seaborn.histplot¶
seaborn.histplot(data=None, *, x=Nessuno, y=None, hue=None, pesi=None, stat=’count’, bidoni=’auto’, binwidth=None, binrange=None, discreto=None, cumulativo=False, common_bins=True, common_norm=True, più=’livello’, elemento=’bar’, compila=True, shrink=1, kde=False, kde_kws=None, line_kws=None, trebbia=0, pthresh=None, pmax=None, cbar=False, cbar_ax=None, cbar_kws=None, tavolozza=None, hue_order=None, hue_norm=None color=Nessuno, log_scale=None, legend=True, ax=None, **kwargs)¶
Trama univariata o bivariata istogrammi per mostrare le distribuzioni di set di dati.
Un istogramma è un classico strumento di visualizzazione che rappresenta la distribuzione di una o più variabili contando il numero di osservazioni che cadono all’interno di bidoni specifici.
Questa funzione può normalizzare la statistica calcolata all’interno di ciascun bin per stimare la frequenza, la densità o la massa di probabilità e può aggiungere una curva liscia ottenuta utilizzando una stima della densità del kernel, simile a kdeplot().
Ulteriori informazioni sono fornite nella guida per l’utente.
Parametri datipandas.DataFramenumpy.ndarray, mappatura o sequenza
Struttura dati di input. Una raccolta di vettori a forma lunga che può essere assegnata a variabili denominate o un set di dati a forma ampia che verrà configurato internamente.
x, yvectors o chiavi indata
Variabili che specificano le posizioni sugli assi x e y.
huevector o key indata
Variabile semantica mappata per determinare il colore degli elementi della trama.
weightsvector o key indata
Se fornito, ponderare il contributo dei punti dati corrispondenti verso il conteggio in ciascun bin da questi fattori.
stat{“count”, ” frequency”, “density”, “probability”}
Statistica aggregata da calcolare in ogni bin.
-
countmostra il numero di osservazioni -
frequencymostra il numero di osservazioni divisa per la larghezza di bin -
densitynormalizza i conteggi in modo che l’area dell’istogramma è 1 -
probabilitynormalizza conta in modo che la somma dei bar heights è 1
binsstr, numero, vettoriale, o un paio di tali valori
Generico bin parametro che può essere il nome di una regola di riferimento,il numero di contenitori, o le interruzioni dei bidoni.Passato a numpy.histogram_bin_edges().
binwidthnumber o pair of numbers
Width of each bin, sostituiscebins ma può essere utilizzato conbinrange.
binrangepair di numeri o una coppia di coppie
Valore più basso e più alto per i bordi bin; può essere utilizzato sia conbins obinwidth. Il valore predefinito è Estremi dati.
discretebool
Se True, predefinito subinwidth=1 e disegna le barre in modo che siano centrate sui loro punti dati corrispondenti. Ciò evita “lacune” che potrebbero apparire quando si utilizzano dati discreti (interi).
cumulativebool
Se True, tracciare i conteggi cumulativi all’aumentare dei bin.
common_binsbool
Se True, usa gli stessi bin quando le variabili semantiche producono multipleplots. Se si utilizza una regola di riferimento per determinare i bin, verrà computedwith il set di dati completo.
common_normbool
Se True e utilizzando una statistica normalizzata, la normalizzazione si applicherà al set di dati completo. Altrimenti, normalizza ogni istogramma in modo indipendente.
multiple{“layer”, “dodge”, “stack”, “fill”}
Approccio alla risoluzione di più elementi quando la mappatura semantica crea sottoinsiemi.Rilevante solo con dati univariati.
elemento {“bars”, “step”, “poly”}
Rappresentazione visiva della statistica dell’istogramma.Rilevante solo con dati univariati.
fillbool
Se True, riempire lo spazio sotto l’istogramma.Rilevante solo con dati univariati.
shrinknumber
Ridimensiona la larghezza di ogni barra rispetto al binwidth di questo fattore.Rilevante solo con dati univariati.
kdebool
Se True, calcola una stima della densità del kernel per lisciare la distribuzione e mostrare sul grafico come (una o più) linee.Rilevante solo con dati univariati.
kde_kwsdict
Parametri che controllano il calcolo di KDE, come in kdeplot().
line_kwsdict
Parametri che controllano la visualizzazione di KDE, passati amatplotlib.axes.Axes.plot().
threshnumber o None
Le celle con una statistica minore o uguale a questo valore saranno trasparenti.Rilevante solo con dati bivariati.
pthreshnumber o None
Likethresh, ma un valore in modo tale che le celle con conteggi aggregati(o altre statistiche, se utilizzate) fino a questa proporzione del totale sarannotrasparente.
pmaxnumber o None
Un valore che imposta quel punto di saturazione per la mappa dei colori a un valore tale che le celle sottostanti costituiscano questa proporzione del conteggio totale (oaltra statistica, quando usata).
cbarbool
Se True, aggiungi una barra dei colori per annotare la mappatura dei colori in una trama bivariata.Nota: attualmente non supporta grafici con una variabilehue.
cbar_axmatplotlib.axes.Axes
Assi preesistenti per la barra dei colori.
cbar_kwsdict
Parametri aggiuntivi passati a matplotlib.figure.Figure.colorbar().
palettestring, list, dict omatplotlib.colors.Colormap
Metodo per la scelta dei colori da utilizzare quando si associa la semanticahue.I valori di stringa vengono passati a color_palette(). List o dict valuesimply categorical mapping, mentre un oggetto colormap implica la mappatura numerica.
hue_ordervector of strings
Specifica l’ordine di elaborazione e stampa per i livelli categoriali delhue semantico.
hue_normtuple omatplotlib.colors.Normalize
O una coppia di valori che impostano l’intervallo di normalizzazione in unità di dati o un oggetto che verrà mappato da unità di dati in un intervallo. Usageimplica la mappatura numerica.
colorematplotlib color
Specifica colore singolo per quando la mappatura tonalità non viene utilizzata. Altrimenti, theplot proverà ad agganciarsi al ciclo di proprietà matplotlib.
log_scalebool o number, o pair of bools or numbers
Imposta una scala di log sull’asse dati (o assi, con dati bivariati) con la base data (default 10), e valuta KDE nello spazio log.
legendbool
Se False, sopprimere la legenda per le variabili semantiche.
axmatplotlib.axes.Axes
Assi preesistenti per la trama. In caso contrario, chiamare matplotlib.pyplot.gca()internamente.
kwargs
Altri argomenti delle parole chiave vengono passati a una delle seguenti funzioni matplotlib:
-
matplotlib.axes.Axes.bar()(univariate, element=”bars”) -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
Stampa distribuzioni univariate o bivariate usando la stima della densità del kernel.
rugplot
Tracciare un segno di spunta ad ogni valore di osservazione lungo gli assi x e / o y.
ecdfplot
Tracciare le funzioni di distribuzione cumulativa empirica.
jointplot
Disegna un grafico bivariato con distribuzioni marginali univariate.
Note
La scelta di bin per calcolare e tracciare un istogramma può esercitare un’influenza sostanziale sulle intuizioni che si è in grado di trarre dalla visualizzazione. Se i bidoni sono troppo grandi, possono cancellare caratteristiche importanti.D’altra parte, i bidoni troppo piccoli possono essere dominati da randomvariability, oscurando la forma della vera distribuzione sottostante. La dimensione predefinita del bin viene determinata utilizzando una regola di riferimento che dipende dalla dimensione del campione e dalla varianza. Questo funziona bene in molti casi, (cioè con dati “ben educati”) ma fallisce in altri. È sempre un bene da provarediverse dimensioni del bidone per essere sicuri che non ti manca qualcosa di importante.Questa funzione consente di specificare i bin in diversi modi, ad esempio impostando il numero totale di bin da utilizzare, la larghezza di ciascun bin o le posizioni specifiche in cui i bin dovrebbero rompersi.
Esempi
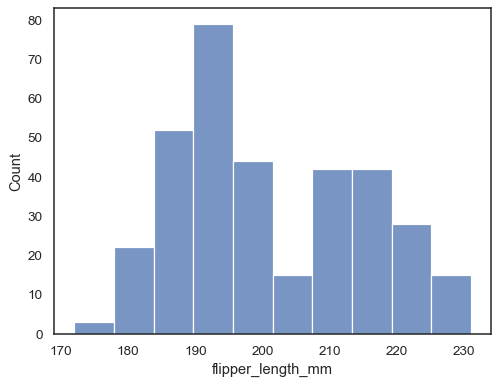
Assegnare una variabile ax per tracciare una distribuzione univariata lungo l’asse x:
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
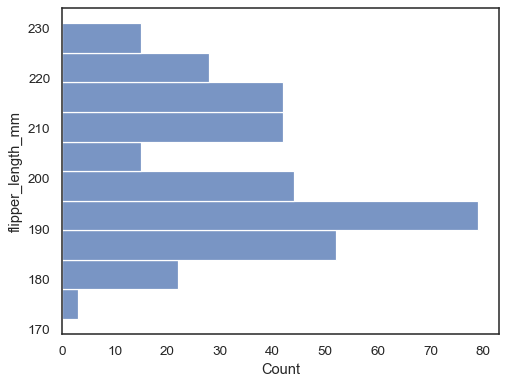
Capovolgere il grafico assegnando la variabile dati all’asse y:
sns.histplot(data=penguins, y="flipper_length_mm")
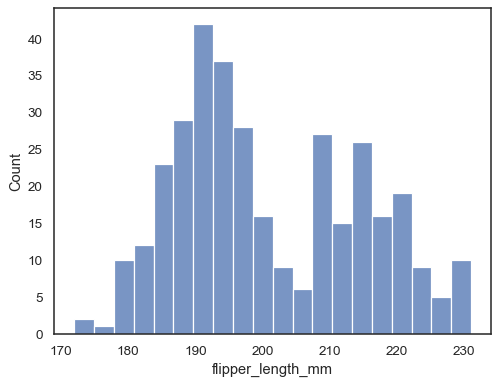
Controlla quanto bene l’istogramma rappresenta i dati specificando una larghezza diversa del bin:
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
È anche possibile definire il numero totale di contenitori da utilizzare:
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
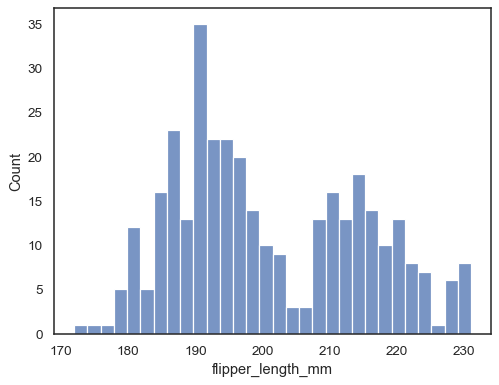
Aggiunge una stima della densità del kernel per lisciare l’istogramma, fornendo informazioni complementari sulla forma della distribuzione:
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
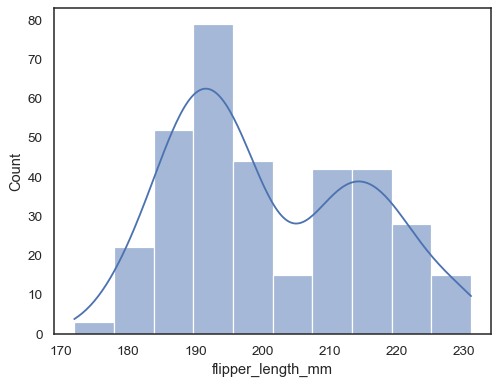
Se non viene assegnato né x né y, il set di dati viene trattato aswide-form e viene disegnato un istogramma per ogni colonna numerica:
sns.histplot(data=penguins)
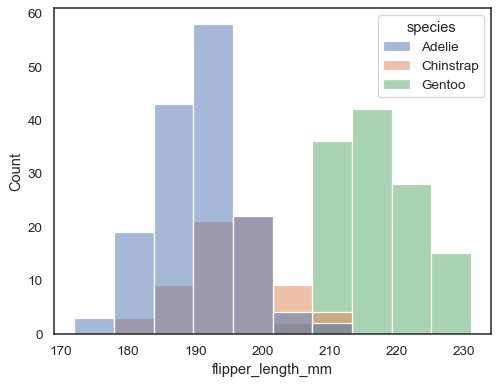
È altrimenti possibile disegnare più istogrammi da un set di dati a forma lunga withhue mapping:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
L’approccio predefinito per tracciare più distribuzioni è quello di”sovrapporle”, ma puoi anche” impilarle”:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
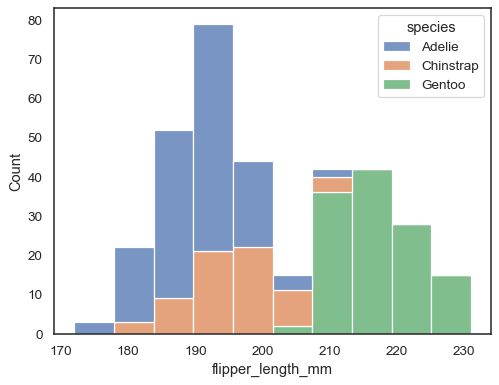
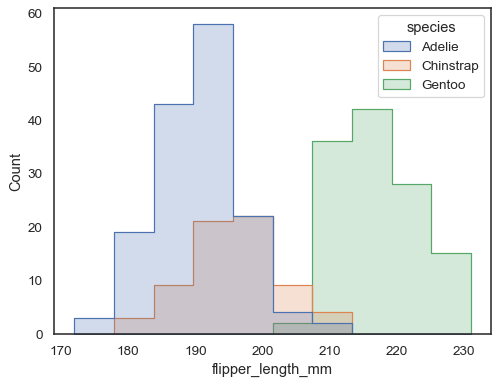
Le barre sovrapposte possono essere difficili da risolvere visivamente. Un approccio diverso sarebbe quello di disegnare una funzione step:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
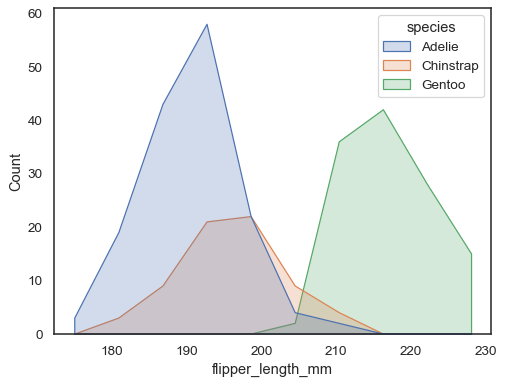
Puoi allontanarti ancora di più dalle barre disegnando un poligono con i vertici al centro di ogni bin. Questo può rendere più facile vedere la forma della distribuzione, ma usare con cautela: sarà meno ovvio per il tuo pubblico che stanno guardando un istogramma:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
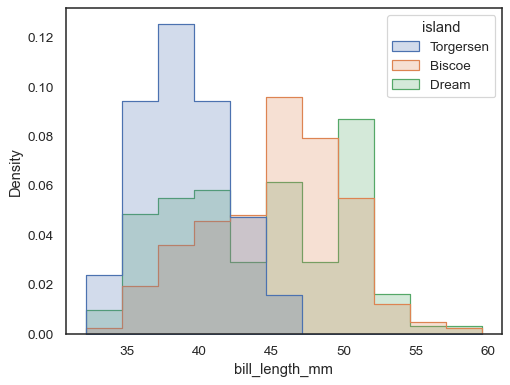
Per confrontare la distribuzione di sottoinsiemi che differiscono sostanzialmente insize, utilizzare indepdendent density normalization:
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
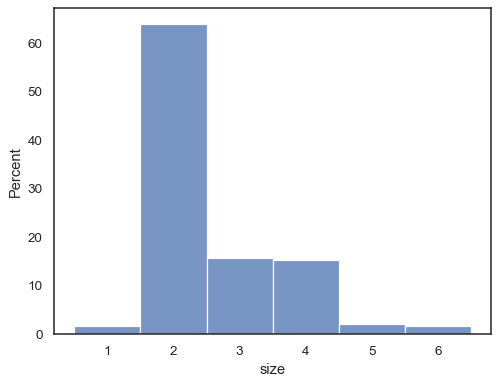
È anche possibile normalizzare in modo che l’altezza di ogni barra mostri aprobability, che ha più senso per le variabili discrete:
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
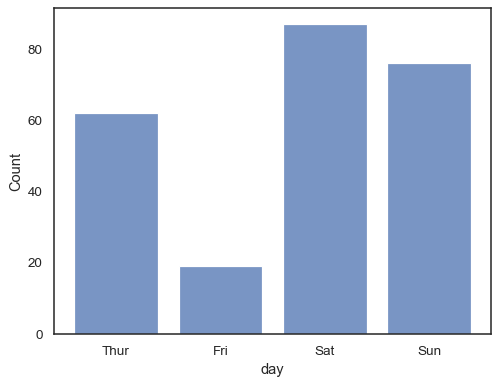
Puoi anche disegnare un istogramma su variabili categoriali (sebbene questa sia una caratteristica sperimentale):
sns.histplot(data=tips, x="day", shrink=.8)
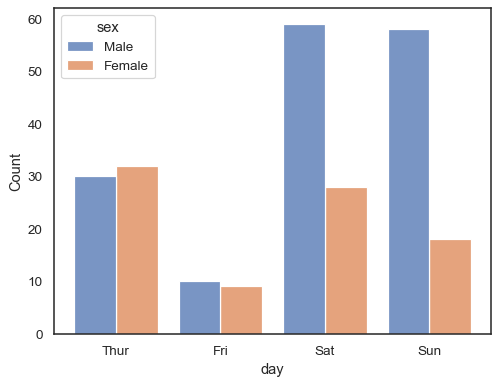
Quando si utilizza unhue semantico con dati discreti, può avere senso”schivare” i livelli:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
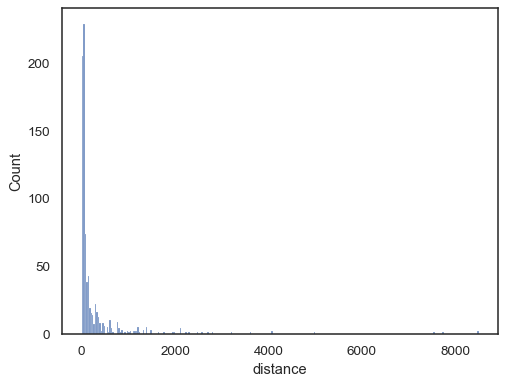
I dati del mondo reale sono spesso distorti. Per distribuzioni fortemente distorte, è meglio definire i bin nello spazio di registro. Confrontare:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
To the log-scale version:
sns.histplot(data=planets, x="distance", log_scale=True)
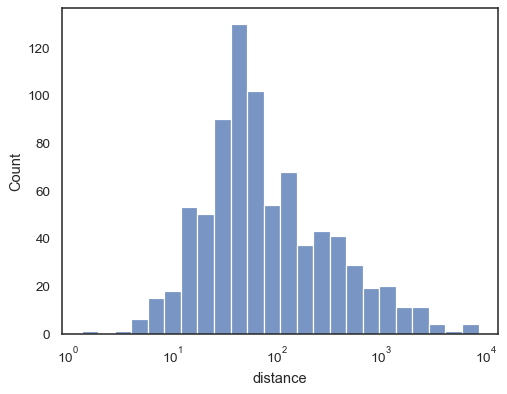
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
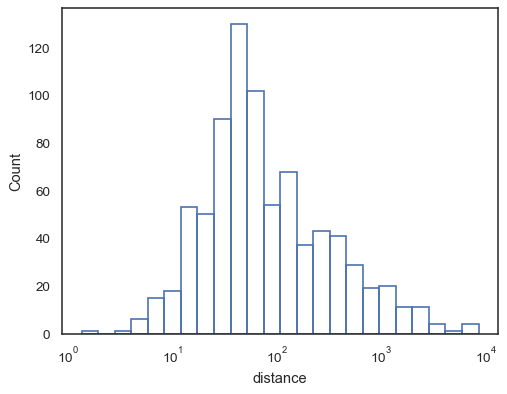
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
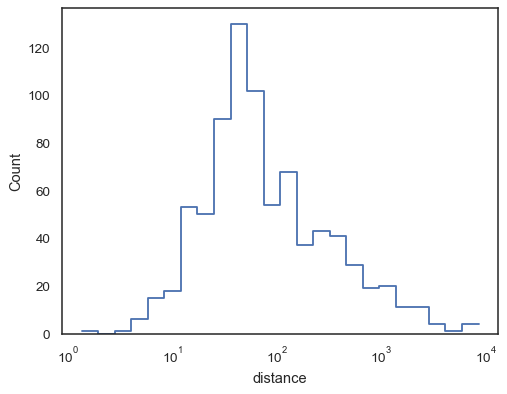
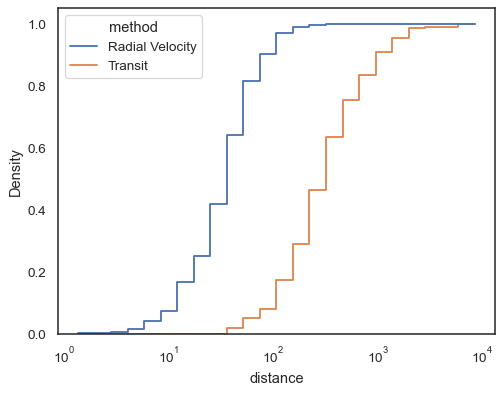
Funzioni passo, esepcially quando vacanti, lo rendono facile da comparecumulative istogrammi:
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
Quando vengono assegnati entrambi x e y, viene calcolato un istogramma bivariato e mostrato come heatmap:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
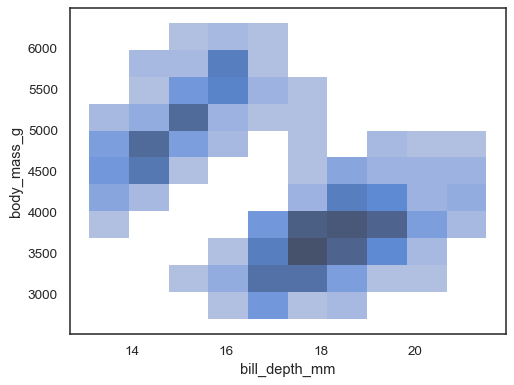
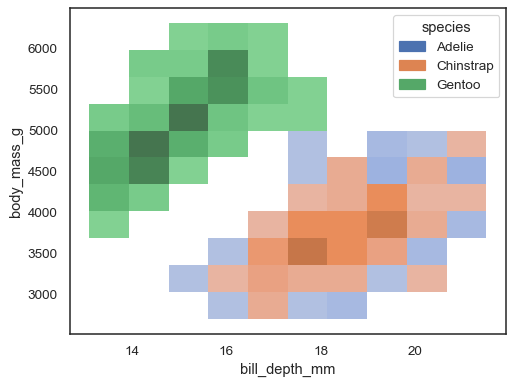
È possibile assegnare anche una variabilehue, anche se questa non funzionerà bene se i dati dei diversi livelli hanno una sovrapposizione sostanziale:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
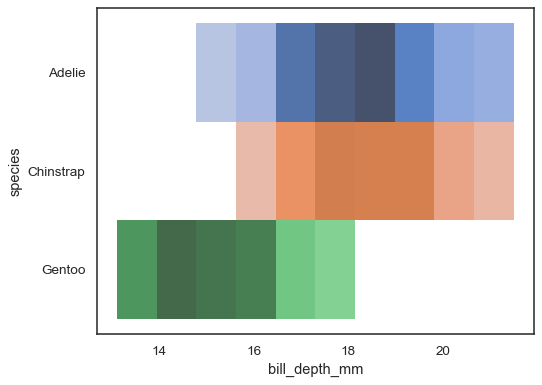
Più mappe a colori possono avere senso quando una delle variabili èdiscrete:
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
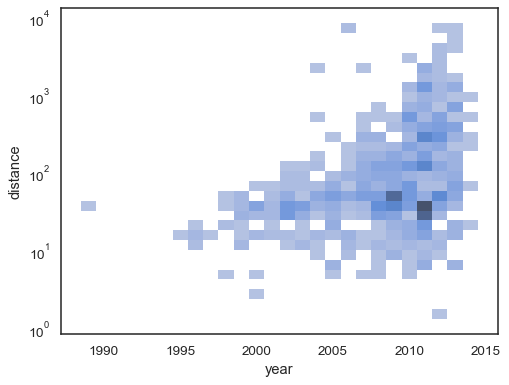
bivariata istogramma accetta tutte le stesse opzioni per computationas sua univariata controparte, utilizzando le tuple per parametrizzare x ey indipendente
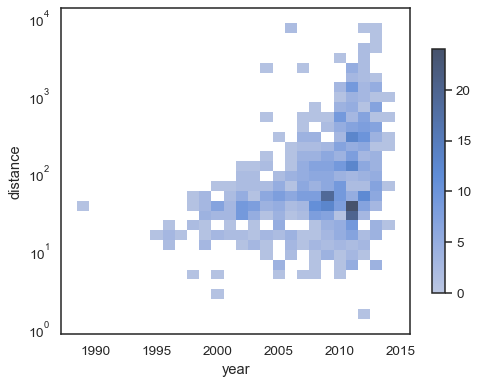
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
Il comportamento predefinito rende trasparenti le celle senza osservazioni,sebbene ciò possa essere disabilitato:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
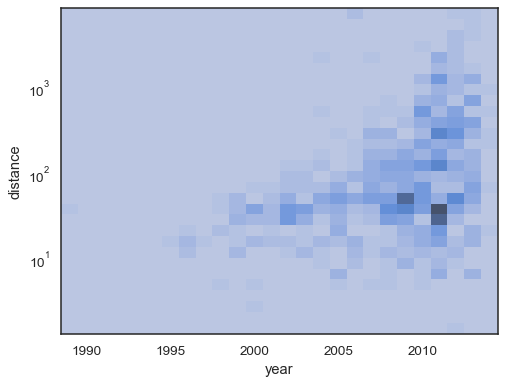
È anche possibile impostare la soglia e il punto di saturazione della mappa colori interms della proporzione dei conteggi cumulativi:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
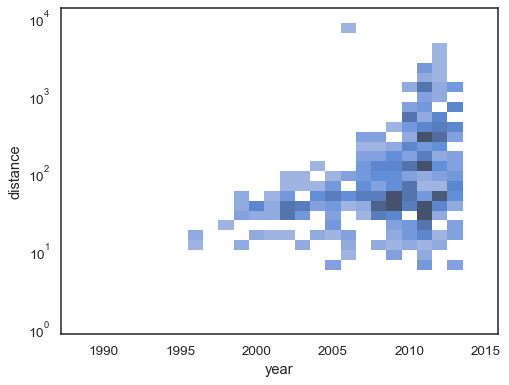
Per annotare la mappa dei colori, aggiungere una barra dei colori:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)