seaborn.histplot¶
seaborn.histplot(data=None, *, x=None, y=None, hue=None, weights=None, stat= ”count”, bins= ”auto”, binwidth=None, binrange=None, discrete=None, kumulative=False, common_bins=True, common_norm=True, multiple= ”layer”, element= ”bars”, fill=True, Shrink=1, KDE=False, kde_kws=none, line_kws=None, Thrash=0, pthresh=None, Pmax=None, Cbar=false, cbar_ax=None, cbar_kws=None, palette=none, hue_order=none, hue_norm=None, color=None, Log_scale=None, Legend=True, AX=None, **kwargs)¶
piirrä univariate-tai bivariate-histogrammit näyttääksesi jakaumat tietojoukko.
histogrammi on klassinen visualisointityökalu, joka kuvaa yhden tai useamman muuttujan jakautumista laskemalla indiscrete-astioihin putoavien havaintojen määrän.
tämä funktio voi normalisoida kunkin bin sisällä lasketun statistin estimaatiksi, tiheydeksi tai todennäköisyysmassaksi, ja se voi lisätä tasaisen käyrän, joka saadaan käyttämällä ytimen tiheysarviota, joka on samanlainen kuin kdeplot().
lisätietoja on käyttöoppaassa.
Parametriaineistopandas.DataFramenumpy.ndarray, mapping, or sequence
Input data structure. Joko pitkänmuotoinen kokoelma vektoreita, jotka voidaan määrittää nimetyiksi muuttujiksi, tai laajanmuotoinen tietojoukko, joka muotoillaan sisäisesti.
x, yvektorit tai avaimetdata
muuttujat, jotka määrittävät sijainnit x-ja y-akseleilla.
huevektori tai avaindata
semanttinen muuttuja, joka on kartoitettu piirtoelementtien värin määrittämiseksi.
painotsvektori tai avaindata
Jos ilmoitettu, painotetaan vastaavan tietopisteen osuus kunkin lokeron määrästä näillä kertoimilla.
stat{”count”, ”frequency”, ”density”, ”probability”}
Aggregate statistic to computer in each bin.
countosoittaa havaintojen määrän
frequencynäyttää havaintojen määrän jaettuna bin leveydellä
densitynormalisoi luvut siten, että histogrammin pinta-ala on 1
probability normalisoi laskee siten, että viivakorkeuksien summa on 1
binstr, luku,vektori tai tällaisten arvojen pari
yleinen bin-parametri, joka voi olla viitesäännön nimi, astioiden lukumäärä tai astioiden katkokset.Siirretty numpy.histogram_bin_edges().
binwidthnumber tai numeropari
jokaisen bin leveys, ohitetaan bins, mutta voidaan käyttääbinrange.
lukujen binrangepari tai paripari
alin ja korkein arvo bin edgeille; voidaan käyttää eitherwith bins tai binwidth. Oletusarvot datan äärirajoille.
diskreetti
Jos tosi, oletusarvo binwidth=1 ja piirrä tangot niin, että ne sijoittuvat vastaaviin datapisteisiinsä. Näin vältetään” aukkoja”, joita saattaa ilmaantua, kun käytetään diskreettiä (kokonaislukua) dataa.
cumulativebool
Jos se on totta, merkitään kumulatiiviset luvut, kun astiat kasvavat.
common_binsbool
Jos tosi, käytä samoja lokeroita, kun semanttiset muuttujat tuottavat multipleploteja. Jos käytetään viitesääntöä säiliöiden määrittämiseen, se lasketaan koko aineiston kanssa.
common_normbool
Jos tosi ja käyttäen normalisoitua tilastoa, normalisointi pätee koko aineiston yli. Muussa tapauksessa normalisoida kunkin histogrammin itsenäisesti.
multiple{”layer”, ”dodge”, ”stack”, ”fill”}
lähestymistapa useiden elementtien ratkaisemiseen, kun semanttinen kartoitus luo osajoukkoja.Relevantti vain vaihtelevien tietojen kanssa.
Elementti{”bars”, ”step”, ”poly”}
histogrammin statistin visuaalinen esitys.Relevantti vain vaihtelevien tietojen kanssa.
fillbool
Jos tosi, täytä histogrammin alla oleva tila.Relevantti vain vaihtelevien tietojen kanssa.
shrinknumber
skaalaa jokaisen tangon leveys suhteessa binleveyteen tällä kertoimella.Relevantti vain vaihtelevien tietojen kanssa.
kdebool
Jos tosi, lasketaan ytimen tiheysarvio jakauman tasoittamiseksi ja näytetään kuvaajalla (yhdellä tai useammalla) suoralla(s).Relevantti vain vaihtelevien tietojen kanssa.
kde_kwsdict
parametrit, jotka ohjaavat KDE: n laskentaa, kuten kdeplot().
line_kwsdict
parametrit, jotka ohjaavat KDE: n visualisointia, välitetäänmatplotlib.axes.Axes.plot().
puimamäärä tai ei mitään
solut, joiden tilastollinen arvo on pienempi tai yhtä suuri kuin tämä arvo, ovat läpinäkyviä.Koskee vain bivariate-tietoja.
pthreshnumber or None
Like thresh, mutta arvo sellainen, että solut, joiden yhteenlasketut luvut(tai muut tilastot, kun niitä käytetään) ovat tähän osuuteen asti kokonaissummasta, jäävät avoimiksi.
pmaxnumber or None
a value in that set that saturation point for the colormap at a values such that cells is constistute this proposal of the total count (orother statistic, when used).
cbarbool
Jos se on totta, lisää väripalkki merkitäksesi värikartoituksen bivariaattisessa kuvaajassa.Huom: ei tällä hetkellä tue havaintoaloja, joiden hue muuttuva kaivo.
cbar_axmatplotlib.axes.Axes
väripalkin olemassa olevat akselit.
cbar_kwsdict
matplotlib.figure.Figure.colorbar().
palettestring, list, dict taimatplotlib.colors.Colormap
menetelmä hue semanttinen.Merkkijonojen arvot siirretään color_palette(). List tai dict valuesimply category mapping, kun taas colormap-objekti merkitsee numeerista kartoitusta.
hue_ordervector of strings
Määritä käsittely-ja piirtojärjestys kategoriatasoillehue semanttinen.
hue_normtuple tai
matplotlib.colors.Normalize
joko arvopari, joka asettaa normalisointialueen datayksikössä, tai objekti, joka kartoittaa tietoyksiköistä intervalliksi. Usageyksilöi numeerisen kartoituksen.
colormatplotlib color
Single color specification for when hue mapping is not used. Muuten, theplot yrittää kytkeä osaksi matplotlib ominaisuus sykli.
log_scalebool tai number, tai boolien tai lukujen pari
Aseta lokiasteikko data-akselille (tai akseleille, joissa on bivariate data) given-base (oletusarvo 10), ja arvioi KDE lokiavaruudessa.
legendbool
Jos epätosi, estä semanttisten muuttujien legenda.
AXmatplotlib.axes.Axes
havaintoalaa edeltävät akselit. Muussa tapauksessa matplotlib.pyplot.gca()sisäisesti.
kwargs
muut avainsanaväitteet siirtyvät johonkin seuraavista matplotlibfunktioista:
-
matplotlib.axes.Axes.bar()(univariate, element=”bars”) -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
piirtää univariate-tai bivariate-jakaumat ytimen tiheyden estimoinnin avulla.
rugplot
piirtää rastin jokaiseen havaintoarvoon x-ja / tai y-akselin suuntaisesti.
ecdfplot
piirtää empiirisiä kumulatiivisia jakaumafunktioita.
jointplot
piirtää bivariaattikäyrän, jossa on univariaattiset marginaalijakaumat.
toteaa
histogrammin laskemiseen ja piirtämiseen käytettävien lokeroiden valinnalla voi olla merkittävä vaikutus niihin oivalluksiin, joita visualisoinnista voidaan saada. Jos astiat ovat liian suuria, ne voivat poistaa tärkeitä ominaisuuksia.Toisaalta liian pieniä lokeroita voi hallita satunnaismuuttuvuus, joka hämärtää todellisen taustalla olevan jakauman muodon. Thedefault bin koko määritetään käyttämällä vertailusääntöä, joka riippuu otoksen koosta ja varianssista. Tämä toimii hyvin monissa tapauksissa (eli”hyvin käyttäytyviä” tietoja), mutta se epäonnistuu toisissa. On aina hyvä kokeilla eri bin koot olla varma, että et puuttuu jotain tärkeää.Tämän toiminnon avulla voit määrittää säilytysastiat useilla eri tavoilla, kuten asettamalla käytettävien säilytysastioiden kokonaismäärän, jokaisen roskakorin leveyden tai tietyt paikat, joissa säilytysastioiden pitäisi rikkoutua.
Examples
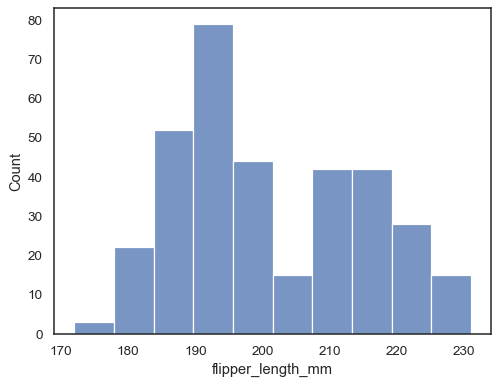
määrittää muuttujan x piirtämään univariaattijakauman X-akselia pitkin:
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
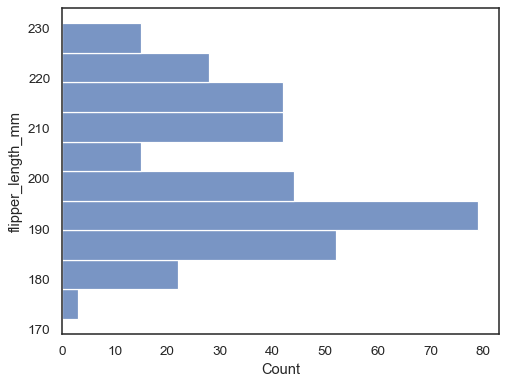
Käännä kuvaaja osoittamalla datamuuttuja y-akselille:
sns.histplot(data=penguins, y="flipper_length_mm")
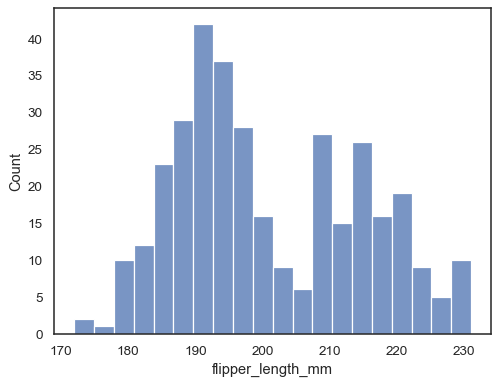
tarkista, kuinka hyvin histogrammi edustaa tietoja määrittämällä vaihteluvälin leveys:
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
voit myös määritellä käytettävän astioiden kokonaismäärän:
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
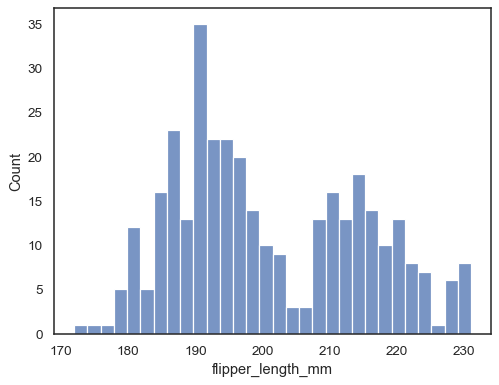
lisätään ytimen tiheysarvio histogrammin tasoittamiseksi, jolloin saadaan täydentävää tietoa jakauman muodosta:
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
Jos x eikä y ei anneta, aineisto käsitellään wide-muodossa ja jokaiselle numeeriselle sarakkeelle piirretään histogrammi:
sns.histplot(data=penguins)
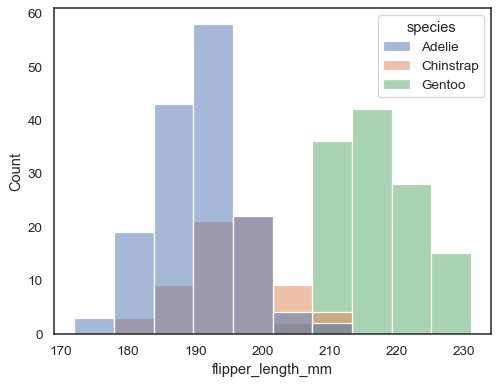
pitkäaikaisesta aineistosta voi muuten piirtää useita histogrammeja Hue-kartoituksella:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
oletusmenetelmä useiden jakaumien piirtämiseen on”kerros” ne, mutta voit myös ”pinota” ne:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
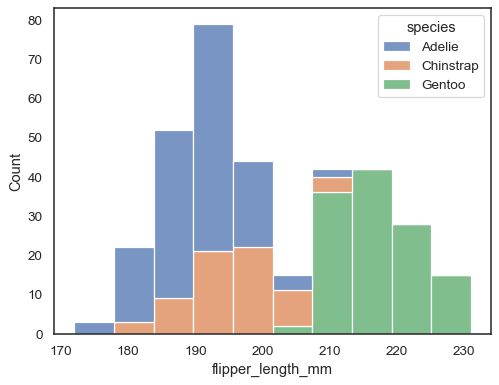
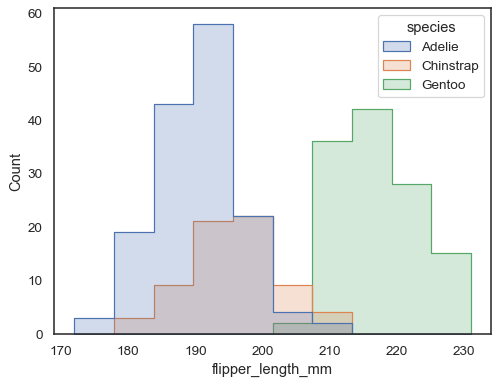
päällekkäisiä palkkeja voi olla vaikea visuaalisesti ratkaista. Toisenlainen lähestymistapa voisi olla porrasfunktion piirtäminen:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
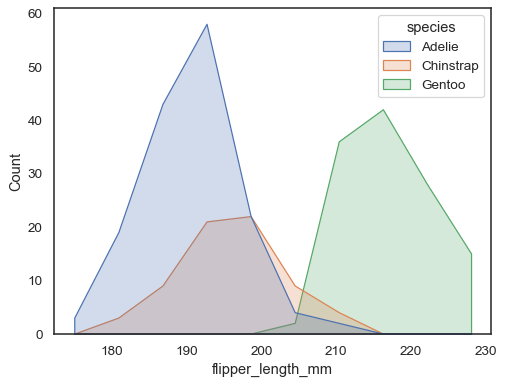
voit siirtyä vielä kauemmas baareista piirtämällä jokaisen lokeron keskelle monikulmion, jossa on kärjet. Tämä voi helpottaa jakelun kuvamaiseman näkemistä, mutta käytä varoen: yleisöllesi on vähemmän itsestään selvää, että he tarkastelevat histogrammia:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
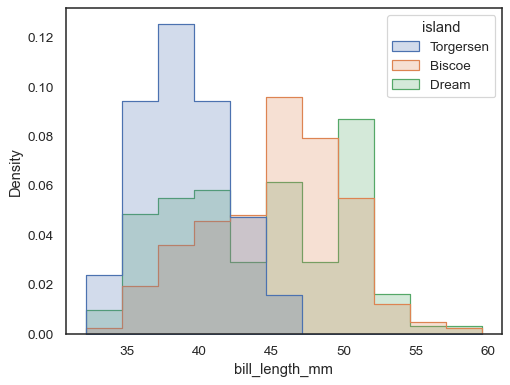
verrataksesi alijoukkojen jakaumaa, jotka eroavat toisistaan huomattavasti insize:
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
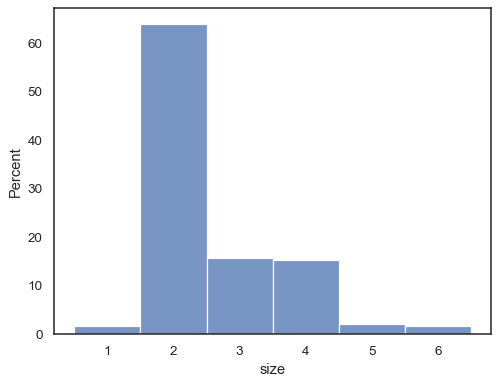
on myös mahdollista normalisoida niin, että jokaisen palkin korkeus osoittaa aprobabiliteetin, mikä on järkevämpää diskreeteille muuttujille:
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
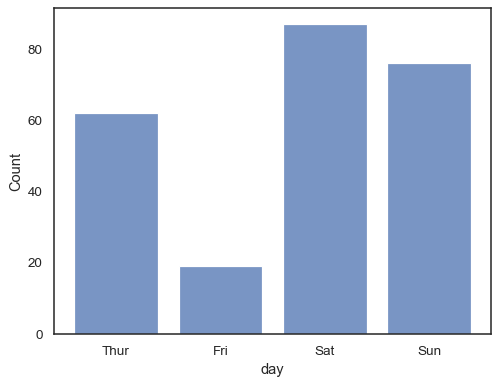
voit jopa piirtää histogrammin kategoristen muuttujien päälle (vaikkakin tämä on kokeellinen ominaisuus):
sns.histplot(data=tips, x="day", shrink=.8)
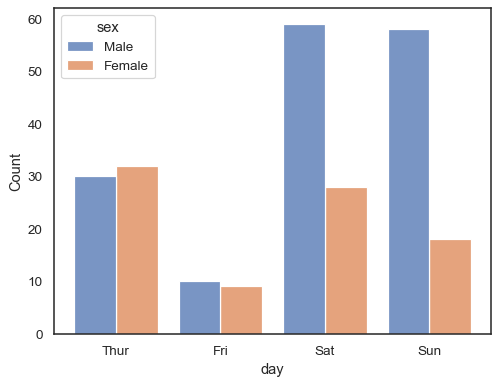
käytettäessä hue semanttinen diskreetin datan kanssa voi olla järkevää” väistää”tasot:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
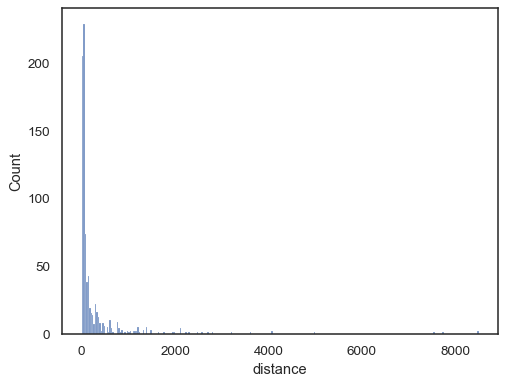
reaalimaailman tiedot ovat usein vinoutuneita. Voimakkaasti vinoutuneiden jakelujen kohdalla on parempi määritellä lokit lokitilassa. Verrata:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
To the log-scale version:
sns.histplot(data=planets, x="distance", log_scale=True)
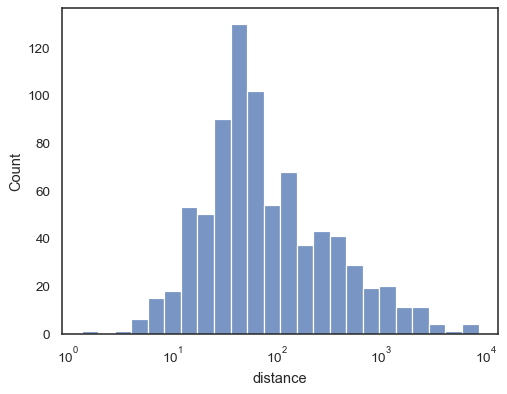
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
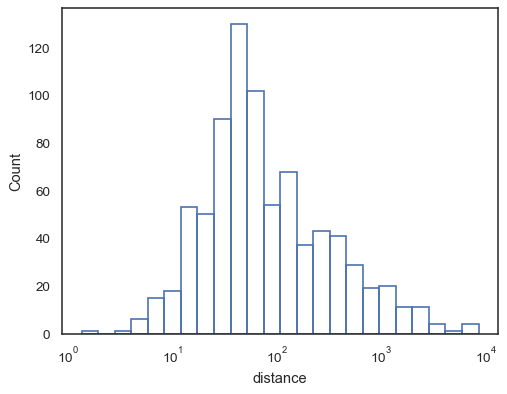
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
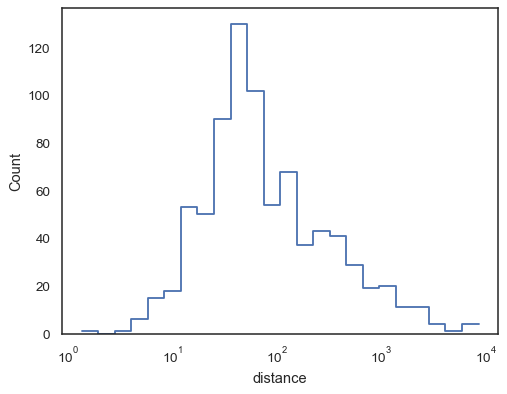
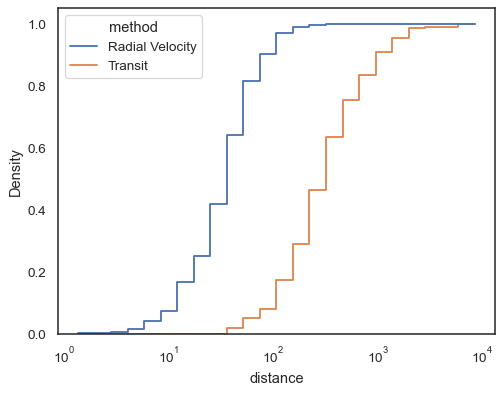
Step-funktioiden, esepciaalisesti täyttämättöminä, avulla on helppo koota histogrammeja:
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
kun sekä x että y annetaan bivariaattihistogrammi ja esitetään heatmap:
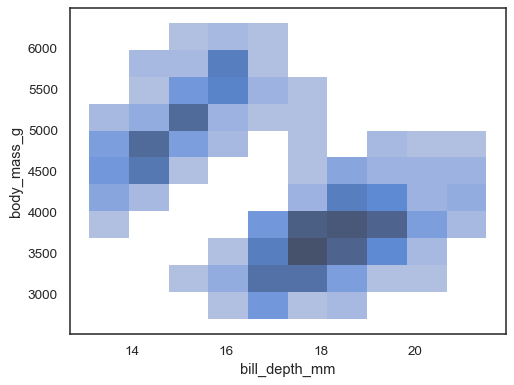
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
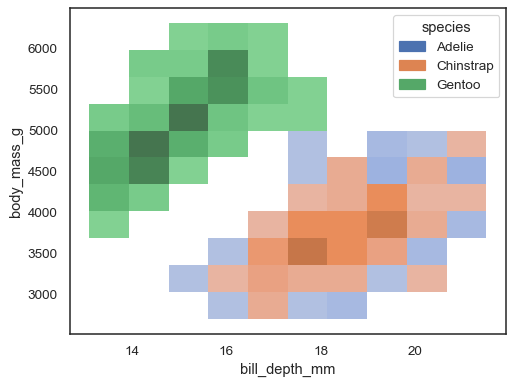
on mahdollista määrittää myös hue muuttuja, joskin tämä ei toimi hyvin, jos eri tasojen tiedot ovat huomattavasti päällekkäisiä:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
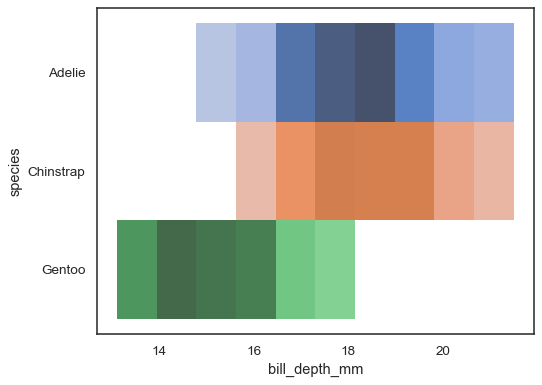
useat värikartat voivat olla järkeviä, kun yksi muuttujista on discrete:
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
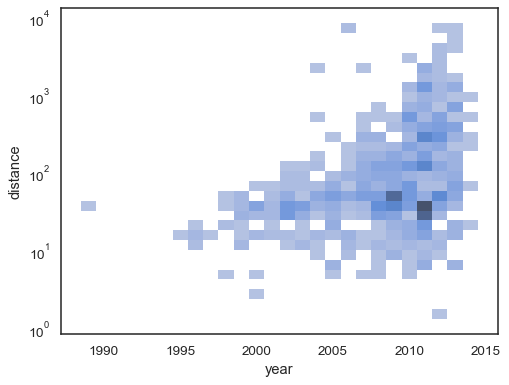
bivariaattihistogrammi hyväksyy kaikki samat laskentavaihtoehdot univariaattisena vastineenaan käyttäen tupleja parametrisointiin x jay itsenäisesti:
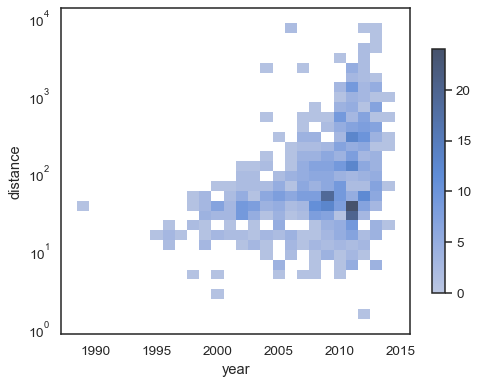
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
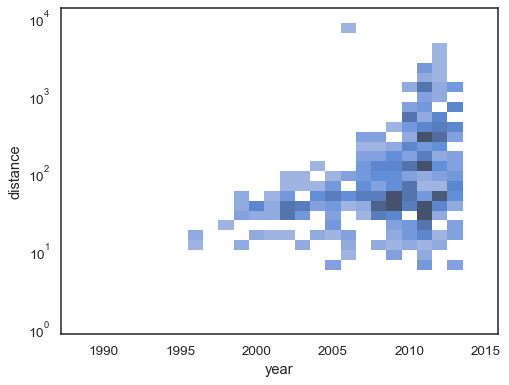
oletuskäyttäytyminen tekee havainnoimattomista soluista läpinäkyviä, joskin tämä voidaan poistaa käytöstä:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
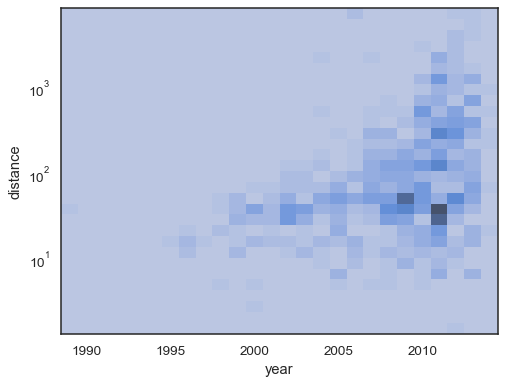
on myös mahdollista asettaa kumulatiivisten lukujen osuuden raja-ja värikylläisyyspiste:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
värikarttaan lisää väripalkki:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)