Blog
In un precedente post sul blog, abbiamo discusso di come i supermercati utilizzano i dati per comprendere meglio le esigenze dei consumatori e, in definitiva, aumentare la loro spesa complessiva. Una delle tecniche chiave utilizzate dalla grande distribuzione è chiamata Market Basket Analysis (MBA), che scopre le associazioni tra i prodotti cercando combinazioni di prodotti che spesso si verificano nelle transazioni. In altre parole, consente ai supermercati di identificare le relazioni tra i prodotti che le persone acquistano. Ad esempio, i clienti che acquistano una matita e carta sono propensi a comprare una gomma o un righello.
“L’analisi del paniere di mercato consente ai rivenditori di identificare le relazioni tra i prodotti che le persone acquistano.”
i Rivenditori possono utilizzare le conoscenze acquisite da MBA in un numero di modi, tra cui:
- il Raggruppamento di prodotti che co-si verificano nella progettazione di un negozio di layout per aumentare la possibilità di cross-selling;
- Guida online motori di raccomandazione (“i clienti che hanno acquistato questo prodotto hanno anche visto questo prodotto”); e
- Targeting campagne di marketing con l’invio di coupon promozionali ai clienti per i prodotti relativi agli articoli che hanno recentemente acquistato.
Dato quanto sia popolare e prezioso l’MBA, abbiamo pensato di produrre la seguente guida passo-passo che descrive come funziona e come si potrebbe intraprendere la propria analisi del paniere di mercato.
Come funziona l’analisi del paniere di mercato?
Per eseguire un MBA è necessario prima un set di dati di transazioni. Ogni transazione rappresenta un gruppo di articoli o prodotti che sono stati acquistati insieme e spesso indicati come “itemset”. Ad esempio, un itemset potrebbe essere: {matita, carta, graffette, gomma} nel qual caso tutti questi elementi sono stati acquistati in una singola transazione.
In un MBA, le transazioni vengono analizzate per identificare le regole di associazione. Ad esempio, una regola potrebbe essere: {pencil, paper} => {rubber}. Ciò significa che se un cliente ha una transazione che contiene carta e matita, è probabile che sia interessato anche all’acquisto di una gomma.
Prima di agire su una regola, un rivenditore deve sapere se ci sono prove sufficienti per suggerire che si tradurrà in un risultato positivo. Pertanto, misuriamo la forza di una regola calcolando le seguenti tre metriche (nota che sono disponibili altre metriche, ma queste sono le tre più comunemente utilizzate):
Supporto: la percentuale di transazioni che contengono tutti gli elementi in un itemset (ad esempio, matita, carta e gomma). Maggiore è il supporto più frequentemente si verifica l’itemset. Le regole con un elevato supporto sono preferite in quanto sono probabilmente applicabili a un gran numero di transazioni future.
Fiducia: la probabilità che una transazione che contiene gli elementi sul lato sinistro della regola (nel nostro esempio, matita e carta) contenga anche l’elemento sul lato destro (una gomma). Maggiore è la fiducia, maggiore è la probabilità che l’articolo sul lato destro verrà acquistato o, in altre parole, maggiore è il tasso di rendimento che ci si può aspettare per una determinata regola.
Sollevare: la probabilità che tutti gli elementi di una regola si verifichino insieme (altrimenti noto come supporto) diviso per il prodotto delle probabilità degli elementi sul lato sinistro e destro che si verificano come se non ci fosse alcuna associazione tra di loro. Ad esempio, se matita, carta e gomma si sono verificati insieme nel 2,5% di tutte le transazioni, matita e carta nel 10% delle transazioni e gomma nell ‘ 8% delle transazioni, allora l’ascensore sarebbe: 0.025/(0.1*0.08) = 3.125. Un aumento superiore a 1 suggerisce che la presenza di carta e matita aumenta la probabilità che si verifichi anche una gomma nella transazione. Nel complesso, lift riassume la forza di associazione tra i prodotti sul lato sinistro e destro della regola; più grande è l’ascensore maggiore è il legame tra i due prodotti.
Per eseguire un’analisi del paniere di mercato e identificare le potenziali regole, viene comunemente utilizzato un algoritmo di data mining chiamato “algoritmo Apriori”, che funziona in due fasi:
- Identificare sistematicamente set di elementi che si verificano frequentemente nel set di dati con un supporto maggiore di una soglia pre-specificata.
- Calcola la confidenza di tutte le regole possibili dati i set di elementi frequenti e mantieni solo quelli con una confidenza maggiore di una soglia pre-specificata.
Le soglie alle quali impostare il supporto e la confidenza sono specificate dall’utente e possono variare tra i set di dati delle transazioni. R ha valori predefiniti, ma ti consigliamo di sperimentarli per vedere come influenzano il numero di regole restituite (più su questo sotto). Infine, sebbene l’algoritmo Apriori non usi lift per stabilire regole, vedrai di seguito che usiamo lift quando esploriamo le regole che l’algoritmo restituisce.
Analisi del Market Basket in R
Per dimostrare come realizzare un MBA abbiamo scelto di utilizzare R e, in particolare, il pacchetto arules. Per coloro che sono interessati abbiamo incluso il codice R che abbiamo usato alla fine di questo blog.
Qui, seguiamo lo stesso esempio utilizzato nella vignetta arulesViz e utilizziamo un set di dati delle vendite di generi alimentari che contiene 9.835 transazioni individuali con 169 articoli. La prima cosa che facciamo è dare un’occhiata agli elementi nelle transazioni e, in particolare, tracciare la frequenza relativa dei 25 elementi più frequenti in Figura 1. Questo è equivalente al supporto di questi elementi in cui ogni itemset contiene solo il singolo elemento. Questo grafico a barre illustra i generi alimentari che vengono acquistati di frequente in questo negozio, ed è notevole che il supporto anche degli articoli più frequenti è relativamente basso (ad esempio, l’articolo più frequente si verifica solo in circa il 2,5% delle transazioni). Usiamo queste informazioni per informare la soglia minima quando si esegue l’algoritmo Apriori; ad esempio, sappiamo che affinché l’algoritmo restituisca un numero ragionevole di regole, dovremo impostare la soglia di supporto ben al di sotto di 0,025.
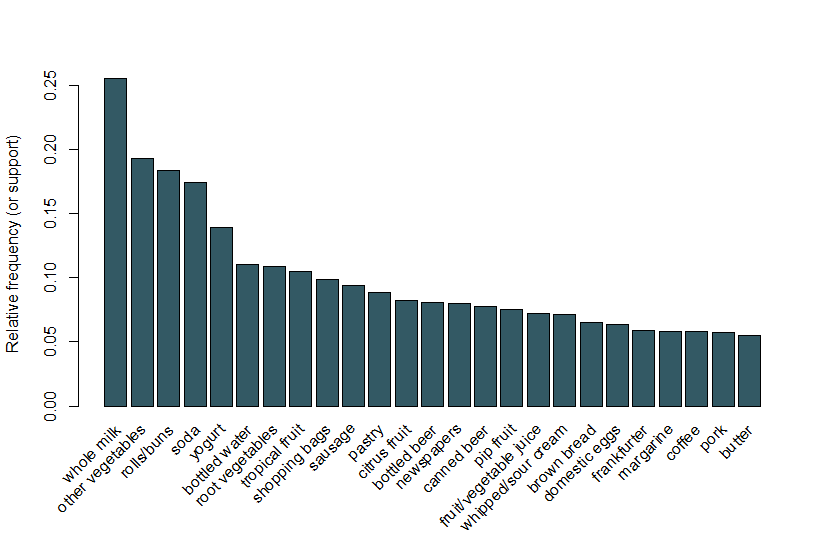
Figura 1 Un bar trama del supporto dei 25 articoli più frequenti acquistati.
Impostando una soglia di supporto di 0.001 e confidenza di 0.5, possiamo eseguire l’algoritmo Apriori e ottenere un set di 5.668 risultati. Questi valori di soglia vengono scelti in modo che il numero di regole restituite sia elevato, ma questo numero si ridurrebbe se aumentassimo entrambe le soglie. Raccomandiamo di sperimentare queste soglie per ottenere i valori più appropriati. Mentre ci sono troppe regole, per essere in grado di guardare tutti individualmente, siamo in grado di guardare le cinque regole, con il più grande ascensore:
| Regola | Supporto | Fiducia | Ascensore |
| {immediata di prodotti alimentari,bevande gassate}=>{hamburger di carne} | 0.001 | 0.632 | 19.00 |
| {soda, pop-corn}=>{snack salati} | 0.001 | 0.632 | 16.70 |
| {flour, baking powder}=>{sugar} | 0.001 | 0.556 | 16.41 |
| {ham, processed cheese}=>{white bread} | 0.002 | 0.633 | 15.05 |
| {whole milk, instant food products}=>{hamburger meat} | 0.002 | 0.500 | 15.04 |
Table 1: The five rules with the largest lift.
These rules seem to make intuitive sense. Ad esempio, la prima regola potrebbe rappresentare il tipo di oggetti acquistati per un barbecue, la seconda per una serata al cinema e la terza per la cottura.
Invece di utilizzare le soglie per ridurre le regole a un insieme più piccolo, è normale restituire un insieme più ampio di regole in modo che vi sia una maggiore possibilità di generare regole pertinenti. In alternativa, possiamo utilizzare tecniche di visualizzazione per ispezionare l’insieme di regole restituite e identificare quelle che potrebbero essere utili.
Utilizzando il pacchetto arulesViz, tracciamo le regole per fiducia, supporto e sollevamento in Figura 2. Questa trama illustra la relazione tra le diverse metriche. È stato dimostrato che le regole ottimali sono quelle che si trovano su quello che è noto come il “limite di supporto-fiducia”. Essenzialmente, queste sono le regole che si trovano sul bordo destro della trama in cui il supporto, la fiducia o entrambi sono massimizzati. La funzione plot nel pacchetto arulesViz ha un’utile funzione interattiva che consente di selezionare singole regole (facendo clic sul punto dati associato), il che significa che le regole sul bordo possono essere facilmente identificate.
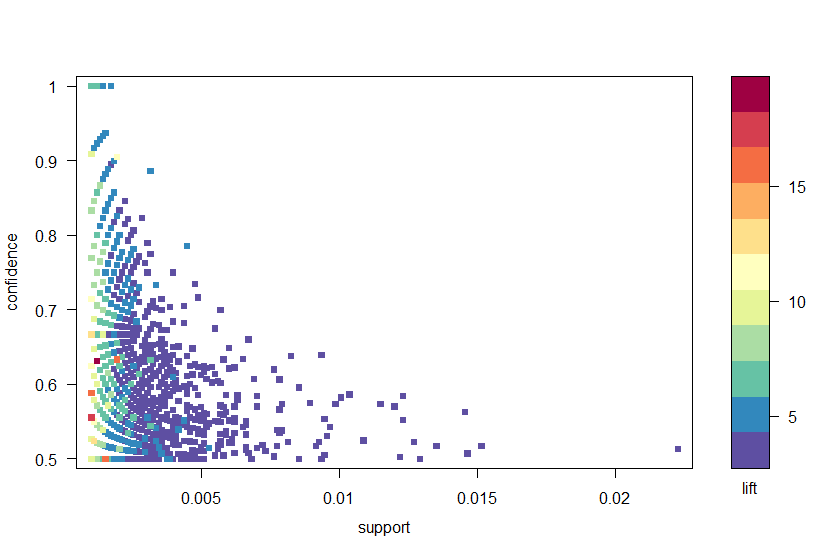
Figura 2: Un grafico a dispersione delle metriche di fiducia, supporto e sollevamento.
Ci sono molti altri grafici disponibili per visualizzare le regole, ma un’altra figura che raccomandiamo di esplorare è la visualizzazione basata sul grafico (vedi Figura 3) delle prime dieci regole in termini di sollevamento (puoi includere più di dieci, ma questi tipi di grafici possono facilmente essere ingombri). In questo grafico gli elementi raggruppati attorno a un cerchio rappresentano un insieme di elementi e le frecce indicano la relazione nelle regole. Ad esempio, una regola è che l’acquisto di zucchero è associato all’acquisto di farina e lievito. La dimensione del cerchio rappresenta il livello di confidenza associato alla regola e il colore il livello di sollevamento (più grande è il cerchio e più scuro è il grigio, meglio è).
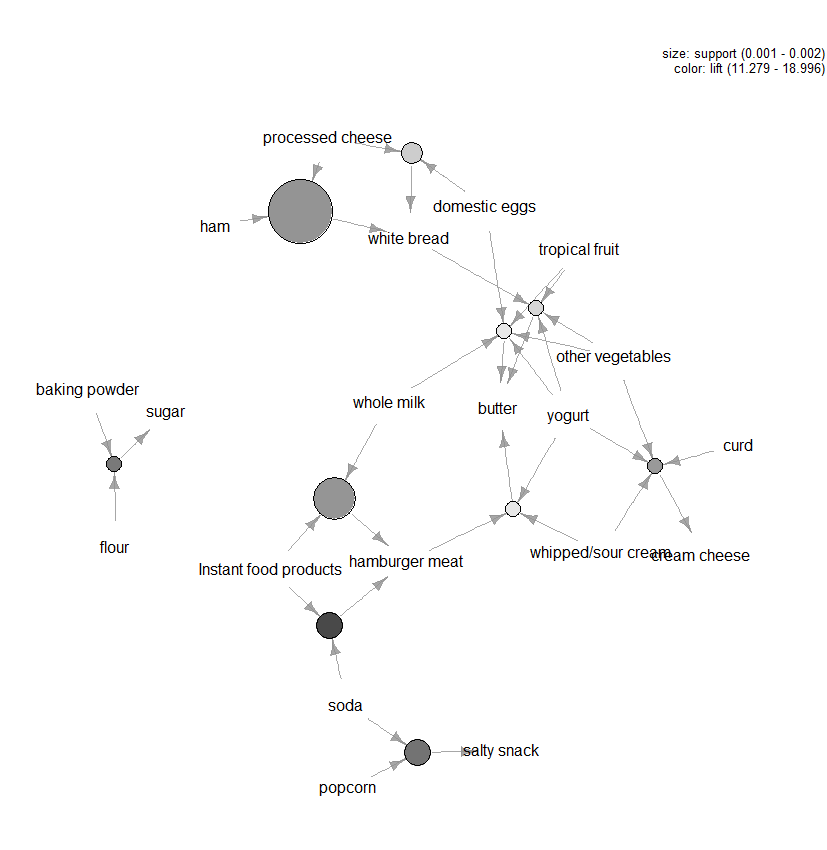
Figura 3: Visualizzazione grafica delle prime dieci regole in termini di lift.
Market Basket Analysis è uno strumento utile per i rivenditori che vogliono capire meglio le relazioni tra i prodotti che le persone acquistano. Ci sono molti strumenti che possono essere applicati quando si esegue l’MBA e gli aspetti più complicati dell’analisi sono l’impostazione delle soglie di fiducia e supporto nell’algoritmo Apriori e l’identificazione di quali regole vale la pena perseguire. In genere quest’ultimo viene fatto misurando le regole in termini di metriche che riassumono quanto siano interessanti, utilizzando tecniche di visualizzazione e anche statistiche multivariate più formali. In definitiva, la chiave per MBA è estrarre valore dai dati delle transazioni costruendo una comprensione delle esigenze dei tuoi consumatori. Questo tipo di informazioni è prezioso se sei interessato ad attività di marketing come cross-selling o campagne mirate.
Se vuoi saperne di più su come analizzare i dati delle transazioni, ti preghiamo di contattarci e saremo lieti di aiutarti.
R Code
library("arules")
library("arulesViz")
#Load data set:
data("Groceries")
summary(Groceries)
#Look at data:
inspect(Groceries)
LIST(Groceries)
#Calculate rules using apriori algorithm and specifying support and confidence thresholds:
rules = apriori(Groceries, parameter=list(support=0.001, confidence=0.5))
#Inspect the top 5 rules in terms of lift:
inspect(head(sort(rules, by ="lift"),5))
#Plot a frequency plot:
itemFrequencyPlot(Groceries, topN = 25)
#Scatter plot of rules:
library("RColorBrewer")
plot(rules,control=list(col=brewer.pal(11,"Spectral")),main="")
#Rules with high lift typically have low support.
#The most interesting rules reside on the support/confidence border which can be clearly seen in this plot.