Papa-smear-analyysityökalu (Pat) kohdunkaulan syövän toteamiseksi pap-smear-kuvista
Kuvaanalyysi
kuvaanalyysiputki Papa-smear-analyysityökalun kehittämiseksi kohdunkaulan syövän toteamiseksi pap-smear-sivuista on kuvattu kuvassa. 1.

lähestymistapa kohdunkaulan syövän toteamiseen Papa-smear-kuvista
Image acquisition
lähestymistapaa arvioitiin käyttäen kolmea tietokokonaisuuksia. Aineisto 1 koostuu 917 yksittäisestä solusta Harlev pap-smear-kuvia, jotka on valmistanut Jantzen et al. . Aineisto sisältää Papa-smear-kuvia, jotka ammattitaitoiset sytopatologit ovat ottaneet 0,201 µm/pikselin resoluutiolla käyttäen kehyskouruun kytkettyä mikroskooppia. Kuvat segmentoitiin käyttäen CHAMP – kaupallista ohjelmistoa ja luokiteltiin sen jälkeen seitsemään luokkaan, joilla on erilliset ominaisuudet taulukossa 2 esitetyllä tavalla. Näistä 200 kuvaa käytettiin koulutukseen ja 717 kuvaa testaukseen.
tietokokonaisuus 2 koostuu 497 full slide pap-smear-kuvasta, jotka on valmistanut Norup et al. . Näistä 200 kuvaa käytettiin koulutukseen ja 297 kuvaa testaukseen. Lisäksi luokittajan suorituskykyä arvioitiin Mbarara Regional Referral Hospital (MRRH)-sairaalasta saatujen 60 Papa-smear-näytteen (30 normaalia ja 30 epänormaalia) aineiston 3 perusteella. Näytteet kuvattiin Olympus bx51-kirkkaankenttämikroskoopilla, joka oli varustettu 40× 0,95 NA-objektiivilla ja Hamamatsu ORCA-05G 1,4 Mpx-yksivärikameralla, jolloin pikselikoko oli 0,25 µm ja syvyys 8-bittinen harmaa. Tämän jälkeen jokainen kuva jaettiin 300 alueeseen, joissa kussakin oli 200-400 solua. Sytopatologien lausuntojen perusteella valittiin 10 000 objektia kuvista, jotka oli saatu 60: stä erilaisesta Papa-smear-diasta, joista 8000 oli vapaasti makaavia kohdunkaulan epiteelisoluja (3000 normaalia solua normaaleista smeareista ja 5000 epänormaalia solua epänormaaleista smeareista) ja loput 2000 olivat roskakohteita. Tämä Pap-smear-segmentointi saavutettiin käyttämällä koulutettavaa Weka-Segmentointityökalupakettia pikselitason segmentointiluokittelijan muodostamiseksi.
kuvanparannus
harmaasävykuvaan sovellettiin kontrastin paikallista adaptiivista histogrammin tasausta (CLAHE) kuvanparannusta varten . KLAHESSA on ensiarvoisen tärkeää valita klipsiraja, joka määrittää kuvan histogrammin halutun muodon, sillä se vaikuttaa kriittisesti parannetun kuvan laatuun. Klipsirajan optimaalinen arvo valittiin empiirisesti Joseph et al: n määrittelemällä menetelmällä. . Optimaalinen leikkeen raja-arvo on 2.0 todettiin asianmukaiseksi, jotta voidaan tarjota riittävä kuvanparannus säilyttäen kuitenkin käytettyjen aineistojen pimeät ominaisuudet. Muunnos harmaasävyyn saavutettiin Harmaasävytekniikalla, joka toteutettiin Eq: n avulla. 1 kuten määritelty .
missä r = Punainen, g = vihreä ja B = sininen väri vaikuttavat uuteen kuvaan.
CLAHEN käyttö kuvanparannukseen aiheutti kuviin havaittavia muutoksia säätämällä kuvanvahvuuksia, joissa tumakkeen tummuminen sekä sytoplasman rajat tulivat helposti tunnistettaviksi klipsirajan 2.0 avulla.
Kohtaussegmentaatio
kohtaussegmentoinnin saavuttamiseksi kehitettiin pikselitasoluokittelija, joka käytti Trainable Weka segregation (TWS) – työkalupakkia. Suurin osa papa-kokeessa havaituista soluista ei ole yllättäen kohdunkaulan epiteelisoluja . Lisäksi leukosyyttien, erytrosyyttien ja bakteerien määrä vaihtelee yleensä, kun taas pieniä määriä muita kontaminoivia soluja ja mikro-organismeja havaitaan joskus. Papa-preparaatti sisältää kuitenkin neljää päätyyppiä okasoluja-pinnallisia, väli—, parabasaali-ja basaalisoluja-joista pinnalliset ja väli-solut edustavat ylivoimaista enemmistöä tavanomaisessa preparaatissa; näin ollen näitä kahta tyyppiä käytetään yleensä tavanomaisessa pap-preparaatti-analyysissä . Harjoiteltavaa Weka-segmentointia käytettiin liukumäen eri kohteiden tunnistamiseen ja segmentointiin. Tässä vaiheessa pikselitason luokittelijaa koulutettiin solujen tumien, sytoplasman, taustan ja roskien tunnistamiseen ammattitaitoisen sytopatologin avulla käyttäen koulutettavaa Weka segregation (TWS) – työkalupakkia . Tämä saavutettiin piirtämällä viivat / valinta kiinnostavien alueiden läpi ja osoittamalla ne tiettyyn luokkaan. Viivojen/valinnan alla olevien pikselien katsottiin edustavan ytimiä, sytoplasmaa, taustaa ja roskia.
kunkin luokan sisällä piirrettyjen ääriviivojen avulla luotiin ominaisuusvektori \(\mathop F\limits^{ \to}\), joka johdettiin kuhunkin ääriviivaan kuuluvien pikselien lukumäärästä. Kunkin kuvan ominaisuusvektori (200 aineistosta 1 ja 200 aineistosta 2) määriteltiin Eq: lla. 2.
missä Ni, Ci, Bi ja Di ovat kuvan \(i\) ytimen pikselien lukumäärä, sytoplasma, tausta ja roskat kuten kuvassa. 2.

ominaisuusvektorin generointi harjoituskuvista
jokainen kuvasta poimittu pikseli edustaa intensiteettinsä lisäksi kuvakokonaisuutta, joka sisältää paljon tietoa, mukaan lukien rakenne, rajat ja väri pikselin alueella 0,201 µm2. Sopivan ominaisuusvektorin valitseminen luokittelijan kouluttamiseksi oli suuri haaste ja uusi tehtävä ehdotetussa lähestymistavassa. Pixel-tason luokittaja koulutettiin käyttäen yhteensä 226 TWS: n koulutustoimintoa. Luokittaja koulutettiin käyttämällä TWS-koulutusominaisuuksien sarjaa, johon kuului: (I) melun vähentäminen: TWS-työkalupakin Kuwahara-ja kahdenvälisiä suodattimia käytettiin luokittajan kouluttamiseen melun poistoon. Näiden on raportoitu olevan erinomaisia suodattimia melun poistamiseen säilyttäen reunat, (ii) reunojen havaitseminen: Sobel-suodatinta, Hessenin matriisia ja Gabor-suodatinta käytettiin luokittajan kouluttamiseen rajanilmaisussa kuvassa ja (iii) tekstuurin suodatus: Tekstuurisuodatuksessa käytettiin keskiarvo -, varianssi -, mediaani -, maksimi -, minimi-ja entropiasuodattimia.
Roskien poisto
pääsyy monien olemassa olevien automatisoitujen Papa-smear-analysointijärjestelmien nykyisiin rajoituksiin on se, että ne pyrkivät voittamaan pap-smear-rakenteiden monimutkaisuuden yrittämällä analysoida liukumäkeä kokonaisuutena, joka usein sisältää useita soluja ja roskia. Tämä voi aiheuttaa algoritmin epäonnistumisen ja vaatii suurempaa laskentatehoa . Näytteet ovat peittyneet esineisiin—kuten verisoluihin, päällekkäisiin ja taitettuihin soluihin sekä bakteereihin-jotka haittaavat segmentointiprosesseja ja tuottavat suuren määrän epäilyttäviä esineitä. On osoitettu, että luokittelijat, jotka on suunniteltu erottamaan normaalit solut ja syöpäsoluja edeltävät solut, tuottavat yleensä arvaamattomia tuloksia, kun papa-kokeessa on artefakteja . Tässä työkalussa, tekniikka tunnistaa kohdunkaula soluja käyttämällä kolmivaiheinen vaiheittainen poistaminen järjestelmä (kuvattu kuvassa. 3) käytetään.

kolmivaiheinen vaiheittainen eliminaatiomenetelmä roskien hylkäämiseen
ehdotettu kolmivaiheinen eliminaatiomenetelmä poistaa roskat vaiheittain Papa-kokeesta, jos ei todennäköisesti kohdunkaulasolu. Tämä lähestymistapa on hyödyllinen, koska se mahdollistaa alemman ulottuvuuden päätös tehdään kussakin vaiheessa.
Kokoanalyysi
kokoanalyysi on joukko menetelmiä, joilla määritetään hiukkasten kokoalue . Alue on yksi keskeisimmistä ominaisuuksista, joita käytetään automatisoidun sytologian alalla erottamaan soluja roskista. Papa-smear-analyysi on hyvin tutkittu ala, jolla on paljon aiempaa tietoa solujen ominaisuuksista . Yksi keskeisistä muutoksista tuman alueen arvioinnissa on kuitenkin se, että syöpäsolut käyvät läpi merkittävän kasvun ydinkoossa . Siksi ylemmän koon kynnysarvon määrittäminen, joka ei järjestelmällisesti sulje pois diagnostisia soluja, on paljon vaikeampaa, mutta sen etuna on hakuavaruuden pienentäminen. Tässä asiakirjassa esitetty menetelmä perustuu kohdunkaulan solujen pienempään kokoon ja ylempään kokokynnykseen. Lähestymistavan pseudokoodi näkyy Eq: ssa. 3.
missä \(Area_{max} = 85,267\, {\\upmu\ text{m}}^{2}\) ja\(Area_{min} = 625\, {\upmu\ text{m}}^{2}\) johdettu taulukosta 2.
taustalla olevia esineitä pidetään roskina ja näin ne heitetään pois kuvasta. Hiukkasia, jotka sijoittuvat \(Area_{min}\) ja \(Area_{max}\) välille, analysoidaan edelleen tekstuuri-ja muotoanalyysin seuraavissa vaiheissa.
Muotoanalyysi
papa-kokeessa kappaleiden muoto on keskeinen piirre solujen ja roskien erilaistumisessa . Muotokuvauksen havaitsemiseen on useita menetelmiä, joita ovat muun muassa alue-ja ääriviivapohjaiset lähestymistavat . Aluepohjaiset menetelmät ovat vähemmän herkkiä melulle mutta laskennallisesti intensiivisempiä, kun taas ääriviivat perustuvat menetelmät ovat suhteellisen tehokkaita laskea mutta herkempiä melulle . Tässä paperissa on käytetty aluepohjaista menetelmää (perimeter2 / area (P2A)). P2A-asiasana valittiin sillä ansiolla, että se kuvaa objektin samankaltaisuutta ympyrän kanssa. Tämän vuoksi se soveltuu hyvin solun tuman kuvaajaksi, sillä tumat ovat yleensä ulkonäöltään pyöreitä. P2A kutsutaan myös muodon tiiviys ja määritellään Eq. 4.
missä c on muodon tiiviyden arvo, A on pinta-ala ja p on ytimen kehä. Roskien oletettiin olevan esineitä, joiden P2A-arvo on suurempi kuin 0,97 tai pienempi kuin 0,15 harjoitusominaisuuksien mukaan (kuvattu taulukossa 2).
Tekstuurianalyysi
tekstuuri on erittäin tärkeä ominaispiirre, joka voi erottaa ytimet ja roskat toisistaan. Image texture on joukko mittareita, joiden tarkoituksena on määrittää kuvan koettu rakenne . Pap-smear-kokeessa ydintahran keskimääräisen intensiteetin jakauma on paljon kapeampi kuin roskakohteiden välinen tahran intensiteetin vaihtelu . Tätä seikkaa käytettiin pohjana roskien poistamiseen niiden kuvanvahvuuden ja väritietojen perusteella Zernike Momentsin (ZM) avulla . Zernike moments käytetään erilaisia kuviotunnistus sovelluksia ja tiedetään olevan vankka suhteen melua ja on hyvä jälleenrakennusteho. Tässä työssä, ZM esittämä Malm et al. kertaluvun n kanssa toiston I funktio \(f\left ({r,\theta } \right)\), napakoordinaateissa levyn sisällä keskipisteenä neliön kuva \(I\left( {x, y} \right)\) koko \(M \times m\), jonka Eq. Käytettiin 5.
\(v_{nl }^{*} \left( {r,\Theta } \right)\) tarkoittaa zerniken polynomin kompleksikonjugaattia \(V_{nl} \Left( {R,\Theta } \right)\). Tekstuurimittauksen tuottamiseksi lasketaan keskiarvona magnitudit kohteesta \(a_{nl}\), jonka keskipisteenä on tekstuurikuvan jokainen pikseli .
Feature extraction
luokittelualgoritmin onnistuminen riippuu suuresti kuvasta poimittujen ominaisuuksien oikeellisuudesta. Aineiston Papa-smeareissa olevat solut jaetaan seitsemään luokkaan sellaisten ominaisuuksien perusteella kuin tuman koko, pinta-ala, muoto ja kirkkaus sekä sytoplasma. Kuvista poimitut ominaisuudet sisälsivät muiden aiemmin käyttämiä morfologisia piirteitä . Tässä asiakirjassa kolme geometrisia ominaisuuksia (kiinteys, tiiviys ja eksentrisyys) ja kuusi tekstuaalisia ominaisuuksia (keskiarvo, keskihajonta, varianssi, tasaisuus, Energia ja entropia) oli myös uutettu ydin, jolloin 29 ominaisuuksia yhteensä kuten taulukossa 3.
Ominaisuusvalinta
Ominaisuusvalinta on prosessi, jossa valitaan poimittujen ominaisuuksien osajoukot, jotka antavat parhaat luokitustulokset. Niistä ominaisuuksia uutettu, jotkut saattavat sisältää melua, kun taas valittu luokittelija ei saa käyttää muita. Siksi on määritettävä optimaalinen joukko ominaisuuksia, mahdollisesti kokeilemalla kaikkia yhdistelmiä. Kun ominaisuuksia on paljon, mahdolliset yhdistelmät kuitenkin räjähtävät lukumääräisesti ja tämä lisää algoritmin laskennallista monimutkaisuutta. Ominaisuusvalinta-algoritmit luokitellaan laajasti suodattimeen, kääreeseen ja sulautettuihin menetelmiin .
työkalun käyttämä menetelmä yhdistää simuloidun hehkutuksen käärintätapaan. Tätä lähestymistapaa on ehdotettu, mutta tässä asiakirjassa ominaisuusvalinnan toimivuutta arvioidaan käyttämällä kaksoisstrategista satunnaista metsäalgoritmia . Simuloitu hehkutus on probabilistinen tekniikka, jolla lähestytään tietyn toiminnon globaalia optimia. Lähestymistapa sopii hyvin varmistamaan, että optimaalinen joukko ominaisuuksia on valittu. Optimaalisen sarjan etsimistä ohjaa kuntoarvo . Kun simuloitu hehkutus on valmis, kaikkia eri ominaisuuksien osajoukkoja verrataan ja fittest (eli se, joka suorittaa parhaiten) valitaan. Kuntoarvohaku saatiin kääreellä, jossa luokittelualgoritmin virheen laskemiseen käytettiin k-kertaista ristivalidointia. Erotetuista ominaisuuksista erilaisia yhdistelmiä valmistetaan, arvioidaan ja verrataan muihin yhdistelmiin. Ennustemallia käytetään sitten ominaisuuksien yhdistelmän arviointiin ja pisteytyksen antamiseen mallin tarkkuuden perusteella. Kääreen antamaa kuntovirhettä käytetään simuloidun hehkutusalgoritmin kuntovirheenä. Sumea C-means-algoritmi käärittiin mustaan laatikkoon,josta saatiin arvioitu virhe eri ominaisuusyhdistelmille kuten kuvassa. 4.

sumea C-means on kääritty mustaan laatikkoon, josta saadaan estimoitu virhe
sumea C-means mahdollistaa datapisteet tietokokonaisuus kuuluu kaikkiin klustereihin, jäsenyydet väli (0-1) kuten EQ. 6.
missä \(M_{ik}\) on jäsenyys datakeskukselle k klusterikeskukseen i, \(d_{JK}\) on etäisyys klusterikeskuksesta j datakeskukseen K ja q € on eksponentti, joka päättää, kuinka vahvoja jäsenyyksien tulee olla. Fuzzy C-means-algoritmi toteutettiin käyttäen fuzzy Toolboxia Matlabissa.
defuzzification
sumea C-means-algoritmi ei kerro, mitä tietoja klusterit sisältävät ja miten näitä tietoja käytetään luokittelussa. Siinä kuitenkin määritellään, miten datapisteille annetaan eri klustereiden jäsenyys ja tätä sumeaa jäsenyyttä käytetään tietopisteen luokan ennustamiseen . Tämä on voitettu defuzzification. Useita defuzzification menetelmiä on olemassa . Tässä työkalussa jokaisella klusterilla on kuitenkin sumea jäsenyys (0-1) kaikista kuvan luokista. Koulutustiedot osoitetaan sitä lähimmälle klusterille. Kunkin klusteriin a kuuluvan luokan koulutustietojen prosentuaalinen osuus antaa klusterin jäsenyyden, klusteri a = eri luokkiin, missä i on klusterin A ja J eristäminen toisessa klusterissa. Intensiteettimitta lisätään kunkin klusterin jäsenyysfunktioon sumealla ryhmittelyalgoritmilla. Suosittu lähestymistapa sumean osion defuzzifiointiin on enimmäisjäsenyysasteperiaatteen soveltaminen, jossa datapiste k on määritetty luokkaan m, Jos ja vain jos sen jäsenyysaste \(M_{ik}\) klusteriin i, on suurin. Chuang ym. ehdotettu säätämällä jäsenyyden tila jokaisen datapisteen käyttäen jäsenyyden tilan naapureita.
ehdotetussa lähestymistavassa käytetään bayesilaiseen todennäköisyyteen perustuvaa defuzzifikaatiomenetelmää, jolla luodaan todennäköisyysfunktion malli kullekin datapisteelle ja sovelletaan mallia kuvaan luokittelutiedon tuottamiseksi. Todennäköisyysjakauma lasketaan seuraavasti:
-
Muunna partikulaarimatriisin (klustereiden) mahdollisuusjakaumat todennäköisyysjakaumiksi.
-
konstruoi datajakaumien todennäköisyysmalli kuten in .
-
sovelletaan mallia, jossa jokaisen tietopisteen luokitustiedot tuotetaan Eq: n avulla. 7.
p > missä \(p\left( {a_{I} } \right),I = 0 \ldots .c\) on \(a_{i}\): n edeltävä todennäköisyys, joka voidaan laskea menetelmällä, jossa edeltävä todennäköisyys on aina verrannollinen kunkin luokan massaan.
käytettävien klustereiden määrä määritettiin, jotta rakennetulla mallilla pystyttäisiin kuvaamaan aineistoa parhaalla mahdollisella tavalla. Jos valitaan liian monta klusteria, vaarana on, että melun määrä ylittää datan. Jos klustereita valitaan liian vähän, tuloksena voi olla huono luokittelija. Sen vuoksi klusterien lukumäärää analysoitiin ristivalidointitestivirheen perusteella. Optimaalinen määrä 25 klusteria saavutettiin, ja ylikoulutusta tapahtui näiden klusterimäärien yläpuolella. Defuzzification eksponentti 1.0930 saatiin 25 klusterin, kymmenkertaisen ristiintarkistuksen ja 60 uusinnan avulla ja sitä käytettiin ominaisuuksien valinnan kuntovirheen laskemiseen, jossa luokittajan rakentamiseen valittiin yhteensä 18 ominaisuutta 29 ominaisuudesta. Valitut ominaisuudet olivat: tuman alue; tuman harmaa taso; tuman Lyhin halkaisija; tuman pisin; tuman kehä; maksimit tumassa; minimit tumassa; sytoplasman alue; sytoplasman harmaa taso; sytoplasman kehä; tuman ja sytoplasman suhde; tuman eksentrisyys, tuman keskihajonta, tuman harmaa taso varianssi; tuman harmaa taso entropia; ytimen suhteellinen sijainti; ytimen harmaa taso keskiarvo ja ytimen harmaa arvot energiaa.
Luokitteluarviointi
tässä asiakirjassa frybackin ja Thornburyn ehdottama hierarkkinen malli diagnostisten kuvantamisjärjestelmien tehokkuudesta hyväksyttiin ohjaavaksi periaatteeksi työkalun arvioinnissa taulukon 4 mukaisesti.
herkkyys mittaa todellisten positiivisten osuutta, jotka tunnistetaan oikein sellaisiksi, kun taas spesifisyys mittaa todellisten negatiivien osuutta, jotka tunnistetaan oikein sellaisiksi. Herkkyyttä ja spesifisyyttä kuvataan Eq: lla. 8.
missä TP = True positives, FN = False negatives, TN = True negatives and FP = False positives.
GUI: n suunnittelu ja integrointi
edellä kuvatut kuvankäsittelymenetelmät on toteutettu Matlabissa ja ne on toteutettu Fig: ssä esitetyn Java-graafisen käyttöliittymän (GUI) kautta. 5. Työkalussa on paneeli, jossa Pap-smear-kuva ladataan ja sytotechnician valitsee sopivan menetelmän kohtauksen segmentointiin (perustuu TWS-luokittelijaan), roskien poistoon (perustuu kolmeen peräkkäiseen eliminointimenetelmään) ja rajojen havaitsemiseen (jos katsotaan tarpeelliseksi, käyttäen Canny edge detection-menetelmää), jonka jälkeen ominaisuudet uutetaan uutteen Ominaisuudet-painiketta käyttäen.
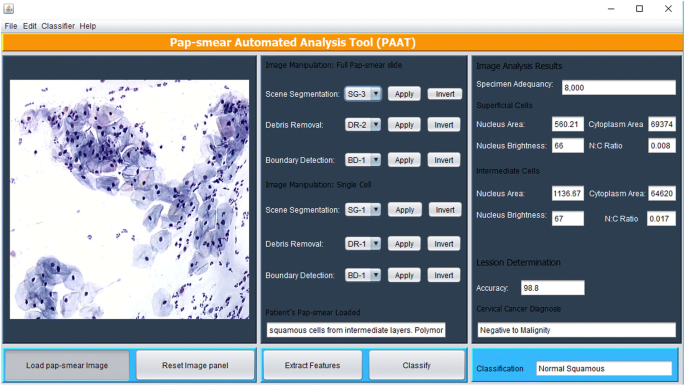
Pat graafinen käyttöliittymä
työkalu skannaa pap-kokeen läpi analysoidakseen kaikki esineet, jotka jäivät jäljelle roskien poiston jälkeen. Ominaisuusvalinnassa kuvatut 18 ominaisuutta poimitaan jokaisesta oliosta ja niitä käytetään luokittelemaan jokainen solu käyttäen luokittelumenetelmässä kuvattua sumeaa C-means-algoritmia. Yhden pinnallisen solun ja yhden välisolun poimitut ominaisuudet näkyvät satunnaisesti kuva-analyysin tulospaneelissa. Kun ominaisuudet on poistettu, sytoteknikko (käyttäjä) painaa luokittelupainiketta ja työkalu lähettää diagnoosin (positiivinen malignity tai negatiivinen malignity) ja luokittelee diagnoosin johonkin 7 luokkaan/vaiheeseen kohdunkaulan syöpä kohti koulutusaineistoa.