Ismerkedés a megerősítési tanulással Markov döntési folyamaton keresztül
Ez a cikk a Data Science Blogathon részeként jelent meg.
Bevezetés
a megerősítő tanulás (RL) egy olyan tanulási módszertan, amellyel a tanuló megtanulja, hogy interaktív környezetben viselkedjen saját cselekedeteivel és cselekedeteiért járó jutalmakkal. A tanuló, akit gyakran ügynöknek hívnak, felfedezi, hogy mely cselekedetek adják a maximális jutalmat, kihasználva és feltárva őket.

kulcskérdés – miben különbözik az RL a felügyelt és a felügyelet nélküli tanulástól?
a különbség az interakció szempontjából jön létre. A felügyelt tanulás közvetlenül megmondja a felhasználónak/ügynöknek, hogy milyen műveletet kell végrehajtania a jutalom maximalizálása érdekében a címkézett példák képzési adatkészletének felhasználásával. Másrészt az RL közvetlenül lehetővé teszi az ügynök számára, hogy kihasználja a jutalmakat (pozitív és negatív), hogy kiválassza a műveletét. Így különbözik a felügyelet nélküli tanulástól is, mert a felügyelet nélküli tanulás a címkézetlen adatok gyűjteményében rejtett struktúra megtalálásáról szól.
megerősítés tanulási megfogalmazás Markov döntési folyamaton (MDP) keresztül
a megerősítési tanulási probléma alapvető elemei a következők:
- környezet: a külvilág, amellyel az ügynök kölcsönhatásba lép
- állapot: az ügynök jelenlegi helyzete
- jutalom: numerikus visszacsatolási jel a környezetből
- politika: módszer az ügynök állapotának cselekvésekhez való leképezésére. A házirend egy adott állapotú művelet kiválasztására szolgál
- érték: jövőbeli jutalom (késleltetett jutalom), amelyet egy ügynök egy adott állapotú művelet végrehajtásával kapna
Markov döntési folyamat (MDP) egy matematikai keretrendszer a megerősítő tanulás környezetének leírására. Az alábbi ábra az ügynök-környezet kölcsönhatást mutatja az MDP-ben:
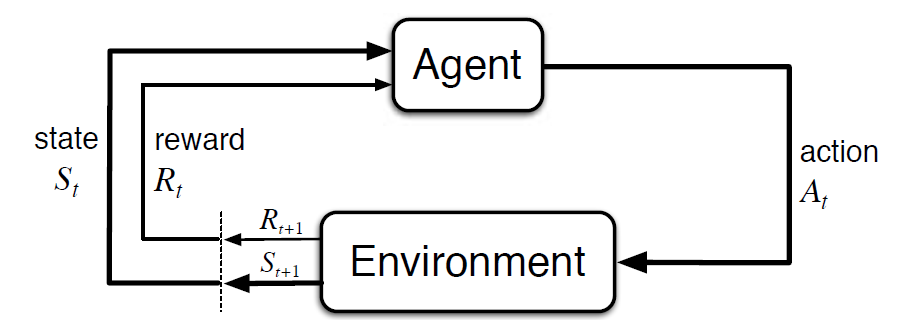
pontosabban, az Ágens és a környezet kölcsönhatásba lép minden egyes különálló időpontban, t = 0, 1, 2, 3…At minden alkalommal lépés, az ügynök információt kap a környezeti állapotról St. A környezeti állapot alapján t pillanatban, az ügynök egy műveletet választ a. A következő pillanatban az ügynök numerikus jutalomjelet is kap Rt + 1. Ez tehát olyan szekvenciát eredményez, mint az S0, A0, R1, S1, A1, R2…
Az Rt és St véletlen változók jól definiált diszkrét valószínűségi eloszlásokkal rendelkeznek. Ezek a valószínűségi eloszlások csak az előző állapottól és a Markov-tulajdonságon alapuló cselekvéstől függenek. Legyen S, A és R az állapotok, cselekedetek és jutalmak halmaza. Ezután a valószínűsége, hogy az értékek St, Rt és a figyelembe értékek S’, r és a korábbi állapot s adja meg,
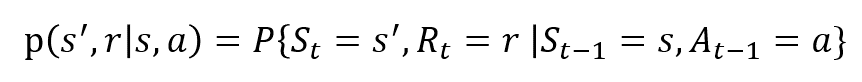
a függvény p szabályozza a dinamika a folyamat.
értsük meg ezt egy példa segítségével
most beszéljünk meg egy egyszerű példát, ahol az RL felhasználható egy fűtési folyamat vezérlési stratégiájának végrehajtására.
az ötlet egy szoba hőmérsékletének szabályozása a megadott hőmérsékleti határokon belül. A helyiség hőmérsékletét olyan külső tényezők befolyásolják, mint a külső hőmérséklet, a keletkező belső hő stb.
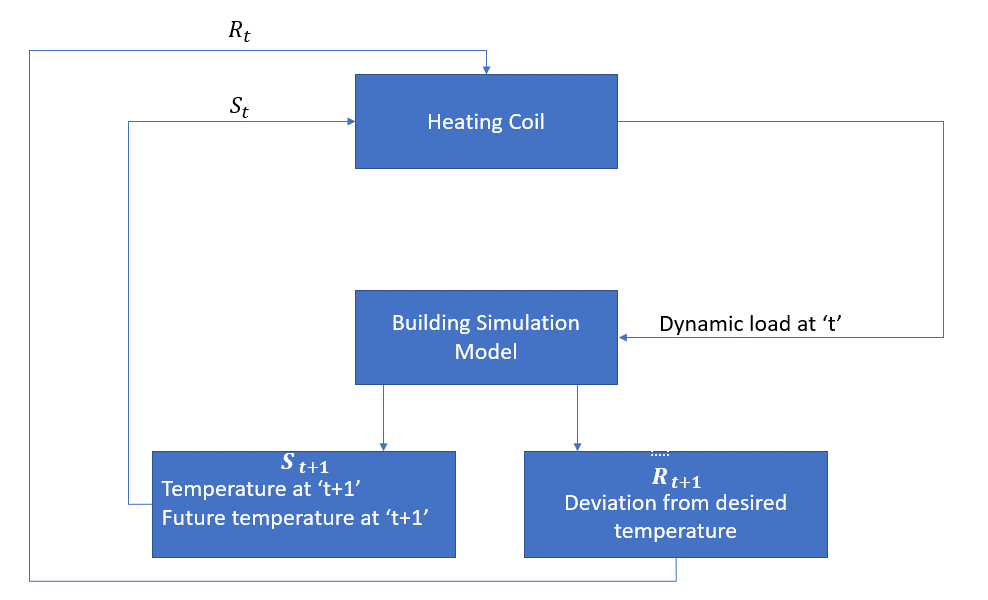
az ágens ebben az esetben a fűtőtekercs, amelynek el kell döntenie a helyiség belső hőmérsékletének szabályozásához szükséges hőmennyiséget a környezettel való kölcsönhatás révén, és biztosítania kell, hogy a helyiség belső hőmérséklete a megadott tartományon belül legyen. A jutalom ebben az esetben alapvetően az optimális hőmérsékleti határértékektől való eltérésért fizetett költség.
az ügynök művelete a dinamikus terhelés. Ezt a dinamikus terhelést ezután betáplálják a helyiségszimulátorba, amely alapvetően egy hőátadási modell, amely kiszámítja a hőmérsékletet a dinamikus terhelés alapján. Tehát ebben az esetben a környezet a szimulációs modell. Az állami változó St tartalmazza a jelen, valamint a jövőbeli jutalmak.
a következő blokkdiagram elmagyarázza, hogyan használható az MDP a helyiség belső hőmérsékletének szabályozására:
A módszer korlátai
megerősítési tanulás tanul az államtól. Az állam a politika kialakításának bemenete. Ezért az állami bemeneteket helyesen kell megadni. Ahogy láttuk, több változó is létezik, és a dimenzió hatalmas. Tehát nehéz lenne valódi fizikai rendszerekhez használni!
további olvasmányok
Ha többet szeretne tudni az RL-ről, a következő anyagok hasznosak lehetnek:
- megerősítő tanulás: Richard bevezetése.S. Sutton és Andrew.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- Videó előadások David Silver elérhető a YouTube-on
- https://gym.openai.com/ egy eszközkészlet a további feltáráshoz
ezt a cikket a mobilalkalmazásunkon is elolvashatja ![]()
