T-testi
t-testi arvioi, eroavatko kahden ryhmän keskiarvot tilastollisesti toisistaan. Tämä analyysi on sopiva aina, kun haluat verrata keinoja kahden ryhmän, ja erityisen sopiva analyysi posttest-vain kahden ryhmän satunnaistettu kokeellinen suunnittelu.
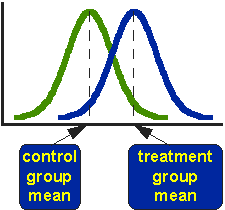
kuva 1. Käsiteltyjen ja vertailuryhmän posttest-arvojen idealisoidut jakaumat.
kuvassa 1 esitetään jakaumat tutkimuksen hoidetuille (sininen) ja kontrolliryhmille (vihreä). Todellisuudessa kuvassa näkyy idealisoitu jakauma-varsinainen jakauma kuvattaisiin yleensä histogrammilla tai pylväsdiagrammilla. Luku kertoo, missä kontrolli-ja hoitoryhmän keinot sijaitsevat. T-testin kysymys on, ovatko keinot tilastollisesti erilaisia.
Mitä tarkoittaa sanoa, että kahden ryhmän keskiarvot ovat tilastollisesti erilaisia? Tarkastellaan kuvassa 2 esitettyjä kolmea tilannetta. Ensimmäinen huomio kolmesta tilanteesta on, että keinojen ero on sama kaikissa kolmessa. Mutta, sinun pitäisi myös huomata, että kolme tilannetta eivät näytä samalta-ne kertovat hyvin erilaisia tarinoita. Huippuesimerkki osoittaa tapauksen, jossa pistemäärät vaihtelevat kohtalaisesti kunkin ryhmän sisällä. Toinen tilanne osoittaa suuren vaihtelevuuden tapauksen. kolmas osoittaa asian pienellä vaihtelevuudella. On selvää, että voimme päätellä, että kaksi ryhmää näyttävät eniten erilaisia tai erillisiä pohjassa tai vähän vaihtelua tapauksessa. Miksi? Koska kahden kellonmuotoisen käyrän välillä on suhteellisen vähän päällekkäisyyttä. Suuren vaihtelevuuden tapauksessa ryhmäero vaikuttaa vähiten huomiota herättävältä, koska kaksi kellonmuotoista jakaumaa limittyvät niin paljon toisiinsa.
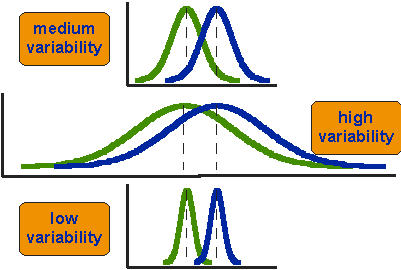
kuva 2. Kolme skenaariota keinojen välisistä eroista.
tästä päästään hyvin tärkeään johtopäätökseen: kun tarkastellaan kahden ryhmän pistemäärien välisiä eroja, on arvioitava niiden keskiarvojen ero suhteessa niiden pistemäärien leviämiseen tai vaihteluun. T-testi tekee juuri näin.
T-testin tilastollinen analyysi
t-testin kaava on suhdeluku. Suhdeluvun ylin osa on vain kahden keskiarvon eli keskiarvon ero. Alaosa mittaa pisteiden vaihtelua tai hajontaa. Tämä kaava on oleellisesti toinen esimerkki signal-to-noise metaforasta tutkimuksessa: ero keinojen välillä on signaali siitä, että tässä tapauksessa ajattelemme ohjelmamme tai käsittelymme tulevan dataan; kaavan alaosa on vaihtelun mitta, joka on lähinnä kohinaa, joka voi vaikeuttaa ryhmäeron näkemistä. Kuvassa 3 esitetään t-testin kaava ja osoittajan ja nimittäjän suhde jakaumiin.
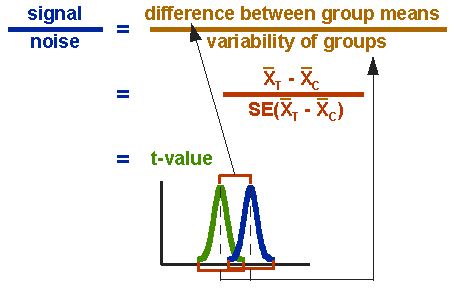
kuva 3. T-testin kaava.
kaavan yläosa on helppo laskea – vain löytää ero keinojen välillä. Alinta osaa kutsutaan erotuksen keskivirheeksi. Sen laskemiseksi otamme kunkin ryhmän varianssin ja jaamme sen ryhmän ihmisten määrällä. Lisäämme nämä kaksi arvoa ja otamme sitten niiden neliöjuuren. Keskiarvojen erotuksen keskivirheen ominaiskaava on:
$$\textrm{SE}(\bar{X}_T-\bar{X}_C) = \sqrt{\frac{\textrm{var}_T}{n_T}+\frac{\textrm{var}_C}{n_c}}$$
muista, että varianssi on yksinkertaisesti keskihajonnan neliö.
t-testin lopullinen kaava on:
$$t = \frac{\bar{X}_T-\bar{X}_C}{\sqrt{\frac{\textrm{var}_T}{n_t}+\frac{\textrm{var}_C}{n_c}}$$
t-arvo on positiivinen, jos ensimmäinen keskiarvo on suurempi kuin toinen ja negatiivinen, jos se on pienempi. Kun lasketaan t-arvo, se pitää etsiä merkittävästä taulukosta testatakseen, onko suhdeluku tarpeeksi suuri, jotta voidaan sanoa, että ryhmien välinen ero ei todennäköisesti ole ollut sattumalöydös. Testata merkitystä, sinun täytyy asettaa riskitaso (kutsutaan alpha taso). Useimmissa yhteiskuntatutkimuksissa ”nyrkkisääntönä”on asettaa alfataso tasolle .05. Tämä tarkoittaa, että viisi kertaa sadasta löytäisi tilastollisesti merkitsevän eron keinojen välillä, vaikka niitä ei olisikaan (eli ”sattumalta”). Sinun täytyy myös määrittää vapausasteet (DF) testiä varten. t-test vapausasteet on molempien ryhmien henkilöiden summa miinus 2. Kun otetaan huomioon alfataso, df ja t-arvo, voidaan katsoa t-arvo ylös vakiotaulukossa, jolla on merkitystä (löytyy lisäyksenä useimpien tilastotekstien takapuolelta), onko t-arvo riittävän suuri ollakseen merkittävä. Jos näin on, voidaan päätellä, että ero näiden kahden ryhmän keinojen välillä on erilainen (jopa vaihtelu huomioon ottaen). Onneksi tilastolliset tietokoneohjelmat rutiininomaisesti tulostavat merkitsevyystestien tulokset ja säästävät vaivan etsiä niitä taulukosta.
t-testi, varianssin yksisuuntainen analyysi (ANOVA) ja eräs regressioanalyysin muoto ovat matemaattisesti ekvivalentteja (KS.tilastollinen analyysi postttest-vain satunnaistetusta kokeellisesta suunnittelusta) ja tuottaisivat identtiset tulokset.