text{otherwise}\end{cases}\]
yleinen häviöfunktio on:
\ \mathcal{L}_\text{box}(t^u, v) \\\mathcal{l}_\text{cls}(p, u) &= -\log p_u \\\mathcal{l}_\text{box}(t^u, v) &= \sum_{i \in \{x, y, w, h\}} l_1^\text{Smooth} (t^u_i – v_i)\end{align*}\]
rajaus laatikon häviö \(\mathcal{l}_{box}\) pitäisi mitata \(t^u_i\) ja \(v_i\) välinen erotus käyttämällä vankkaa häviöfunktiota. Tasainen L1-tappio hyväksytään tässä, ja sen väitetään olevan vähemmän herkkä poikkeaville arvoille.
\
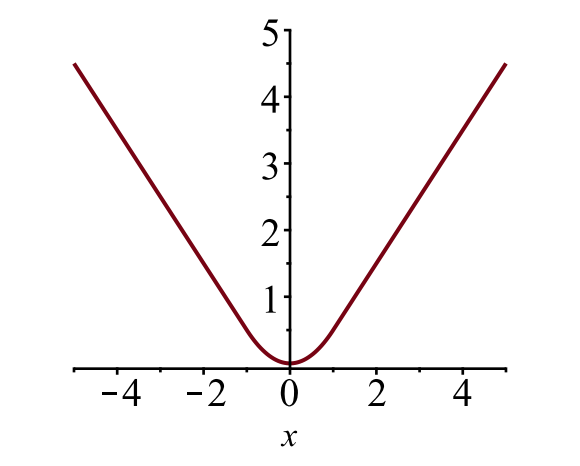
kuva. 6. Tasaisen L1-häviön juoni, \(y = l_1^\text{smooth} (x)\). (Kuvan lähde: linkki)
nopeuden pullonkaula
nopea R-CNN on paljon nopeampi sekä harjoitus-että testausajoissa. Parannus ei kuitenkaan ole dramaattinen, sillä maakuntaehdotukset syntyvät erikseen toisella mallilla ja se on hyvin kallista.
nopeampi R-CNN
intuitiivinen speedup-ratkaisu on integroida alueehdotuksen algoritmi CNN: n malliin. Faster R-CNN (Ren et al., 2016) tekee juuri näin: rakenna yksi, yhtenäinen malli, joka koostuu RPN: stä (region proposal network) ja nopeasta R-CNN: stä, jossa on jaetut convolutionaaliset ominaisuustasot.

Fig. 7. Kuvituskuva nopeammasta R-CNN-mallista. (Kuvan lähde: Ren et al., 2016)
Model Workflow
- Esijunttaa CNN-verkkoa kuvanluokitustehtävissä.
- hienosäätää RPN (region proposal network) päästä päähän region proposal-tehtävää varten, jonka junaa edeltävä kuvanluokittelija alustaa. Positiivisilla näytteillä on IoU (intersection-over-union) > 0, 7, kun taas negatiivisilla näytteillä on IoU < 0, 3.
- liu ’ uta pieni n x n – paikkaikkuna koko kuvan ominaisuuskartan päälle.
- jokaisen Liukuikkunan keskellä ennustamme samanaikaisesti useita eri asteikkojen ja suhdelukujen alueita. Ankkuri on yhdistelmä (liukuva ikkuna keskus, mittakaava, suhde). Esimerkiksi 3 asteikkoa + 3 suhdelukua = > k=9 ankkuria jokaisessa liukuasennossa.
- harjoittele nopeaa R-CNN-objektintunnistusmallia käyttäen nykyisen RPN: n
- tekemiä ehdotuksia ja käytä sitten nopeaa R-CNN-verkkoa RPN-koulutuksen alustamiseen. Säilyttäen jaetut convolutionaaliset kerrokset, vain hienosäätää RPN – erityisiä kerroksia. Tässä vaiheessa RPN ja detection network ovat jakaneet convolutionary kerrokset!
- lopuksi hienosäätää Fast R-CNN: n
- vaiheen 4-5 uniikit kerrokset voidaan tarvittaessa toistaa RPN: n ja Fast R-CNN: n kouluttamiseksi vaihtoehtoisesti.
Häviöfunktio
nopeampi R-CNN on optimoitu monitehtävien häviöfunktiolle samaan tapaan kuin nopea R-CNN.
| symboli | |
| \(p_i\) | ennustettu todennäköisyys, että ankkuri i on objekti. |
| \(p^*_i\) | Ground truth label (binäärinen) siitä, onko ankkuri i olio. |
| \(t_i\) | ennusti neljä parametroitua koordinaattia. |
| \(t^*_i\) | maanpinnan totuuskoordinaatit. |
| \(N_\text{cls}\) | Normalisointitermi, joka on asetettu paperille minieräkooksi (~256). |
| \(N_\text{box}\) | Normalisointitermi, asetetaan ankkuripaikkojen lukumääräksi (~2400) paperissa. |
| \(\lambda\) | tasapainoparametri, jonka arvo paperissa on ~10 (siten, että sekä \(\mathcal{L}_\text{cls}\) että \(\mathcal{L}_\text{box}\) termit painotetaan suurin piirtein tasan). |
monitehtävätappiofunktio yhdistää luokituksen häviöt ja bounding box-regression:
\
missä \(\mathcal{l}_\text{cls}\) on lokitappiofunktio kahden luokan yli, koska moniluokkaluokitus voidaan helposti kääntää binääriluokitukseksi ennustamalla näyte on kohde-objekti vastaan ei. \(L_1^\text{smooth}\) on sileä L1-häviö.
\
Mask R-CNN
Mask R-CNN (He et al., 2017) laajentaa nopeamman R-CNN: n pikselitason kuvan segmentointiin. Keskeistä on erottaa luokittelu ja pikselitason maskien ennustustehtävät toisistaan. Nopeamman R-CNN: n puitteiden perusteella se lisäsi kolmannen haaran objektin naamion ennustamiseen rinnakkain nykyisten haarojen luokittelua ja lokalisointia varten. Naamiohaara on jokaiseen RoI: iin sovellettava pieni täysin kytketty verkko, joka ennustaa segmentointimaskin pikselien tarkkuudella.
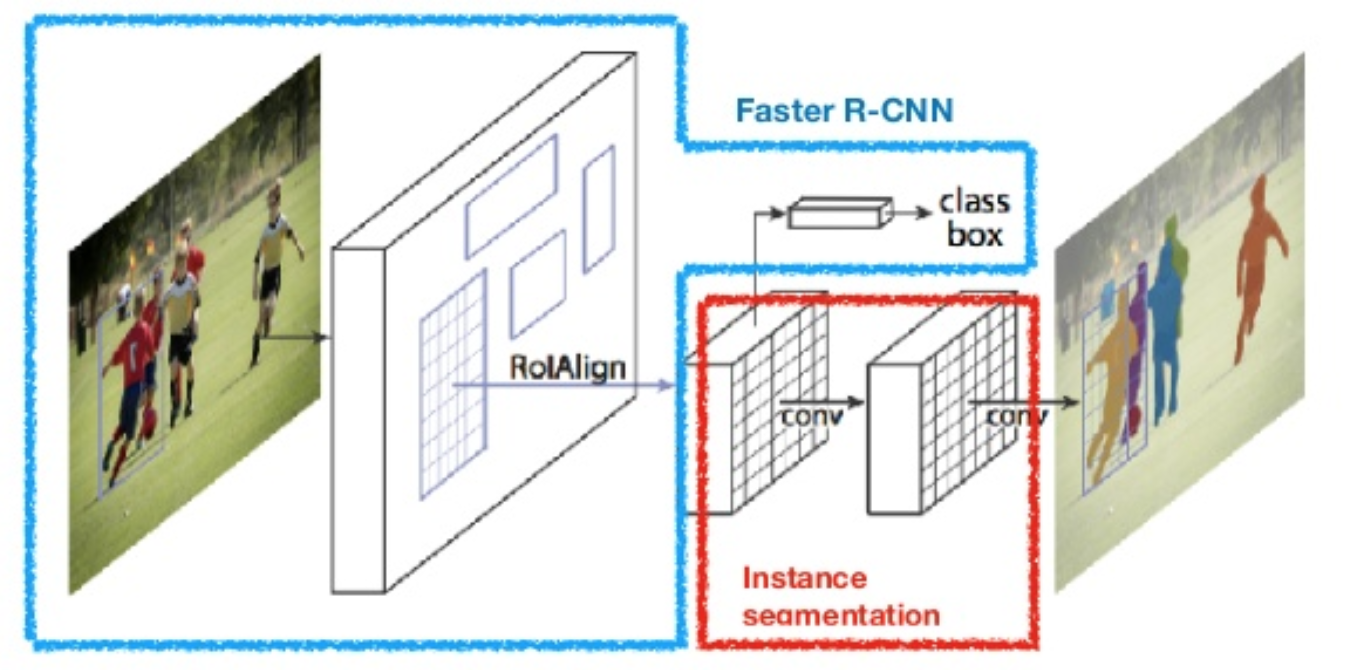
kuva. 8. Mask R-CNN on nopeampi R-CNN-malli, jossa on kuvan segmentointi. (Kuvan lähde: He et al., 2017)
koska pikselitason segmentointi vaatii paljon hienorakeisempaa kohdistusta kuin rajauslaatikot, mask R-CNN parantaa RoI-yhdistämiskerrosta (nimeltään ”RoIAlign layer”), jotta RoI voidaan paremmin ja tarkemmin kartoittaa alkuperäisen kuvan alueille.

Fig. 9. Mask R-CNN: n ennustuksia COCO-testisarjasta. (Kuvan lähde: He et al., 2017)
RoIAlign
RoIAlign-kerros on suunniteltu korjaamaan kvantisoinnin aiheuttamaa sijaintivirhettä RoI-poolauksessa. RoIAlign poistaa hash-kvantisoinnin esimerkiksi käyttämällä x / 16: ta sijasta , jotta uutetut ominaisuudet voidaan kohdistaa oikein syöttöpikseleihin. Bilineaarista interpolointia käytetään syötteen liukulukujen sijaintiarvojen laskemiseen.
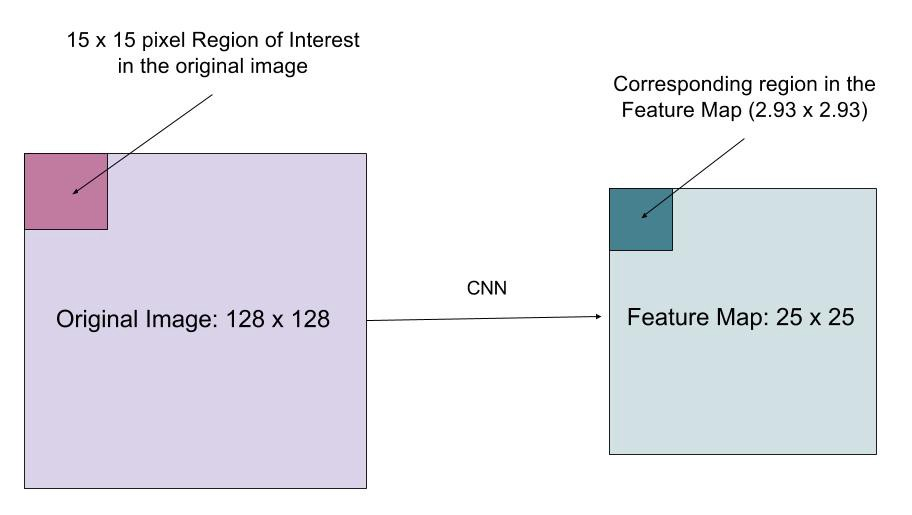
Fig. 10. Kiinnostava alue kartoitetaan tarkasti alkuperäisestä kuvasta ominaisuuskartalle pyöristämättä kokonaislukuihin. (Kuvan lähde: linkki)
Häviöfunktio
Mask R-CNN: n monitehtävän häviöfunktio yhdistää luokituksen, lokalisoinnin ja segmentoinnin häviön: \(\mathcal{L} = \mathcal{L}_\text{CLS} + \mathcal{l}_\text{mask}\), missä\(\mathcal{L}_\text{cls}\) ja\(\mathcal{l}_\text{l}_\text{cls}\)}\) ovat samat kuin nopeammassa R-CNN: ssä.
naamiohaara tuottaa jokaiselle RoI: lle ja jokaiselle luokalle ulottuvuuden m x m mukaisen maskin; k-luokat yhteensä. Täten kokonaistuotos on kooltaan \(K \cdot m^2\). Koska malli yrittää opetella jokaiselle luokalle naamion, luokkien välillä ei ole kilpailua naamioiden tuottamisesta.
\(\mathcal{L}_\text{mask}\) määritellään keskimääräiseksi binääriseksi ristiytymishäviöksi, vain K-TH-maski mukaan luettuna, jos alue liittyy maatotuusluokkaan k.
\\]
missä \(y_{ij}\) on solun (i, j) merkki todellisessa maskissa alueella, jonka koko on m x m; \(\hat{y}_{ij}^k\) on saman solun ennustettu arvo maskissa oppinut maahan-totuus luokka k.
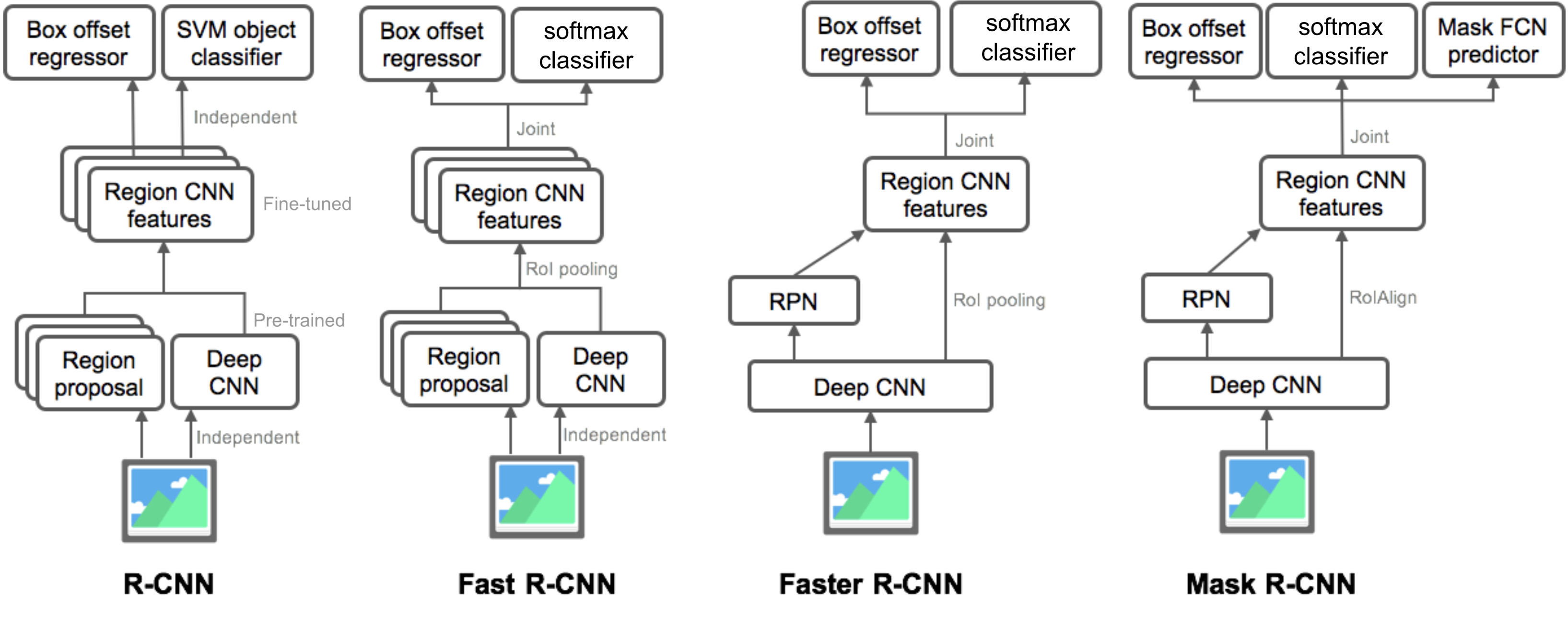
Yhteenveto R-CNN-perheen malleista
tässä havainnollistan R-CNN: n, Fast R-CNN: n, Faster R-CNN: n ja Mask R-CNN: n mallipiirustuksia. Pieniä eroja vertaamalla voi seurata, miten yksi malli kehittyy seuraavaan versioon.
Cited as:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}Reference
Ross Girshick, Jeff Donahue, Trevor Darrell ja Jitendra Malik. ”Rikas ominaisuus hierarkiat tarkka objektin havaitseminen ja semanttinen segmentointi.”Proc. IEEE Conf. on computer vision and pattern recognition (cvpr), s.580-587. 2014.
Ross Girshick. ”Fast R-CNN.”Proc. IEEE Intl. Conf. on computer vision, s. 1440-1448. 2015.
Shaoqing Ren, Kaiming He, Ross Girshick ja Jian Sun. ”Faster R-CNN: Towards real-time object detection with region proposal networks.”In Advances in neural information processing systems (NIPS), s.91-99. 2015.
Kaiming He, Georgia Gkioxari, Piotr Dollár ja Ross Girshick. Mask R-CNN.”arxiv preprint arXiv: 1703.06870, 2017.
Joseph Redmon, Santosh Divvala, Ross Girshick ja Ali Farhadi. ”Katsot vain kerran: yhtenäinen, reaaliaikainen objektin havaitseminen.”Proc. IEEE Conf. on computer vision and pattern recognition (cvpr), s.779-788. 2016.
Athelasin ”A Brief History of Cnns in Image segregation: From R-CNN to Mask R-CNN”.
Tasainen L1-häviö: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf