Hoe semantische segmentatie te doen met behulp van Deep learning
Dit artikel is een uitgebreid overzicht inclusief een stap-voor-stap handleiding om een deep learning image segmentation model te implementeren.
We deelden hier een nieuwe bijgewerkte blog over semantische segmentatie: a 2021 guide to semantische segmentatie
tegenwoordig is semantische segmentatie een van de belangrijkste problemen op het gebied van computervisie. Als je naar het grote geheel kijkt, is semantische segmentatie een van de taken op hoog niveau die de weg effent naar een volledig begrip van de scène. Het belang van scà ne begrijpen als een kern computer visie probleem wordt benadrukt door het feit dat een toenemend aantal toepassingen voeden van het afleiden van kennis uit beelden. Sommige van die toepassingen omvatten zelfrijdende voertuigen, mens-computer interactie, virtuele realiteit enz. Met de populariteit van deep learning in de afgelopen jaren, veel semantische segmentatie problemen worden aangepakt met behulp van diepe architecturen, meestal convolutionele neurale netten, die andere benaderingen overtreffen met een grote marge in termen van nauwkeurigheid en efficiëntie.
- Wat is semantische segmentatie?
- wat zijn de bestaande semantische segmentatie benaderingen?
- 1 — Region-Based Semantic Segmentation
- 2 – volledig Convolutioneel netwerk-gebaseerde semantische segmentatie
- 3-semantische segmentatie onder zwak toezicht
- semantische segmentatie met volledig Convolutioneel netwerk
- Stap 1
- Stap 2
- Stap 3
- Stap 4
- Stap 5
- u bent misschien geïnteresseerd in onze laatste berichten op:
Wat is semantische segmentatie?
semantische segmentatie is een natuurlijke stap in de progressie van Grove naar fijne gevolgtrekking:de oorsprong kan worden gevonden bij classificatie, die bestaat uit het maken van een voorspelling voor een hele input.De volgende stap is lokalisatie / detectie, die niet alleen de klassen, maar ook aanvullende informatie met betrekking tot de ruimtelijke locatie van die klassen.Tot slot bereikt semantische segmentatie fijnkorrelige gevolgtrekking door dichte voorspellingen te maken die labels voor elke pixel afleiden, zodat elke pixel wordt gelabeld met de klasse van het omsluitende object ertsgebied.
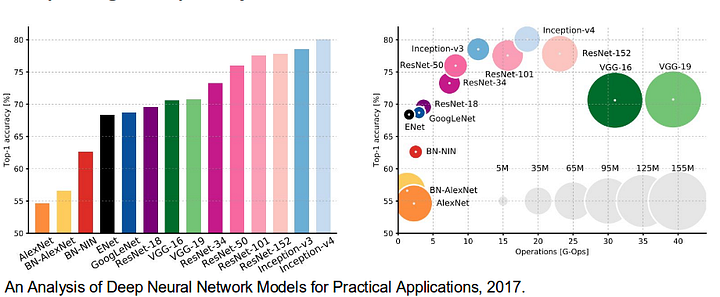
Het is ook waard om enkele standaard diepe netwerken die aanzienlijke bijdragen op het gebied van computer vision, als ze worden vaak gebruikt als de basis van semantische segmentatie systemen:
- AlexNet: Toronto ‘ s baanbrekende diep CNN dat won de 2012 ImageNet competitie met een test juistheid van 84.6%. Het bestaat uit 5 convolutionele lagen, max-pooling degenen, ReLUs als niet-lineariteiten, 3 volledig-convolutionele lagen, en dropout.
- VGG-16: Dit Oxford ‘ s model won de 2013 ImageNet competitie met 92,7% nauwkeurigheid. Het gebruikt een stapel van convolutielagen met kleine ontvankelijke velden in de eerste lagen in plaats van enkele lagen met grote ontvankelijke velden.
- GoogLeNet: dit Google-Netwerk won de 2014 ImageNet competitie met een nauwkeurigheid van 93,3%. Het is samengesteld uit 22 lagen en een nieuw geïntroduceerde bouwsteen genaamd inception module. De module bestaat uit een netwerk-in-netwerklaag, een pooling-operatie, een grote convolutielaag en een kleine convolutielaag.
- ResNet: dit Microsoft-model won de 2016 ImageNet competitie met 96,4% nauwkeurigheid. Het is bekend vanwege de diepte (152 lagen) en de introductie van restblokken. De resterende blokken pakken het probleem van het trainen van een echt diepe architectuur aan door identity skip verbindingen te introduceren, zodat lagen hun ingangen naar de volgende laag kunnen kopiëren.
wat zijn de bestaande semantische segmentatie benaderingen?
een algemene semantische segmentatiearchitectuur kan in grote lijnen worden gezien als een encodernetwerk gevolgd door een decodernetwerk:
- de encoder is meestal een voorgetraind classificatienetwerk zoals VGG/ResNet gevolgd door een decodernetwerk.
- de taak van de decoder is om de discriminatieve eigenschappen (lagere resolutie) die de encoder leert semantisch te projecteren op de pixelruimte (hogere resolutie) om een dichte classificatie te krijgen.
In tegenstelling tot classificatie waarbij het eindresultaat van het zeer diepe netwerk het enige belangrijke ding is, vereist semantische segmentatie niet alleen discriminatie op pixelniveau, maar ook een mechanisme om de discriminerende eigenschappen die in verschillende stadia van de encoder op de pixelruimte worden geleerd, te projecteren. Verschillende benaderingen maken gebruik van verschillende mechanismen als onderdeel van het decoderingsmechanisme. Laten we de drie belangrijkste benaderingen verkennen:
1 — Region-Based Semantic Segmentation
De region-based methoden volgen over het algemeen de “segmentation using recognition” pijplijn, die eerst vrije-vorm regio ‘ s uit een afbeelding haalt en ze beschrijft, gevolgd door region-based classification. In testtijd worden de regio-gebaseerde voorspellingen omgezet in pixelvoorspellingen, meestal door een pixel te etiketteren volgens het hoogste scorende gebied dat het bevat.
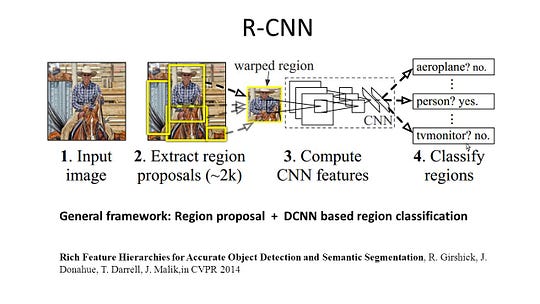
R-CNN (Regions with CNN feature) is een representatief werk voor de regio-gebaseerde methoden. Het voert de semantische segmentatie uit op basis van de resultaten van de objectdetectie. Om specifiek te zijn, R-CNN gebruikt eerst selectief Zoeken om een grote hoeveelheid object voorstellen te extraheren en berekent vervolgens CNN-functies voor elk van hen. Tot slot, het classificeert elke regio met behulp van de klasse-specifieke lineaire SVM ‘ s. Vergeleken met traditionele CNN-structuren die voornamelijk bedoeld zijn voor beeldclassificatie, kan R-CNN meer gecompliceerde taken aanpakken, zoals objectdetectie en beeldsegmentatie, en wordt het zelfs een belangrijke basis voor beide velden. Bovendien, R-CNN kan worden gebouwd op de top van alle CNN benchmark structuren, zoals AlexNet, VGG, GoogLeNet, en ResNet.
voor de image segmentation task, R-CNN geëxtraheerd 2 soorten functies voor elke regio: volledige Regio functie en voorgrond functie, en vond dat het kon leiden tot betere prestaties bij het samenvoegen van hen samen als de regio functie. R-CNN bereikte aanzienlijke prestatieverbeteringen door het gebruik van de zeer discriminerende CNN-functies. Het heeft echter ook een aantal nadelen voor de segmentatietaak:
- De functie is niet compatibel met de segmentatietaak.
- de functie bevat niet genoeg ruimtelijke informatie voor het nauwkeurig genereren van grenzen.
- het genereren van voorstellen op basis van segmenten kost tijd en zou de uiteindelijke prestaties sterk beïnvloeden.
vanwege deze knelpunten is recent onderzoek voorgesteld om de problemen aan te pakken, waaronder SDS, Hypercolumns, Mask R-CNN.
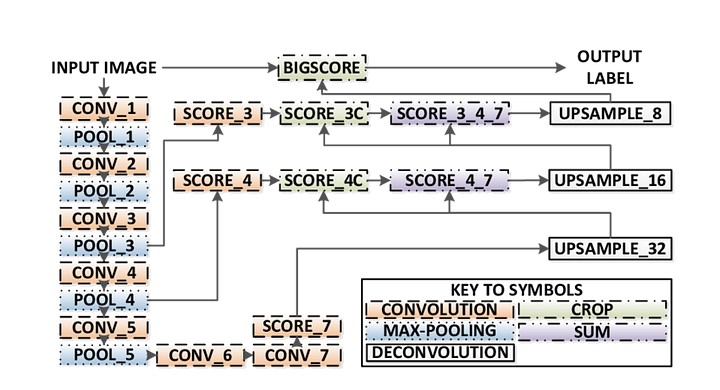
2 – volledig Convolutioneel netwerk-gebaseerde semantische segmentatie
het originele volledig Convolutioneel netwerk (fCN) leert een afbeelding van pixels naar pixels, zonder de regiovoorstellen uit te pakken. De fCN-netwerkpijplijn is een uitbreiding van de klassieke CNN. Het belangrijkste idee is om de klassieke CNN nemen als invoer willekeurig formaat beelden. De beperking van CNNs om alleen labels te accepteren en te produceren voor inputs van specifieke grootte komt van de volledig verbonden lagen die vast zijn. In tegenstelling tot hen hebben fCN ‘ s alleen convolutionele en poolende lagen die hen de mogelijkheid geven om voorspellingen te doen over willekeurige inputs.
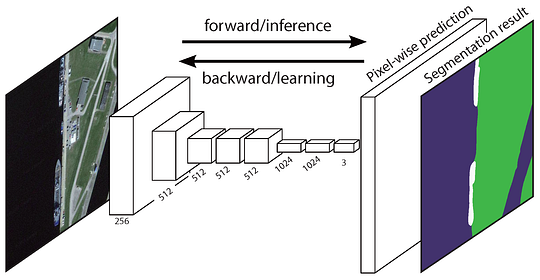
een probleem in deze specifieke FCN is dat door het verspreiden via verschillende afwisselende convolutionele en pooling lagen, de resolutie van de uitvoerkenmerk maps down sampleed wordt. Daarom zijn de directe voorspellingen van FCN typisch in lage resolutie, resulterend in vrij vage objectgrenzen. Een verscheidenheid van meer geavanceerde op FCN-gebaseerde benaderingen is voorgesteld om dit probleem aan te pakken, met inbegrip van SegNet, DeepLab-CRF, en verwijde convoluties.
3-semantische segmentatie onder zwak toezicht
De meeste relevante methoden in semantische segmentatie berusten op een groot aantal afbeeldingen met pixelgebaseerde segmentatiemaskers. Echter, handmatig annoteren van deze maskers is vrij tijdrovend, frustrerend en commercieel duur. Daarom zijn onlangs enkele zwak gecontroleerde methoden voorgesteld, die gewijd zijn aan het vervullen van de semantische segmentatie door gebruik te maken van geannoteerde bounding boxes.

bijvoorbeeld, Boxsup gebruikte de bounding box Annotaties als toezicht om het netwerk te trainen en iteratief de geschatte maskers voor semantische segmentatie te verbeteren. Simple Does het behandelde de zwakke toezicht beperking als een kwestie van input label ruis en onderzocht recursieve training als een de-noising strategie. Labeling op pixelniveau interpreteerde de segmentatietaak binnen het leerkader met meerdere instanties en voegde een extra laag toe om het model te beperken om meer gewicht toe te kennen aan belangrijke pixels voor classificatie op afbeeldingsniveau.
semantische segmentatie met volledig Convolutioneel netwerk
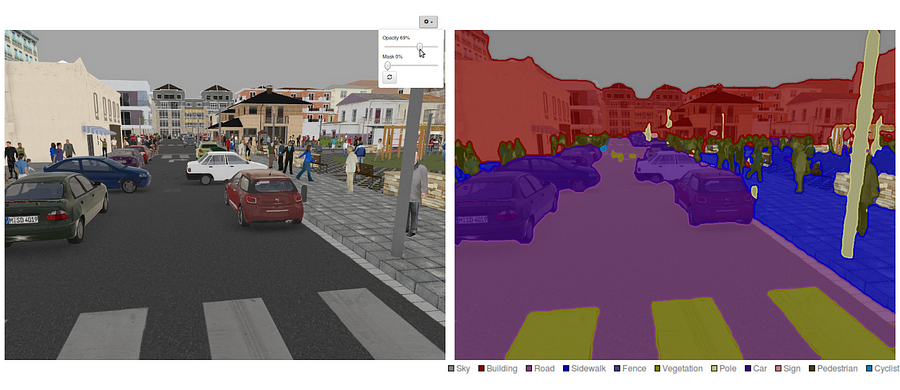
in deze sectie, laten we een stap-voor-stap implementatie doorlopen van de meest populaire architectuur voor semantische segmentatie — het volledig Convolutioneel Net (FCN). We zullen het implementeren met behulp van de TensorFlow bibliotheek in Python 3, samen met andere afhankelijkheden zoals Numpy en Scipy.In deze oefening zullen we de pixels van een weg labelen in afbeeldingen met behulp van FCN. We zullen werken met de Kitti Road dataset voor weg/rijstrookdetectie. Dit is een eenvoudige oefening uit de Udacity ‘ s Self-Driving Car Nano-degree programma, die u meer over de setup in deze GitHub repo leren kunt.

Hier zijn de belangrijkste kenmerken van de FCN architectuur:
- FCN kennis overdraagt van VGG16 uit te voeren semantische segmentatie.
- de volledig verbonden lagen van VGG16 worden geconverteerd naar volledig convolutionele lagen, met behulp van 1×1 convolutie. Dit proces produceert een klasse presence heat map in lage resolutie.
- de upsampling van deze semantische eigenschappen met lage resolutie wordt gedaan met behulp van getransponeerde convoluties (geïnitialiseerd met bilineaire interpolatiefilters).
- in elke fase wordt het upsampling – proces verder verfijnd door functies toe te voegen van grovere maar hogere resolutie-functies van lagere lagen in VGG16.
- Skip-verbinding wordt geà ntroduceerd na elk convolutieblok om het volgende blok in staat te stellen meer abstracte, klasse-saillante functies te extraheren uit de eerder gepoolde functies.
Er zijn 3 versies van FCN (FCN-32, FCN-16, FCN-8). We zullen FCN-8 implementeren, zoals hieronder in detail beschreven:
- Encoder: een voorgetrainde VGG16 wordt gebruikt als encoder. De decoder start vanaf laag 7 van VGG16.
- fCN Layer-8: de laatste volledig verbonden laag van VGG16 wordt vervangen door een 1×1 convolutie.
- FCN-laag-9: FCN Layer-8 wordt 2 keer upsampled om afmetingen te matchen met laag 4 van VGG 16, met behulp van getransponeerde convolutie met parameters: (kernel=(4,4), stride=(2,2), paddding=’same’). Daarna werd een skip verbinding toegevoegd tussen laag 4 van VGG16 en FCN Layer-9.
- FCN Layer-10: FCN Layer-9 wordt 2 keer geupsampled om afmetingen te matchen met laag 3 van VGG16, met behulp van getransponeerde convolutie met parameters: (kernel=(4,4), stride=(2,2), paddding=’same’). Daarna werd een skip verbinding toegevoegd tussen laag 3 van VGG 16 en FCN Layer-10.
- FCN-laag-11: FCN Layer-10 is 4 keer upsampled om afmetingen te matchen met de grootte van de invoerafbeelding, dus we krijgen de werkelijke afbeelding terug en de diepte is gelijk aan het aantal klassen, met behulp van getransponeerde convolutie met parameters:(kernel=(16,16), stride=(8,8), paddding=’same’).
Stap 1
we laden eerst het voorgetrainde VGG-16 model in TensorFlow. Rekening houdend met de TensorFlow sessie en het pad naar de VGG map (die hier gedownload kan worden), retourneren we de tupel van tensors uit het VGG model, inclusief de image input, keep_prob (om de uitvalsnelheid te controleren), layer 3, layer 4 en layer 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7vgg16 functie
Stap 2
nu richten we ons op het maken van de lagen voor een FCN, met behulp van de tensors uit het VGG model. Gegeven de tensors voor VGG layer output en het aantal klassen om te classificeren, retourneren we de tensor voor de laatste laag van die output. In het bijzonder passen we een 1×1 convolution toe op de encoder lagen, en voegen dan decoder lagen toe aan het netwerk met skip verbindingen en upsampling.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11Layers function
Stap 3
de volgende stap is het optimaliseren van ons neurale netwerk, ook bekend als het bouwen van TensorFlow verlies functies en optimizer operaties. Hier gebruiken we cross entropy als onze verliesfunctie en Adam als ons optimalisatiealgoritme.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opoptimaliseer functie
Stap 4
hier definiëren we de train_nn-functie, die belangrijke parameters bevat, waaronder het aantal tijdperken, batchgrootte, verliesfunctie, optimizer-bediening, en placeholders voor invoerafbeeldingen, labelafbeeldingen, Leersnelheid. Voor het trainingsproces stellen we keep_probability ook in op 0.5 en learning_rate op 0.001. Om de voortgang bij te houden, printen we ook het verlies tijdens de training.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Stap 5
eindelijk is het tijd om ons net te trainen! In deze run functie, bouwen we eerst ons net met behulp van de load_vgg, layers, en optimaliseren functie. Dan trainen we het net met behulp van de train_nn functie en slaan de gevolggegevens op voor records.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)Run function
over onze parameters kiezen we epochs = 40, batch_size = 16, num_classes = 2, en image_shape = (160, 576). Na het doen van 2 trial passes met dropout = 0.5 en dropout = 0.75, vonden we dat de 2e trial betere resultaten oplevert met betere gemiddelde verliezen.

om de volledige code te zien, kijk op deze link:https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
Als u genoten van dit stuk, Ik zou het graag delen 👏 en verspreiden van de kennis.
u bent misschien geïnteresseerd in onze laatste berichten op:
- AWS Textract
- Data extractie
start met behulp van Nanonets voor automatisering
probeer het model uit of Vraag vandaag nog een demo aan!
Probeer nu
