Come fare Segmentazione semantica utilizzando Deep learning
Questo articolo è una panoramica completa che include una guida passo-passo per implementare un modello di segmentazione delle immagini deep learning.
Abbiamo condiviso un nuovo blog aggiornato sulla segmentazione semantica qui: A 2021 guide to Semantic Segmentation
Oggigiorno, la segmentazione semantica è uno dei problemi chiave nel campo della visione artificiale. Guardando il quadro generale, la segmentazione semantica è uno dei compiti di alto livello che apre la strada verso la completa comprensione della scena. L’importanza della comprensione della scena come problema principale della visione artificiale è evidenziata dal fatto che un numero crescente di applicazioni si nutre di inferire la conoscenza dalle immagini. Alcune di queste applicazioni includono veicoli a guida autonoma, interazione uomo-computer, realtà virtuale, ecc. Con la popolarità del deep learning negli ultimi anni, molti problemi di segmentazione semantica vengono affrontati utilizzando architetture profonde, il più delle volte Reti neurali convoluzionali, che superano altri approcci con un ampio margine in termini di accuratezza ed efficienza.
- Che cos’è la segmentazione semantica?
- Quali sono gli approcci di segmentazione semantica esistenti?
- 1 — Segmentazione semantica basata sulla regione
- 2 — Segmentazione semantica completamente convoluzionale basata sulla rete
- 3 — Segmentazione semantica debolmente supervisionata
- Fare segmentazione semantica con rete completamente convoluzionale
- Passo 1
- Passo 2
- Step 3
- Passo 4
- Passo 5
- Potresti essere interessato ai nostri ultimi post su:
Che cos’è la segmentazione semantica?
La segmentazione semantica è un passo naturale nella progressione dall’inferenza grossolana a quella fine:l’origine potrebbe essere localizzata alla classificazione, che consiste nel fare una previsione per un intero input.Il passo successivo è la localizzazione / rilevamento, che forniscono non solo le classi ma anche informazioni aggiuntive riguardanti la posizione spaziale di tali classi.Infine, la segmentazione semantica raggiunge inferenza a grana fine facendo previsioni dense inferendo etichette per ogni pixel, in modo che ogni pixel sia etichettato con la classe della sua regione minerale oggetto che racchiude.
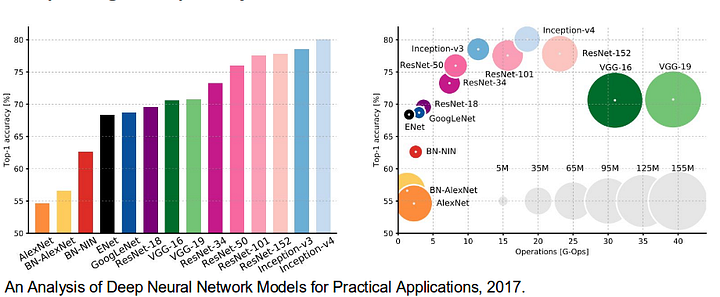
e ‘ anche degno di revisione di alcuni standard profonda reti che hanno apportato significativi contributi nel campo della computer vision, in quanto sono spesso utilizzati come base di semantica segmentazione dei sistemi:
- AlexNet: Toronto pionieristico profonda CNN che ha vinto il 2012 ImageNet concorrenza con un test di precisione di 84,6%. Si compone di 5 strati convoluzionali, quelli max-pooling, ReLUs come non linearità, 3 strati completamente convoluzionali, e dropout.
- VGG-16: Questo modello di Oxford ha vinto il concorso ImageNet 2013 con una precisione del 92,7%. Utilizza una pila di strati di convoluzione con piccoli campi ricettivi nei primi strati invece di pochi strati con grandi campi ricettivi.
- GoogLeNet: Questa rete di Google ha vinto il concorso ImageNet 2014 con una precisione del 93,3%. È composto da 22 strati e un blocco di costruzione di nuova introduzione chiamato inception module. Il modulo è costituito da un livello di rete in rete, un’operazione di pooling, uno strato di convoluzione di grandi dimensioni e uno strato di convoluzione di piccole dimensioni.
- ResNet: Questo modello di Microsoft ha vinto il concorso ImageNet 2016 con una precisione del 96,4%. È ben noto per la sua profondità (152 strati) e l’introduzione di blocchi residui. I blocchi residui affrontano il problema della formazione di un’architettura veramente profonda introducendo connessioni identity skip in modo che i livelli possano copiare i loro input al livello successivo.
Quali sono gli approcci di segmentazione semantica esistenti?
Un’architettura di segmentazione semantica generale può essere ampiamente pensata come una rete di encoder seguita da una rete di decodificatori:
- L’encoder è solitamente una rete di classificazione pre-addestrata come VGG/ResNet seguita da una rete di decodificatori.
- Il compito del decodificatore è quello di proiettare semanticamente le caratteristiche discriminative (risoluzione inferiore) apprese dall’encoder sullo spazio pixel (risoluzione superiore) per ottenere una classificazione densa.
A differenza della classificazione in cui il risultato finale della rete molto profonda è l’unica cosa importante, la segmentazione semantica richiede non solo la discriminazione a livello di pixel, ma anche un meccanismo per proiettare le caratteristiche discriminatorie apprese nelle diverse fasi dell’encoder sullo spazio pixel. Approcci diversi impiegano diversi meccanismi come parte del meccanismo di decodifica. Esploriamo i 3 approcci principali:
1 — Segmentazione semantica basata sulla regione
I metodi basati sulla regione seguono generalmente la pipeline “segmentazione usando il riconoscimento”, che estrae prima le regioni a forma libera da un’immagine e le descrive, seguita dalla classificazione basata sulla regione. Al momento del test, le previsioni basate sulla regione vengono trasformate in previsioni di pixel, di solito etichettando un pixel in base alla regione di punteggio più alta che lo contiene.
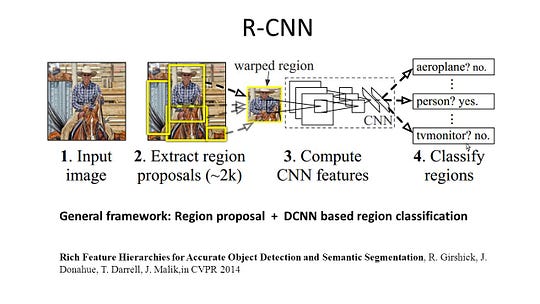
R-CNN (Regions with CNN feature) è un lavoro rappresentativo per i metodi basati sulla regione. Esegue la segmentazione semantica in base ai risultati del rilevamento degli oggetti. Per essere precisi, R-CNN utilizza prima la ricerca selettiva per estrarre una grande quantità di proposte di oggetti e quindi calcola le funzionalità CNN per ciascuna di esse. Infine, classifica ogni regione utilizzando gli SVM lineari specifici della classe. Rispetto alle tradizionali strutture CNN che sono principalmente destinate alla classificazione delle immagini, R-CNN può affrontare compiti più complicati, come il rilevamento di oggetti e la segmentazione delle immagini, e diventa anche una base importante per entrambi i campi. Inoltre, R-CNN può essere costruito su qualsiasi struttura di benchmark CNN, come AlexNet, VGG, GoogLeNet e ResNet.
Per l’attività di segmentazione delle immagini, R-CNN ha estratto 2 tipi di funzionalità per ogni regione: funzionalità regione completa e funzionalità primo piano e ha scoperto che potrebbe portare a prestazioni migliori quando le concatenano insieme come funzionalità regione. R-CNN ha ottenuto significativi miglioramenti delle prestazioni grazie all’utilizzo delle funzionalità CNN altamente discriminative. Tuttavia, soffre anche di un paio di inconvenienti per l’attività di segmentazione:
- La funzione non è compatibile con l’attività di segmentazione.
- La funzione non contiene informazioni spaziali sufficienti per una generazione precisa dei confini.
- La generazione di proposte basate su segmenti richiede tempo e influirebbe notevolmente sulle prestazioni finali.
A causa di questi colli di bottiglia, recenti ricerche sono state proposte per affrontare i problemi, tra cui SDS, ipercolumni, Maschera R-CNN.
2 — Segmentazione semantica completamente convoluzionale basata sulla rete
La rete completamente convoluzionale originale (FCN) impara una mappatura da pixel a pixel, senza estrarre le proposte della regione. La pipeline di rete FCN è un’estensione della CNN classica. L’idea principale è quella di rendere la CNN classica prendere come input immagini di dimensioni arbitrarie. La restrizione delle CNN di accettare e produrre etichette solo per input di dimensioni specifiche proviene dai livelli completamente collegati che sono fissi. Contrariamente a loro, le FCN hanno solo livelli convoluzionali e di pooling che danno loro la possibilità di fare previsioni su input di dimensioni arbitrarie.
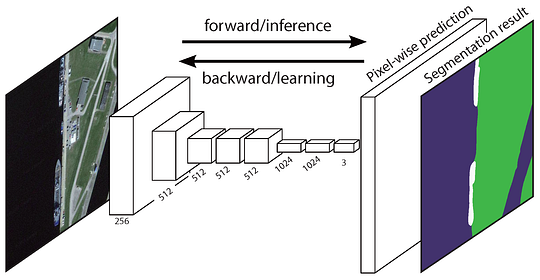
Un problema in questo specifico FCN è che propagando attraverso diversi livelli convoluzionali e di pool alternati, la risoluzione delle mappe di funzionalità di output è giù campionato. Pertanto, le previsioni dirette di FCN sono in genere a bassa risoluzione, con conseguente confini oggetto relativamente sfocati. Una varietà di approcci più avanzati basati su FCN sono stati proposti per affrontare questo problema, tra cui SegNet, DeepLab-CRF e Circonvoluzioni dilatate.
3 — Segmentazione semantica debolmente supervisionata
La maggior parte dei metodi rilevanti nella segmentazione semantica si basa su un gran numero di immagini con maschere di segmentazione in pixel. Tuttavia, annotare manualmente queste maschere è piuttosto dispendioso in termini di tempo, frustrante e commercialmente costoso. Pertanto, sono stati recentemente proposti alcuni metodi debolmente supervisionati, che sono dedicati a soddisfare la segmentazione semantica utilizzando caselle di delimitazione annotate.

Ad esempio, Boxsup ha impiegato le annotazioni dei riquadri di delimitazione come supervisione per addestrare la rete e migliorare iterativamente le maschere stimate per la segmentazione semantica. Semplice Ha trattato la debole limitazione della supervisione come un problema di rumore dell’etichetta di input e ha esplorato la formazione ricorsiva come una strategia di de-noising. L’etichettatura a livello di pixel ha interpretato l’attività di segmentazione all’interno del framework di apprendimento a più istanze e ha aggiunto un livello aggiuntivo per vincolare il modello per assegnare più peso ai pixel importanti per la classificazione a livello di immagine.
Fare segmentazione semantica con rete completamente convoluzionale
In questa sezione, camminiamo attraverso un’implementazione passo-passo dell’architettura più popolare per la segmentazione semantica-la rete completamente convoluzionale (FCN). Lo implementeremo usando la libreria TensorFlow in Python 3, insieme ad altre dipendenze come Numpy e Scipy.In questo esercizio etichetteremo i pixel di una strada in immagini usando FCN. Lavoreremo con il set di dati Kitti Road per il rilevamento di strade / corsie. Questo è un semplice esercizio dal programma di auto-guida auto Nano-degree di Udacity, che puoi saperne di più sulla configurazione in questo repository GitHub.

Ecco le caratteristiche principali del COFA architettura:
- FCN trasferimenti di conoscenza da VGG16 per eseguire semantica di segmentazione.
- I livelli completamente connessi di VGG16 vengono convertiti in livelli completamente convoluzionali, utilizzando la convoluzione 1×1. Questo processo produce una mappa di calore di presenza di classe a bassa risoluzione.
- L’upsampling di queste mappe semantiche a bassa risoluzione viene effettuato utilizzando circonvoluzioni trasposte (inizializzate con filtri di interpolazione bilineari).
- In ogni fase, il processo di upsampling viene ulteriormente perfezionato aggiungendo funzionalità da mappe di funzionalità più grossolane ma a risoluzione più elevata dai livelli inferiori in VGG16.
- La connessione skip viene introdotta dopo ogni blocco di convoluzione per consentire al blocco successivo di estrarre funzionalità più astratte e salienti della classe dalle funzionalità precedentemente raggruppate.
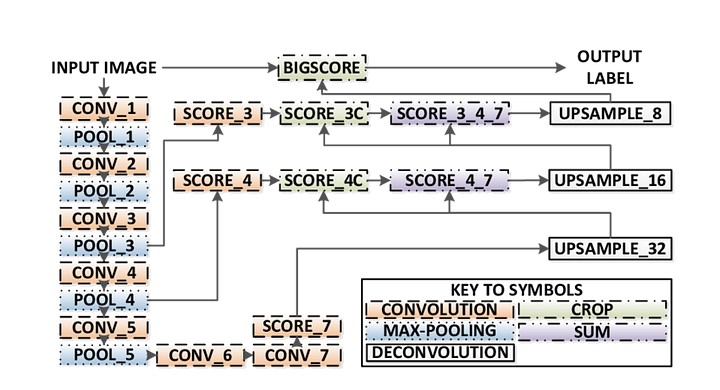
Esistono 3 versioni di FCN (FCN-32, FCN-16, FCN-8). Implementeremo FCN-8, come dettagliato passo dopo passo di seguito:
- Encoder: un VGG16 pre-addestrato viene utilizzato come encoder. Il decoder inizia dal livello 7 di VGG16.
- FCN Layer-8: L’ultimo livello completamente connesso di VGG16 viene sostituito da una convoluzione 1×1.
- FCN Strato-9: FCN Layer-8 è upsampled 2 volte per abbinare le dimensioni con il livello 4 di VGG 16, usando la convoluzione trasposta con i parametri: (kernel=(4,4), stride=(2,2), paddding=’same’). Successivamente, è stata aggiunta una connessione skip tra il livello 4 di VGG16 e il livello FCN-9.
- FCN Layer-10: FCN Layer-9 è upsampled 2 volte per abbinare le dimensioni con il livello 3 di VGG16, usando la convoluzione trasposta con i parametri: (kernel=(4,4), stride=(2,2), paddding=’same’). Successivamente, è stata aggiunta una connessione di salto tra il livello 3 di VGG 16 e il livello FCN-10.
- FCN Strato-11: FCN Layer-10 è upsampled 4 volte per abbinare le dimensioni con la dimensione dell’immagine di input in modo da ottenere l’immagine reale indietro e la profondità è uguale al numero di classi, usando la convoluzione trasposta con i parametri:(kernel=(16,16), stride=(8,8), paddding=’same’).
Passo 1
caricare prima il pre-formati VGG-16 modello in TensorFlow. Prendendo la sessione TensorFlow e il percorso della cartella VGG (che è scaricabile qui), restituiamo la tupla di tensori dal modello VGG, incluso l’input dell’immagine, keep_prob (per controllare il tasso di abbandono), layer 3, layer 4 e layer 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7Funzione VGG16
Passo 2
Ora ci concentriamo sulla creazione dei livelli per un FCN, utilizzando i tensori del modello VGG. Dati i tensori per l’output del livello VGG e il numero di classi da classificare, restituiamo il tensore per l’ultimo livello di quell’output. In particolare, applichiamo una convoluzione 1×1 ai livelli encoder, quindi aggiungiamo i livelli decoder alla rete con connessioni saltate e upsampling.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11Layers function
Step 3
Il passo successivo è quello di ottimizzare la nostra rete neurale, ovvero costruire funzioni di perdita di TensorFlow e operazioni di ottimizzazione. Qui usiamo l’entropia incrociata come nostra funzione di perdita e Adam come nostro algoritmo di ottimizzazione.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opFunzione di ottimizzazione
Passo 4
Qui definiamo la funzione train_nn, che prende in parametri importanti tra cui il numero di epoche, dimensione del lotto, funzione di perdita, funzionamento ottimizzatore, e segnaposto per le immagini di input, immagini di etichette, tasso di apprendimento. Per il processo di formazione, abbiamo anche impostato keep_probability a 0.5 e learning_rate a 0.001. Per tenere traccia dei progressi, stampiamo anche la perdita durante l’allenamento.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Passo 5
Finalmente, è il momento di allenare la nostra rete! In questa funzione di esecuzione, per prima cosa costruiamo la nostra rete usando la funzione load_vgg, layers e optimize. Quindi alleniamo la rete usando la funzione train_nn e salviamo i dati di inferenza per i record.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)Esegui la funzione
Informazioni sui nostri parametri, scegliamo epochs = 40, batch_size = 16, num_classes = 2 e image_shape = (160, 576). Dopo aver eseguito 2 passaggi di prova con dropout = 0.5 e dropout = 0.75, abbiamo scoperto che il 2nd trial produce risultati migliori con perdite medie migliori.

Per vedere il codice completo, check out questo link: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
Se ti è piaciuto questo pezzo, Mi piacerebbe condividere 👏 e diffondere la conoscenza.
Potresti essere interessato ai nostri ultimi post su:
- AWS Textract
- Data Extraction
Inizia a usare Nanonets per l’automazione
Prova il modello o richiedi una demo oggi stesso!
PROVA ORA
