Reading Code Right, With Some Help From The Lexer
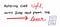
Software is all about logic. Programmazione ha raccolto la reputazione di essere un campo che è pesante sulla matematica e equazioni folli. E l’informatica sembra essere al centro di questo equivoco.
Certo, c’è un po ‘ di matematica e ci sono alcune formule — ma nessuno di noi ha effettivamente bisogno di avere dottorati di ricerca in calcolo per capire come funzionano le nostre macchine! In effetti, molte delle regole e dei paradigmi che impariamo nel processo di scrittura del codice sono le stesse regole e paradigmi che si applicano a concetti complessi di informatica. E a volte, quelle idee in realtà derivano dall’informatica, e semplicemente non lo sapevamo mai.
Indipendentemente dal linguaggio di programmazione che usiamo, quando la maggior parte di noi scrive il nostro codice, miriamo a incapsulare cose distinte in classi, oggetti o metodi, separando intenzionalmente le diverse parti del nostro codice. In altre parole, sappiamo che è generalmente buono dividere il nostro codice in modo che una classe, un oggetto o un metodo siano interessati e responsabili solo di una singola cosa. Se non lo facessimo, le cose potrebbero diventare super disordinate e intrecciate in un pasticcio di una rete. A volte questo accade ancora, anche con la separazione delle preoccupazioni.
A quanto pare, anche il funzionamento interno dei nostri computer segue paradigmi di progettazione molto simili. Il nostro compilatore, ad esempio, ha parti diverse e ogni parte è responsabile della gestione di una parte specifica del processo di compilazione. Abbiamo incontrato un po ‘ di questo la scorsa settimana, quando abbiamo imparato a conoscere il parser, che è responsabile della creazione di alberi di analisi. Ma il parser non può essere incaricato di tutto.
Il parser ha bisogno di aiuto dai suoi amici, ed è finalmente giunto il momento per noi di imparare chi sono!
Quando abbiamo appreso l’analisi di recente, abbiamo immerso le dita dei piedi nella grammatica, nella sintassi e in che modo il compilatore reagisce e risponde a quelle cose all’interno di un linguaggio di programmazione. Ma non abbiamo mai evidenziato cosa sia esattamente un compilatore! Entrando nel funzionamento interno del processo di compilazione, impareremo molto sulla progettazione del compilatore, quindi è fondamentale per noi capire di cosa stiamo parlando esattamente qui.
I compilatori possono sembrare un po ‘ spaventosi, ma i loro lavori non sono in realtà troppo complessi da capire, in particolare quando suddividiamo le diverse parti di un complier in parti di dimensioni ridotte.
Ma prima, iniziamo con la definizione più semplice possibile. Un compilatore è un programma che legge il nostro codice (o qualsiasi codice, in qualsiasi linguaggio di programmazione) e lo traduce in un’altra lingua.

In generale, un compilatore tradurrà sempre e solo il codice da un linguaggio di alto livello in un linguaggio di livello inferiore. I linguaggi di livello inferiore in cui un compilatore traduce il codice vengono spesso definiti codice assembly, codice macchina o codice oggetto. Vale la pena ricordare che la maggior parte dei programmatori non si occupa o scrive alcun codice macchina; piuttosto, dipendiamo dal compilatore per prendere i nostri programmi e tradurli in codice macchina, che è ciò che il nostro computer verrà eseguito come un programma eseguibile.
Possiamo pensare ai compilatori come l’intermediario tra noi, i programmatori e i nostri computer, che possono eseguire solo programmi eseguibili in linguaggi di livello inferiore.
Il compilatore fa il lavoro di tradurre ciò che vogliamo che accada in un modo che sia comprensibile ed eseguibile dalle nostre macchine.
Senza il compilatore, saremmo costretti a comunicare con i nostri computer scrivendo codice macchina, che è incredibilmente illeggibile e difficile da decifrare. Il codice macchina può spesso sembrare un mucchio di 0 e 1 all’occhio umano — è tutto binario, ricordi? – che lo rende super difficile da leggere, scrivere ed eseguire il debug. Il compilatore ha sottratto il codice macchina per noi programmatori, perché ci ha reso molto facile non pensare al codice macchina e scrivere programmi usando linguaggi molto più eleganti, chiari e facili da leggere.
Continueremo a decomprimere sempre di più il misterioso compilatore nelle prossime settimane, il che, si spera, lo renderà meno un enigma nel processo. Ma per ora, torniamo alla domanda a portata di mano: quali sono le parti più semplici possibili di un compilatore?
Ogni compilatore, indipendentemente da come potrebbe essere progettato, ha fasi distinte. Queste fasi sono il modo in cui possiamo distinguere le parti uniche del compilatore.

Abbiamo già incontrato una delle fasi delle nostre avventure di compilazione quando abbiamo recentemente appreso degli alberi parser e parse. Sappiamo che l’analisi è il processo di prendere qualche input e costruire un albero di analisi fuori di esso, che a volte viene indicato come l’atto di analisi. A quanto pare, il lavoro di analisi è specifico per una fase del processo di compilazione chiamata analisi della sintassi.
Tuttavia, il parser non si limita a costruire un albero di analisi dal nulla. Ha qualche aiuto! Ricordiamo che il parser riceve alcuni token (chiamati anche terminali) e costruisce un albero di analisi da quei token. Ma da dove prende quei token? Fortunatamente per il parser, non deve funzionare nel vuoto; invece, ha qualche aiuto.
Questo ci porta ad un’altra fase del processo di compilazione, quella che precede la fase di analisi della sintassi: la fase di analisi lessicale.

Il termine “lessicale” si riferisce al significato di una parola in isolamento dalla frase che lo contiene, e a prescindere dalla sua grammaticali contesto. Se proviamo a indovinare il nostro significato basato esclusivamente su questa definizione, potremmo ipotizzare che la fase di analisi lessicale abbia a che fare con le singole parole/termini nel programma stesso, e nulla a che fare con la grammatica o il significato della frase che contiene le parole.
La fase di analisi lessicale è il primo passo nel processo di compilazione. Non conosce o si preoccupa della grammatica di una frase o del significato di un testo o di un programma; tutto ciò che sa è il significato delle parole stesse.
L’analisi lessicale deve avvenire prima che qualsiasi codice da un programma sorgente possa essere analizzato. Prima di poter essere letto dal parser, un programma deve prima essere scansionato, diviso e raggruppato in determinati modi.
Quando abbiamo iniziato a guardare la fase di analisi della sintassi la scorsa settimana, abbiamo appreso che l’albero di analisi è costruito osservando le singole parti della frase e suddividendo le espressioni in parti più semplici. Ma durante la fase di analisi lessicale, il compilatore non conosce o ha accesso a queste “singole parti”. Piuttosto, deve prima identificarli e trovarli, e poi fare il lavoro di dividere il testo in singoli pezzi.
Ad esempio, quando leggiamo una frase di Shakespeare comeTo sleep, perchance to dream., sappiamo che gli spazi e la punteggiatura stanno dividendo le “parole” di una frase. Questo è, ovviamente, perché siamo stati addestrati a leggere una frase,” lex ” e analizzarla per la grammatica.
Ma, per un compilatore, quella stessa frase potrebbe assomigliare a questa la prima volta che la legge:Tosleepperhachancetodream. Quando leggiamo questa frase, è un po ‘ più difficile per noi determinare quali sono le “parole” reali! Sono sicuro che il nostro compilatore si sente allo stesso modo.
Così, come fa la nostra macchina affrontare questo problema? Bene, durante la fase di analisi lessicale del processo di compilazione, fa sempre due cose importanti: esegue la scansione del codice e quindi lo valuta.

Il lavoro di scansione e valutazione può talvolta essere raggruppato in un unico programma, o potrebbe essere due programmi separati che dipendono l’uno dall’altro; in realtà è solo una questione di come sia stato progettato un qualsiasi complier. Il programma all’interno del compilatore che è responsabile per fare il lavoro di scansione e valutazione è spesso indicato come il lexer o il tokenizer, e l’intera fase di analisi lessicale è talvolta chiamato il processo di lexing o tokenizing.
Per scansionare, forse per leggere
Il primo dei due passaggi fondamentali nell’analisi lessicale è la scansione. Possiamo pensare alla scansione come al lavoro di “leggere” effettivamente del testo di input. Ricorda che questo testo di input potrebbe essere una stringa, una frase, un’espressione o persino un intero programma! Non importa, perché, in questa fase del processo, è solo un gigantesco blob di personaggi che non significa ancora nulla, ed è un pezzo contiguo.
Diamo un’occhiata a un esempio per vedere come esattamente questo accade. Useremo la nostra frase originale, To sleep, perchance to dream., che è il nostro testo sorgente o codice sorgente. Per il nostro compilatore, questo testo sorgente verrà letto come testo di input simile a Tosleep,perchancetodream., che è solo una stringa di caratteri che deve ancora essere decifrata.

La prima cosa che il nostro compilatore deve fare è effettivamente dividere quel blob di testo nei suoi pezzi più piccoli possibili, il che renderà molto più facile identificare dove si trovano effettivamente le parole nel blob di testo.
Il modo più semplice per immergersi in un pezzo gigante di testo è leggerlo lentamente e sistematicamente, un carattere alla volta. E questo è esattamente ciò che fa il compilatore.
Spesso, il processo di scansione è gestito da un programma separato chiamato scanner, il cui unico compito è quello di fare il lavoro di lettura di un file sorgente / testo, un carattere alla volta. Per il nostro scanner, non importa quanto sia grande il nostro testo; tutto ciò che vedrà quando “legge” il nostro file è un carattere alla volta.
Ecco ciò che la nostra frase shakespeariana sarebbe letto come dal nostro scanner:

Noteremo cheTo sleep, perchance to dream. è stato diviso in singoli caratteri dal nostro scanner. Inoltre, anche gli spazi tra le parole vengono trattati come caratteri, così come la punteggiatura nella nostra frase. C’è anche un carattere alla fine di questa sequenza che è particolarmente interessante: eof. Questo è il carattere “fine del file”ed è simile a tabspace e newline. Poiché il nostro testo sorgente è solo una singola frase, quando il nostro scanner arriva alla fine del file (in questo caso, la fine della frase), legge la fine del file e lo tratta come un carattere.
Quindi, in realtà, quando il nostro scanner leggeva il nostro testo di input, lo interpretava come singoli caratteri che risultavano in questo:.

Ora che il nostro scanner ha letto e diviso il nostro testo sorgente nelle sue parti più piccole possibili, avrà un tempo molto più facile di capire le “parole” nella nostra frase.
Successivamente, lo scanner deve esaminare i caratteri suddivisi in ordine e determinare quali caratteri sono parti di una parola e quali no. Per ogni carattere che lo scanner legge, segna la linea e la posizione in cui quel carattere è stato trovato nel testo di origine.
L’immagine mostrata qui illustra questo processo per la nostra frase shakespeariana. Possiamo vedere che il nostro scanner sta segnando la linea e la colonna per ogni carattere nella nostra frase. Possiamo pensare alla rappresentazione di linee e colonne come una matrice o una matrice di caratteri.
Ricorda che, poiché il nostro file ha una sola riga in esso, tutto vive alla riga0. Tuttavia, mentre lavoriamo attraverso la frase, la colonna di ogni personaggio aumenta. Vale anche la pena ricordare che, poiché il nostro scanner legge spacesnewlineseof, e tutta la punteggiatura come caratteri, anche quelli appaiono nella nostra tabella dei caratteri!

Una volta che il testo sorgente è stato scansionato e contrassegnato, il nostro compilatore è pronto a trasformare questi caratteri in parole. Poiché lo scanner sa non solo dove si trovano spacesnewlines e eof nel file, ma anche dove vivono in relazione agli altri caratteri che li circondano, può scansionare i caratteri e dividerli in singole stringhe se necessario.
Nel nostro esempio, lo scanner esaminerà i caratteri T, quindi oe quindi un space. Quando trova uno spazio, dividerà To nella propria parola — la combinazione di caratteri più semplice possibile prima che lo scanner incontri uno spazio.
È una storia simile per la parola successiva che trova, che è sleep. Tuttavia, in questo scenario, legges-l-e-e-p, quindi legge un,, un segno di punteggiatura. Poiché questa virgola è affiancata da un carattere (p) e da un space su entrambi i lati, la virgola è, di per sé, considerata una “parola”.
Sia la parola sleep che il simbolo di punteggiatura , sono chiamati lessemi, che sono sottostringhe del testo sorgente. Un lessema è un raggruppamento delle più piccole sequenze possibili di caratteri nel nostro codice sorgente. I lessemi di un file sorgente sono considerati le singole “parole” del file stesso. Una volta che il nostro scanner ha finito di leggere i singoli caratteri del nostro file, restituirà un set di lessemi che assomigliano a questo: .

Si noti come il nostro scanner ha preso un blob di testo come input, che inizialmente non poteva leggere, e ha proceduto a scansionarlo una volta carattere alla volta, contemporaneamente leggendo e segnando il contenuto. Ha quindi proceduto a dividere la stringa nei loro lessemi più piccoli possibili utilizzando gli spazi e la punteggiatura tra i caratteri come delimitatori.
Tuttavia, nonostante tutto questo lavoro, a questo punto della fase di analisi lessicale, il nostro scanner non sa nulla di queste parole. Certo, divide il testo in parole di diverse forme e dimensioni, ma per quanto riguarda quelle parole lo scanner non ha idea! Le parole potrebbero essere una stringa letterale, o potrebbero essere un segno di punteggiatura, o potrebbero essere qualcos’altro completamente!
Lo scanner non sa nulla delle parole stesse o di quale “tipo” di parola siano. Sa solo dove le parole finiscono e iniziano all’interno del testo stesso.
Questo ci pone per la seconda fase dell’analisi lessicale: la valutazione. Una volta scansionato il nostro testo e suddiviso il codice sorgente in singole unità di lessema, dobbiamo valutare le parole che lo scanner ci ha restituito e capire con quali tipi di parole abbiamo a che fare — in particolare, dobbiamo cercare parole importanti che significano qualcosa di speciale nella lingua che stiamo cercando di compilare.
Valutare le parti importanti
Una volta terminata la scansione del nostro testo sorgente e identificato i nostri lessemi, avremo bisogno di fare qualcosa con il nostro lessema “parole”. Questa è la fase di valutazione dell’analisi lessicale, che viene spesso definita nel design complier come il processo di lexing o tokenizzazione del nostro input.

Quando valutiamo il nostro codice scansionato, tutto ciò che stiamo facendo è dare un’occhiata più da vicino a ciascuno dei lessemi generati dal nostro scanner. Il nostro compilatore dovrà esaminare ogni parola del lessema e decidere che tipo di parola è. Il processo di determinare quale tipo di lessema ogni “parola” nel nostro testo è il modo in cui il nostro compilatore trasforma ogni singolo lessema in un token, tokenizzando così la nostra stringa di input.
Abbiamo incontrato i token per la prima volta quando stavamo imparando a conoscere gli alberi di analisi. I token sono simboli speciali che sono al centro di ogni linguaggio di programmazione. I token ,come(, ), +, -, if, else, then, aiutano tutti un compilatore a capire come le diverse parti di un’espressione e vari elementi si relazionano tra loro. Il parser, che è centrale nella fase di analisi della sintassi, dipende dalla ricezione di token da qualche parte e quindi trasforma quei token in un albero di analisi.

Beh, indovinate un po’? Abbiamo finalmente capito il “da qualche parte”! Come risulta, i token che vengono inviati al parser vengono generati nella fase di analisi lessicale dal tokenizer, chiamato anche lexer.

Quindi, che aspetto ha esattamente un token? Un token è abbastanza semplice e di solito è rappresentato come una coppia, composta da un nome token e da un valore (che è facoltativo).
Ad esempio, se tokenizziamo la nostra stringa shakespeariana, finiremmo con token che sarebbero per lo più letterali e separatori di stringhe. Potremmo rappresentare il lessema"dream” come token in questo modo:<string literal, "dream">. In modo simile, potremmo rappresentare il lessema .come token,<separator, .>.
Noteremo che ognuno di questi token non sta modificando affatto il lessema — stanno semplicemente aggiungendo informazioni aggiuntive a loro. Un token è lessema o unità lessicale con più dettagli; in particolare, il dettaglio aggiunto ci dice quale categoria di token (che tipo di “parola”) abbiamo a che fare.
Ora che abbiamo tokenizzato la nostra frase shakespeariana, possiamo vedere che non c’è molta varietà nei tipi di token nel nostro file sorgente. La nostra frase aveva solo stringhe e punteggiatura — ma questa è solo la punta dell’iceberg del token! Ci sono molti altri tipi di “parole” in cui un lessema potrebbe essere classificato.

La tabella mostrata qui illustra alcuni dei token più comuni che il nostro compilatore vedrebbe durante la lettura di un file sorgente in praticamente qualsiasi linguaggio di programmazione. Abbiamo visto esempi di literals, che può essere qualsiasi stringa, numero, o la logica/valore booleano, come pure separators, che sono qualsiasi tipo di punteggiatura, tra parentesi graffe ({}) e le parentesi (()).
However, there are also keywords, which are terms that are reserved in the language (such as ifvarwhilereturn), as well as operators, which operate on arguments and return some value ( +-x/). Potremmo anche incontrare lessemi che potrebbero essere tokenizzati come identifiers, che di solito sono nomi di variabili o cose scritte dall’utente/programmatore per fare riferimento a qualcos’altro, così come , che potrebbero essere commenti di riga o blocco scritti dall’utente.
La nostra frase originale ci ha mostrato solo due esempi di token. Riscriviamo la nostra frase per leggere invece: var toSleep = "to dream";. Come potrebbe il nostro compilatore lex questa versione di Shakespeare?

Qui, vedremo che abbiamo una maggiore varietà di token. Abbiamo un keyword nel var, dove stiamo dichiarando una variabile, e un identifiertoSleep, che è il modo in cui siamo denominazione nostra variabile, o fa riferimento al valore a venire. Il prossimo è il nostro=, che è unoperator token, seguito dalla stringa letterale"to dream". La nostra istruzione termina con un separatore;, che indica la fine di una riga e delimita gli spazi bianchi.
Una cosa importante da notare sul processo di tokenizzazione è che non stiamo tokenizzando nessuno spazio bianco (spazi, newline, tabulazioni, fine riga, ecc.), né passarlo al parser. Ricorda che solo i token vengono dati al parser e finiranno nell’albero di analisi.
Vale anche la pena ricordare che lingue diverse avranno caratteri diversi che costituiscono come spazi bianchi. Ad esempio, in alcune situazioni, il linguaggio di programmazione Python utilizza l’indentazione, incluse schede e spazi, per indicare come cambia l’ambito di una funzione. Quindi, il tokenizer del compilatore Python deve essere consapevole del fatto che, in determinate situazioni, un tab o space in realtà deve essere tokenizzato come una parola, perché in realtà deve essere passato al parser!

Questo aspetto del tokenizer è un buon modo per contrastare il modo in cui un lexer/tokenizer è diverso da uno scanner. Mentre uno scanner è ignorante e sa solo come suddividere un testo nelle sue parti possibili più piccole (le sue “parole”), un lexer/tokenizer è molto più consapevole e più preciso in confronto.
Il tokenizer deve conoscere la complessità e le specifiche del linguaggio che viene compilato. Setabs sono importanti, deve sapere che; senewlines può avere determinati significati nella lingua compilata, il tokenizer deve essere consapevole di quei dettagli. D’altra parte, lo scanner non sa nemmeno quali sono le parole che divide, tanto meno cosa significano.
Lo scanner di un complier è molto più indipendente dal linguaggio, mentre un tokenizer deve essere specifico per la lingua per definizione.
Queste due parti del processo di analisi lessicale vanno di pari passo e sono centrali nella prima fase del processo di compilazione. Naturalmente, diversi compliers sono progettati nei loro modi unici. Alcuni compilatori eseguono la fase di scansione e tokenizzazione in un singolo processo e come un singolo programma, mentre altri li divideranno in classi diverse, nel qual caso il tokenizer chiamerà la classe scanner quando viene eseguita.

In entrambi i casi, la fase di analisi lessicale è super importante per la compilazione, perché la fase di analisi della sintassi dipende direttamente da essa. E anche se ogni parte del compilatore ha i suoi ruoli specifici, si appoggiano l’uno all’altro e dipendono l’uno dall’altro — proprio come fanno sempre i buoni amici.
Risorse
Poiché ci sono molti modi diversi per scrivere e progettare un compilatore, ci sono anche molti modi diversi per insegnarli. Se fai abbastanza ricerche sulle basi della compilazione, diventa abbastanza chiaro che alcune spiegazioni vanno molto più in dettaglio di altre, il che può o non può essere utile. Se vi trovate a voler saperne di più, di seguito sono una varietà di risorse sui compilatori — con particolare attenzione alla fase di analisi lessicale.
- Capitolo 4 — Crafting Interpreters, Robert Nystrom
- Compiler Construction, Professor Allan Gottlieb
- Compiler Basics, Professor James Alan Farrell
- Writing a programming language — the Lexer, Andy Balaam
- Notes on How Parser and Compilers Work, Stephen Raymond Ferg
- Qual è la differenza tra un token e un lessema?, StackOverflow