Regressiopuut
kaikki regressiotekniikat sisältävät yhden lähtömuuttujan (vastemuuttujan) ja yhden tai useamman syöttömuuttujan (predikaattorin). Lähtömuuttuja on numeerinen. Yleisen regressiopuunrakennusmenetelmän avulla syöttömuuttujat voivat olla jatkuvien ja kategoristen muuttujien sekoitus. Ratkaisupuu syntyy, kun jokainen puun ratkaisusolmu sisältää testin jonkin tulomuuttujan arvosta. Puun pääteolmut sisältävät ennustetut lähtömuuttujan arvot.
Regressiopuuta voidaan pitää ratkaisupuiden muunnoksena, jonka tarkoituksena on likimääraistaa reaaliarvoisia funktioita sen sijaan, että sitä käytettäisiin luokittelumenetelmissä.
metodologia
regressiopuu rakennetaan binääriseksi rekursiiviseksi osioinniksi kutsutun prosessin kautta, joka on iteratiivinen prosessi, jossa data jaetaan osioihin tai haaroihin ja sitten jatketaan kunkin osion jakamista pienempiin ryhmiin menetelmän edetessä jokaista haaraa ylöspäin.
aluksi kaikki koulutussarjan tietueet (ennalta luokitellut tietueet, joita käytetään puun rakenteen määrittämiseen) on ryhmitelty samaan osioon. Tämän jälkeen algoritmi alkaa jakaa dataa kahteen ensimmäiseen osioon tai haaraan käyttäen jokaista mahdollista binäärijakoa jokaisessa kentässä. Algoritmi valitsee jaon, joka minimoi potenssiin laskettujen poikkeamien summan kahden erillisen osion keskiarvosta. Tätä jakosääntöä sovelletaan sitten jokaiseen uuteen haaraan. Tämä prosessi jatkuu, kunnes jokainen solmu saavuttaa käyttäjän määrittämän solmun vähimmäiskoon ja muuttuu päätepisteeksi. (Jos neliöpoikkeamien summa solmun keskiarvosta on nolla, solmua pidetään päätepisteenä, vaikka se ei olisi saavuttanut minimikokoa.)
puun karsiminen
koska puu on kasvatettu Harjoitusjoukosta, täysin kehittynyt puu kärsii tyypillisesti ylisovituksesta (eli se selittää harjoitusjoukon satunnaisia elementtejä, jotka eivät todennäköisesti ole suuremman populaation piirteitä). Tämä ylisovitus johtaa heikkoon suorituskykyyn tosielämän tiedoissa. Sen vuoksi puu on karsittava Validointiryhmän avulla. XLMiner laskee kustannuskompleksikertoimen jokaisessa vaiheessa puun kasvun aikana ja päättää karsitun puun ratkaisusolmujen määrän. Kustannuskompleksikerroin on kertova tekijä, jota sovelletaan puun kokoon (mitattuna päätepisteiden lukumäärällä).
puu karsitaan seuraavien summien minimoimiseksi: 1) validointitietojen lähtömuuttujan varianssi, joka otetaan päätepiste kerrallaan; ja 2) kustannuskompleksikertoimen ja päätepisteiden lukumäärän tulo. Jos kustannuskompleksikerroin on määritelty nollaksi, karsinta on yksinkertaisesti sen puun etsimistä, joka toimii parhaiten validointitiedoissa terminaalisolmujen kokonaisvarianssin osalta. Kustannuskompleksikertoimen suuremmat arvot johtavat pienempiin puihin. Karsinta suoritetaan last-in first-out-periaatteella, eli viimeinen kasvanut solmu on ensimmäinen, joka joutuu eliminoitavaksi.
Ensemble Methods
XLMiner V2015 tarjoaa Regressiopuiden käsittelyyn kolme tehokasta ensemble-menetelmää: pussitus (bootstrap aggregating), boosting ja random trees. Regressiopuualgoritmin avulla voidaan löytää yksi malli, joka tuottaa hyviä ennusteita uudelle datalle. Voimme tarkastella nykyisen ennustajan tilastoja ja sekaannusmatriiseja nähdäksemme, sopiiko mallimme hyvin aineistoon; mutta mistä tiedämme, onko olemassa parempi ennustaja, joka vain odottaa löytymistään? Vastaus on, että emme tiedä, onko parempaa ennustajaa olemassa. Ensemble-menetelmien avulla voidaan kuitenkin yhdistää useita heikkoja regressiopuumalleja, jotka yhdessä muodostettaessa muodostavat uuden, tarkan, vahvan regressiopuumallin. Nämä menetelmät toimivat luomalla useita erilaisia regressiomalleja, ottamalla erilaisia näytteitä alkuperäisestä aineistosta ja yhdistämällä sitten niiden tuotokset. (Tuotoksia voidaan yhdistää useilla tekniikoilla, esimerkiksi luokittelussa enemmistöäänestyksellä ja regressiossa keskiarvolla) tämä mallien yhdistelmä vähentää tehokkaasti strong-mallin varianssia. Xlminerin kolmentyyppiset ensemble-menetelmät (pussitus, tehostus ja satunnaispuut) eroavat toisistaan kolmessa kohdassa: 1) Koulutussarjan valinta kullekin ennustajalle tai heikolle mallille; 2) Miten heikot mallit syntyvät; ja 3) Miten tuotokset yhdistetään. Kaikissa kolmessa menetelmässä jokainen heikko malli koulutetaan koko Koulutussarjaan niin, että se tulee taitavaksi jossain osassa aineistoa.
pussitus (bootstrap aggregating) oli yksi ensimmäisistä ensemble-algoritmeista, joka koskaan kirjoitettiin. Se on yksinkertainen algoritmi, mutta erittäin tehokas. Pussitus luo useita harjoitussarjoja käyttämällä satunnaisotantaa vaihtokurssin avulla (bootstrap-näytteenotto), soveltaa regressiopuun algoritmia kuhunkin datasarjaan ja laskee sitten mallien keskiarvon uusien tietojen ennusteiden laskemiseksi. Pussituksen suurin etu on suhteellinen helppous, että algoritmi voidaan parallelizoida, mikä tekee siitä paremman valinnan hyvin suurille datajoukoille.
Boosting rakentaa vahvan mallin perättäisillä harjoitusmalleilla keskittyäkseen tietueisiin, jotka saivat epätarkkoja ennustettuja arvoja aiemmissa malleissa. Valmistuttuaan kaikki ennustajat yhdistetään painotetulla ääntenenemmistöllä. XLMiner tarjoaa kolme muunnelmaa lisäämällä toteutettuna AdaBoost algoritmi (yksi suosituimmista ensemble algoritmit käytössä tänään): M1 (Freund), M1 (Breiman) ja SAMME (Stagewise Additive Modeling using a Multi-class Exponential).
Adaboost.M1 antaa ensin painon (wb(i)) jokaiselle tietueelle tai havainnolle. Tämä paino on alun perin asetettu 1/n, ja päivitetään jokaisen iteraation algoritmin. Alkuperäinen regressiopuu luodaan tämän ensimmäisen harjoitusjoukon (TB) avulla ja virhe lasketaan seuraavasti:
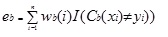
missä funktio I() palauttaa arvon 1 Jos se on totta ja 0 jos ei.
regressiopuun virhe bth-iteraatiossa käytetään vakion laskemiseen ?b. Tätä vakiota käytetään painon päivittämiseen (wb (i). Adabostissa.M1 (Freund), vakio lasketaan seuraavasti:
ab= Ln ((1-eb)/eb)
AdaBoost.M1 (Breiman), vakio lasketaan
ab= 1/2LN ((1-eb)/eb)
SAMMESSA vakio lasketaan
ab= 1/2LN ((1-eb)/eb + Ln (k-1) missä k on luokkien lukumäärä
missä luokkien lukumäärä on yhtä suuri kuin 2, SAMME käyttäytyy samalla tavalla kuin AdaBoost Breiman.
missä tahansa kolmesta toteutuksesta (Freund, Breiman tai SAMME), (B + 1): nnen iteraation Uusi painoarvo on

jälkeenpäin kaikki painot on korjattu summaksi 1. Tämän seurauksena epätarkkoja ennustusarvoja saaneille havainnoille annetut painot kasvavat ja tarkkoja ennustusarvoja saaneille havainnoille annetut painot pienenevät. Tämä säätö pakottaa seuraavan regressiomallin painottamaan enemmän tietueita, joille annettiin epätarkkoja ennusteita. (Tämä ? vakiota käytetään myös loppulaskennassa, jolloin pienimmän virheen omaava regressiomalli saa enemmän vaikutusvaltaa.) Tämä prosessi toistuu, kunnes b = heikkojen oppijoiden määrä. Tämän jälkeen algoritmi laskee kaikkien heikkojen oppijoiden painotetun keskiarvon ja antaa kyseisen arvon tietueelle. Lisäämällä yleensä tuottaa parempia malleja kuin pussitus; kuitenkin, se ei ole haitta, koska se ei ole parallelizable. Jos heikkojen oppijoiden määrä on suuri, tehostaminen ei siis olisi sopivaa.
satunnaispuumenetelmä (satunnaismetsät) on pussituksen muunnelma. Tämä menetelmä toimii kouluttamalla useita heikkoja regressiopuita käyttämällä kiinteää määrää satunnaisesti valittuja ominaisuuksia (sqrt luokittelua varten ja ominaisuuksien lukumäärä/3 ennustamista varten), sitten otetaan heikkojen oppijoiden keskiarvo ja osoitetaan tuo arvo vahvaan ennustajaan. Tyypillisesti heikkojen puiden määrä voi vaihdella useista sadoista useisiin tuhansiin riippuen harjoitussarjan koosta ja vaikeudesta. Satunnaiset puut ovat paralleloituvia, koska ne ovat pussituksen muunnos. Koska tandom-puut kuitenkin valitsevat rajallisen määrän ominaisuuksia jokaiseen iteraatioon, satunnaisten puiden suorituskyky on pussitusta nopeampi.
Regressiopuukokonaisuusmenetelmät ovat hyvin tehokkaita menetelmiä ja johtavat tyypillisesti parempaan suorituskykyyn kuin yksittäinen puu. Tämä ominaisuus lisäksi XLMiner V2015 tarjoaa tarkempia ennustus malleja, ja olisi harkittava yli yhden puun menetelmä.