Alberi di regressione
Tutte le tecniche di regressione contengono una singola variabile di output (risposta) e una o più variabili di input (predittore). La variabile di uscita è numerica. La metodologia di costruzione dell’albero di regressione generale consente alle variabili di input di essere una miscela di variabili continue e categoriali. Un albero di decisione viene generato quando ogni nodo di decisione nell’albero contiene un test sul valore di una variabile di input. I nodi terminali dell’albero contengono i valori delle variabili di output previsti.
Un albero di regressione può essere considerato come una variante degli alberi decisionali, progettati per approssimare le funzioni a valore reale, invece di essere utilizzati per i metodi di classificazione.
Metodologia
Un albero di regressione viene costruito attraverso un processo noto come partizionamento ricorsivo binario, che è un processo iterativo che divide i dati in partizioni o rami e quindi continua a dividere ogni partizione in gruppi più piccoli mentre il metodo si sposta su ogni ramo.
Inizialmente, tutti i record nel set di addestramento (record pre-classificati che vengono utilizzati per determinare la struttura dell’albero) sono raggruppati nella stessa partizione. L’algoritmo inizia quindi l’allocazione dei dati nelle prime due partizioni o rami, utilizzando ogni possibile divisione binaria su ogni campo. L’algoritmo seleziona la divisione che minimizza la somma delle deviazioni al quadrato dalla media nelle due partizioni separate. Questa regola di suddivisione viene quindi applicata a ciascuno dei nuovi rami. Questo processo continua fino a quando ogni nodo raggiunge una dimensione minima specificata dall’utente e diventa un nodo terminale. (Se la somma delle deviazioni al quadrato dalla media in un nodo è zero, allora quel nodo è considerato un nodo terminale anche se non ha raggiunto la dimensione minima.)
Potare l’albero
Poiché l’albero è cresciuto dal set di allenamento, un albero completamente sviluppato soffre in genere di sovra-adattamento (cioè, sta spiegando elementi casuali del set di allenamento che non sono suscettibili di essere caratteristiche della popolazione più grande). Questo over-montaggio si traduce in scarse prestazioni sui dati di vita reale. Pertanto, l’albero deve essere potato utilizzando il set di convalida. XLMiner calcola il fattore di complessità dei costi ad ogni passo durante la crescita dell’albero e decide il numero di nodi decisionali nell’albero potato. Il fattore di complessità dei costi è il fattore moltiplicativo applicato alla dimensione dell’albero (misurata dal numero di nodi terminali).
L’albero viene potato per ridurre al minimo la somma di: 1) la varianza variabile di output nei dati di convalida, presa un nodo terminale alla volta; e 2) il prodotto del fattore di complessità dei costi e il numero di nodi terminali. Se il fattore di complessità del costo è specificato come zero, la potatura è semplicemente trovare l’albero che si comporta meglio sui dati di convalida in termini di varianza totale del nodo terminale. Valori maggiori del fattore di complessità dei costi si traducono in alberi più piccoli. La potatura viene eseguita su base last-in first-out, il che significa che l’ultimo nodo cresciuto è il primo ad essere soggetto all’eliminazione.
Metodi Ensemble
XLMiner V2015 offre tre potenti metodi ensemble da utilizzare con alberi di regressione: insaccamento (bootstrap aggregating), potenziamento e alberi casuali. L’algoritmo ad albero di regressione può essere utilizzato per trovare un modello che si traduce in buone previsioni per i nuovi dati. Possiamo visualizzare le statistiche e le matrici di confusione del predittore corrente per vedere se il nostro modello è adatto ai dati; ma come potremmo sapere se c’è un predittore migliore che aspetta solo di essere trovato? La risposta è che non sappiamo se esiste un predittore migliore. Tuttavia, i metodi di ensemble ci permettono di combinare più modelli di albero di regressione debole, che se presi insieme formano un nuovo, accurato, forte modello di albero di regressione. Questi metodi funzionano creando più modelli di regressione diversi, prelevando diversi campioni del set di dati originale e quindi combinando i loro output. (I risultati possono essere combinati con diverse tecniche, ad esempio, il voto a maggioranza per la classificazione e la media per la regressione) Questa combinazione di modelli riduce efficacemente la varianza nel modello forte. I tre tipi di metodi di ensemble offerti in XLMiner (insaccamento, potenziamento e alberi casuali) differiscono su tre elementi: 1) la selezione del set di allenamento per ciascun predittore o modello debole; 2) come vengono generati i modelli deboli; e 3) come le uscite sono combinate. In tutti e tre i metodi, ogni modello debole viene addestrato sull’intero set di allenamento per diventare esperto in una parte del set di dati.
Il bagging (bootstrap aggregating) è stato uno dei primi algoritmi di ensemble mai scritti. Si tratta di un algoritmo semplice, ma molto efficace. L’insacco genera diversi set di allenamento utilizzando il campionamento casuale con sostituzione( bootstrap sampling), applica l’algoritmo dell’albero di regressione a ciascun set di dati, quindi prende la media tra i modelli per calcolare le previsioni per i nuovi dati. Il più grande vantaggio dell’insacco è la relativa facilità con cui l’algoritmo può essere parallelizzato, il che lo rende una selezione migliore per set di dati molto grandi.
Boosting costruisce un modello forte addestrando successivamente i modelli a concentrarsi sui record che ricevono valori predetti imprecisi nei modelli precedenti. Una volta completato, tutti i predittori sono combinati da un voto a maggioranza ponderata. XLMiner offre tre varianti di boosting implementate dall’algoritmo AdaBoost (uno degli algoritmi di ensemble più popolari in uso oggi): M1 (Freund), M1 (Breiman), e SAMME (Stagewise Additive Modeling using a Multi-class Exponential).
Adaboost.M1 assegna innanzitutto un peso (wb (i)) a ciascun record o osservazione. Questo peso è originariamente impostato su 1 / n e verrà aggiornato su ogni iterazione dell’algoritmo. Un albero di regressione originale viene creato utilizzando questo primo set di allenamento (Tb) e un errore viene calcolato come
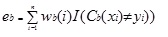
dove, la funzione I () restituisce 1 se vero e 0 se non.
L’errore dell’albero di regressione nell’iterazione bth viene utilizzato per calcolare la costante ?b. Questa costante viene utilizzata per aggiornare il peso (wb (i). Ad AdaBoost.M1 (Freund), la costante viene calcolata come
ab= ln((1-eb)/eb)
In AdaBoost.M1 (Breiman), la costante è calcolato come
ab= 1/2ln((1-eb)/eb)
In SAMME, la costante è calcolato come
ab= 1/2ln((1-eb)/eb + ln(k-1), dove k è il numero di classi
in cui, il numero di categorie è pari a 2, SAMME si comporta come AdaBoost Breiman.
In una qualsiasi delle tre implementazioni (Freund, Breiman o SAMME), il nuovo peso per la (b + 1)esima iterazione sarà

Successivamente, i pesi vengono tutti riadattati alla somma di 1. Di conseguenza, i pesi assegnati alle osservazioni a cui sono stati assegnati valori predetti imprecisi vengono aumentati e i pesi assegnati alle osservazioni a cui sono stati assegnati valori predetti accurati vengono diminuiti. Questa regolazione costringe il modello di regressione successivo a dare maggiore enfasi ai record a cui sono state assegnate previsioni imprecise. (Questo ? la costante viene anche utilizzata nel calcolo finale, che darà più influenza al modello di regressione con l’errore più basso.) Questo processo si ripete fino a b = Numero di studenti deboli. L’algoritmo calcola quindi la media ponderata tra tutti gli studenti deboli e assegna quel valore al record. L’aumento produce generalmente modelli migliori rispetto all’insacco; tuttavia, ha uno svantaggio in quanto non è parallelizzabile. Di conseguenza, se il numero di studenti deboli è elevato, il potenziamento non sarebbe adatto.
Il metodo random trees (random forests) è una variante dell’insaccamento. Questo metodo funziona addestrando più alberi di regressione deboli usando un numero fisso di caratteristiche selezionate casualmente (sqrt per la classificazione e il numero di caratteristiche/3 per la previsione), quindi prende il valore medio per gli studenti deboli e assegna quel valore al predittore forte. In genere, il numero di alberi deboli generati potrebbe variare da diverse centinaia a diverse migliaia a seconda delle dimensioni e della difficoltà del set di allenamento. Gli alberi casuali sono parallelizzabili, poiché sono una variante dell’insaccamento. Tuttavia, poiché gli alberi tandom selezionano una quantità limitata di funzionalità in ogni iterazione, le prestazioni degli alberi casuali sono più veloci dell’insacco.
I metodi di regressione Tree Ensemble sono metodi molto potenti e in genere si traducono in prestazioni migliori rispetto a un singolo albero. Questa aggiunta di funzionalità in XLMiner V2015 fornisce modelli di previsione più accurati e deve essere considerata sul metodo ad albero singolo.