Come fare i conti con Reinforcement Learning via Markov Decision Process
Questo articolo è stato pubblicato come parte del Data Science Blogathon.
Introduzione
Reinforcement Learning (RL) è una metodologia di apprendimento con cui lo studente impara a comportarsi in un ambiente interattivo utilizzando le proprie azioni e ricompense per le sue azioni. Lo studente, spesso chiamato agente, scopre quali azioni danno la massima ricompensa sfruttandole ed esplorandole.

Una domanda chiave è: in che modo RL è diverso dall’apprendimento supervisionato e non supervisionato?
La differenza arriva nella prospettiva dell’interazione. L’apprendimento supervisionato indica direttamente all’utente/agente quale azione deve eseguire per massimizzare la ricompensa utilizzando un set di dati di formazione di esempi etichettati. D’altra parte, RL consente direttamente l’agente di fare uso di ricompense (positivo e negativo) si arriva a selezionare la sua azione. È quindi diverso dall’apprendimento non supervisionato anche perché l’apprendimento non supervisionato consiste nel trovare una struttura nascosta in raccolte di dati non etichettati.
di Apprendimento di Rinforzo Formulazione attraverso il Processo di Decisione di Markov (MDP)
Gli elementi di base di un rinforzo problema di apprendimento sono:
- Ambiente: Il mondo esterno con il quale l’agente interagisce
- Stato: lo stato Attuale dell’agente
- Ricompensa: Numerico del segnale di feedback dall’ambiente
- la Politica: Metodo per mappare l’agente dello stato per azioni. Una politica viene utilizzata per selezionare un’azione in un dato stato
- Valore: ricompensa futura (ricompensa ritardata) che un agente riceverebbe intraprendendo un’azione in un dato stato
Il processo decisionale di Markov (MDP) è un framework matematico per descrivere un ambiente nell’apprendimento di rinforzo. La figura seguente mostra l’interazione agente-ambiente in MDP:
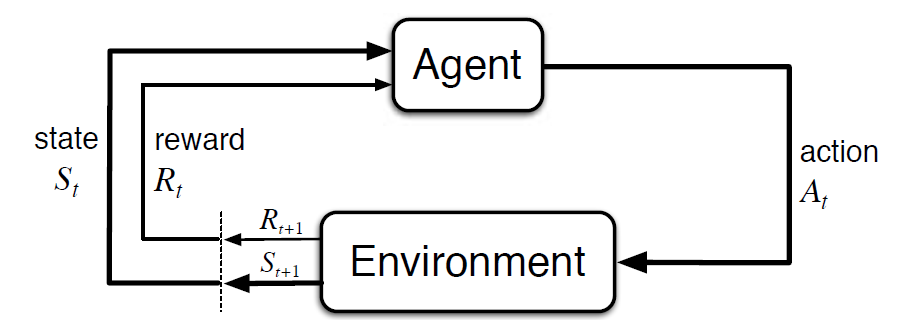
Più specificamente, l’agente e l’ambiente interagiscono in ogni tempo discreto passaggio, t = 0, 1, 2, 3…Ad ogni passo di tempo, l’agente riceve informazioni circa l’ambiente di stato di San Basato sull’ambiente di stato all’istante t, l’agente sceglie un’azione. Nell’istante successivo, l’agente riceve anche un segnale di ricompensa numerico Rt + 1. Ciò dà quindi origine a una sequenza come S0, A0, R1, S1, A1, R2
Le variabili casuali Rt e St hanno distribuzioni di probabilità discrete ben definite. Queste distribuzioni di probabilità dipendono solo dallo stato precedente e dall’azione in virtù della Proprietà di Markov. Sia S, A e R l’insieme di stati, azioni e ricompense. Quindi la probabilità che i valori di St, Rt e A prendere i valori di s’, r e a con precedente stato s è data da,
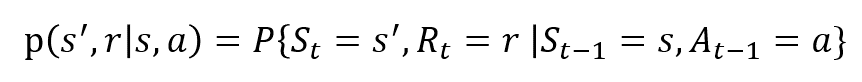
La funzione p a controllare la dinamica del processo.
Capiamo questo Usando un esempio
Discutiamo ora un semplice esempio in cui RL può essere utilizzato per implementare una strategia di controllo per un processo di riscaldamento.
L’idea è di controllare la temperatura di una stanza entro i limiti di temperatura specificati. La temperatura all’interno della stanza è influenzata da fattori esterni come la temperatura esterna,il calore interno generato, ecc.
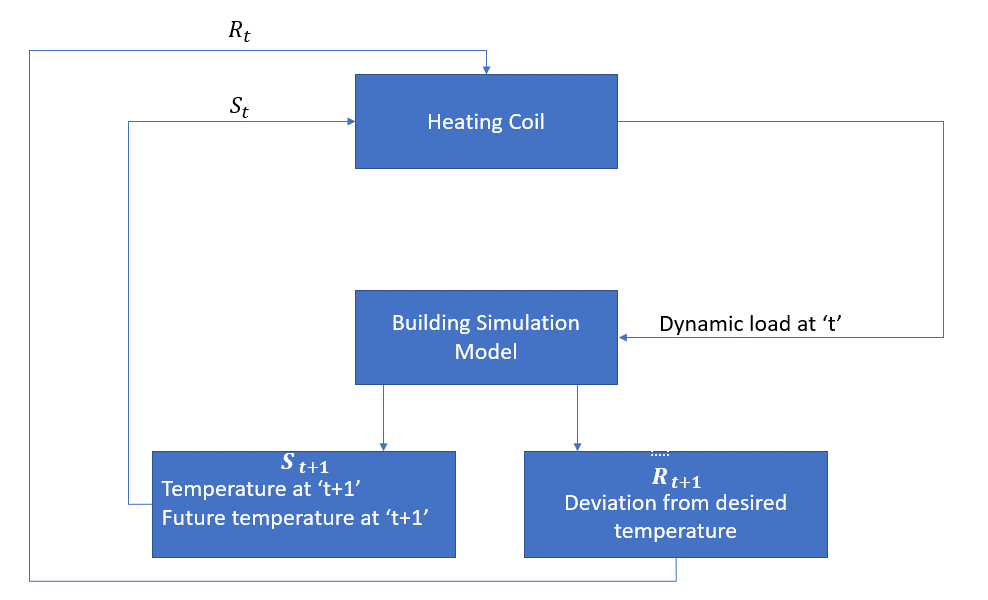
L’agente, in questo caso, è la bobina di riscaldamento che deve decidere la quantità di calore necessaria per controllare la temperatura all’interno della stanza interagendo con l’ambiente e garantire che la temperatura all’interno della stanza sia all’interno dell’intervallo specificato. La ricompensa, in questo caso, è fondamentalmente il costo pagato per deviare dai limiti di temperatura ottimali.
L’azione per l’agente è il carico dinamico. Questo carico dinamico viene quindi alimentato al simulatore di camera che è fondamentalmente un modello di trasferimento di calore che calcola la temperatura in base al carico dinamico. Quindi, in questo caso, l’ambiente è il modello di simulazione. La variabile di stato St contiene i premi presenti e futuri.
Il seguente diagramma a blocchi spiega come MDP può essere usato per controllare la temperatura all’interno di una stanza:
i Limiti di questo Metodo
il Rafforzamento dell’apprendimento impara dallo stato. Lo stato è l’input per la definizione delle politiche. Quindi, gli input di stato dovrebbero essere forniti correttamente. Inoltre, come abbiamo visto, ci sono più variabili e la dimensionalità è enorme. Quindi usarlo per sistemi fisici reali sarebbe difficile!
Ulteriori letture
Per saperne di più su RL, i seguenti materiali potrebbero essere utili:
- Reinforcement Learning: An Introduction by Richard.S. Sutton e Andrew.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- Video Lezioni da David Silver disponibile su YouTube
- https://gym.openai.com/ è un toolkit per ulteriori esplorazioni
puoi leggere anche questo articolo sulla nostra APP Mobile ![]()
