grip krijgen op Reinforcement Learning via Markov Decision Process
Dit artikel werd gepubliceerd als onderdeel van de Data Science Blogathon.
Inleiding
Reinforcement Learning (RL) is een leermethode waarbij de leerling leert zich te gedragen in een interactieve omgeving met behulp van zijn eigen acties en beloningen voor zijn acties. De leerling, vaak agent genoemd, ontdekt welke acties de maximale beloning geven door ze te exploiteren en te verkennen.

een belangrijke vraag is-hoe verschilt RL van leren onder toezicht en zonder toezicht?
het verschil komt in het interactieperspectief. Begeleid leren vertelt de gebruiker/agent direct welke actie hij moet uitvoeren om de beloning te maximaliseren met behulp van een training dataset van gelabelde voorbeelden. Aan de andere kant, RL stelt de agent direct in staat om gebruik te maken van beloningen (positief en negatief) het krijgt om zijn actie te selecteren. Het is dus anders dan unsupervised leren ook omdat unsupervised leren is alles over het vinden van structuur verborgen in collecties van niet-gelabelde gegevens.
Reinforcement Learning Formulation via Markov Decision Process (Mdp)
de basiselementen van een reinforcement learning problem zijn:
- omgeving: de buitenwereld waarmee de agent interageert
- toestand: huidige situatie van de agent
- beloning: numeriek feedbacksignaal uit de omgeving
- beleid: methode om de toestand van de agent aan acties in kaart te brengen. Een beleid wordt gebruikt om een actie te selecteren in een bepaalde toestand
- waarde: toekomstige beloning (vertraagde beloning) die een agent zou ontvangen door een actie te ondernemen in een bepaalde toestand
Markov Decision Process (MDP) is een wiskundig raamwerk om een omgeving in reinforcement learning te beschrijven. De volgende figuur toont agent-omgeving interactie in MDP:
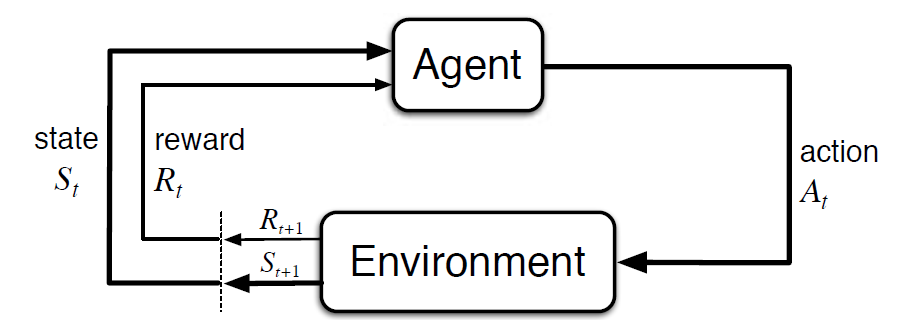
Meer specifiek, de agent en de omgeving te communiceren op elke afzonderlijke stap, t = 0, 1, 2, 3…Bij elke stap, de agent krijgt informatie over de omgeving staat St. Gebaseerd op de milieu staat bij instant t, de agent kiest een actie Op. In het volgende moment ontvangt de agent ook een numeriek beloningssignaal Rt + 1. Dit geeft dus aanleiding tot een reeks als S0, A0, R1, S1, A1, R2…
De willekeurige variabelen Rt en St hebben goed gedefinieerde discrete kansverdelingen. Deze kansverdelingen zijn alleen afhankelijk van de voorgaande toestand en actie op grond van de eigenschap Markov. Laten S, A en R de sets van toestanden, acties en beloningen zijn. De kans dat de waarden van St, Rt en bij het nemen van waarden s’, r en a met vorige toestand s worden gegeven door,
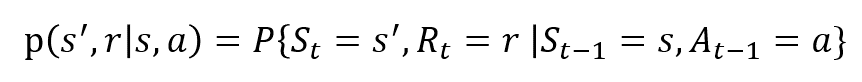
De functie p controleert de dynamiek van het proces.
laten we dit begrijpen met behulp van een voorbeeld
laten we nu een eenvoudig voorbeeld bespreken waar RL kan worden gebruikt om een regelstrategie voor een verwarmingsproces te implementeren.
het idee is om de temperatuur van een ruimte binnen de gespecificeerde temperatuurgrenzen te regelen. De temperatuur in de ruimte wordt beïnvloed door externe factoren zoals buitentemperatuur, de interne warmte gegenereerd, enz.
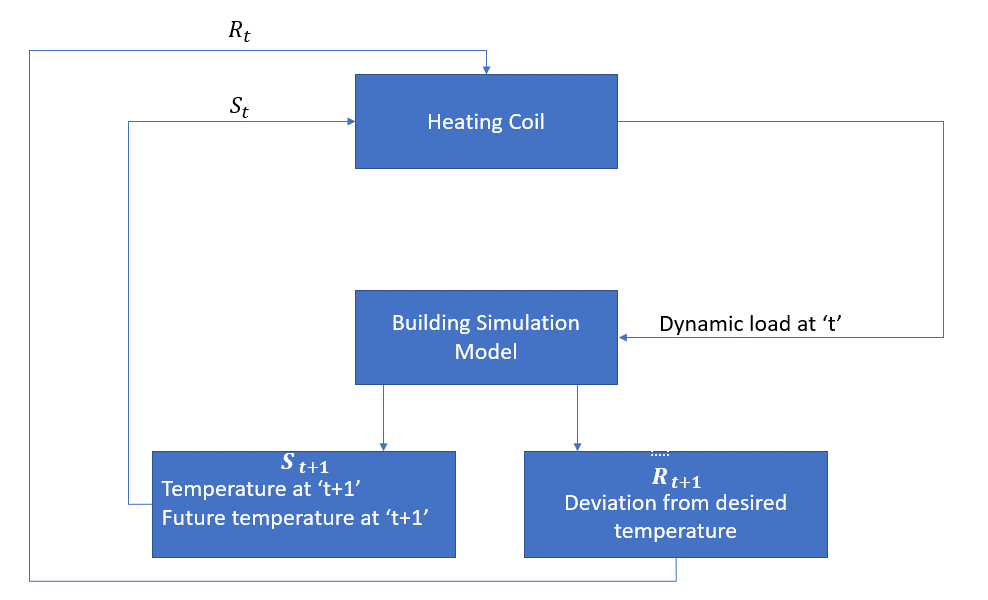
het agens is in dit geval de verwarmingsspoel die de hoeveelheid warmte moet bepalen die nodig is om de temperatuur in de ruimte te regelen door interactie met de omgeving en ervoor te zorgen dat de temperatuur in de ruimte binnen het gespecificeerde bereik ligt. De beloning, in dit geval, is in principe de kosten betaald voor het afwijken van de optimale temperatuurlimieten.
de actie voor de agent is de dynamische belasting. Deze dynamische belasting wordt vervolgens naar de ruimtesimulator gevoerd, een warmteoverdrachtmodel dat de temperatuur berekent op basis van de dynamische belasting. In dit geval is de omgeving het simulatiemodel. De statusvariabele St bevat zowel de huidige als de toekomstige beloningen.
het volgende blokdiagram legt uit hoe MDP kan worden gebruikt voor het regelen van de temperatuur in een ruimte:
beperkingen van deze methode
Versterkingsleer leert van de toestand. De staat is de input voor beleidsvorming. Daarom moeten de staatsinputs correct worden opgegeven. Ook zoals we hebben gezien, zijn er meerdere variabelen en de dimensionaliteit is enorm. Dus het gebruik ervan voor echte fysieke systemen zou moeilijk zijn!
verder lezen
om meer te weten te komen over RL, kunnen de volgende materialen nuttig zijn:
- Reinforcement Learning: An Introduction by Richard.S. Sutton en Andrew.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- Video Lectures by David Silver beschikbaar op YouTube
- https://gym.openai.com/ is een toolkit voor verdere verkenning
u kunt dit artikel ook lezen op onze mobiele APP ![]()
