マルコフ決定プロセスによる強化学習に取り組む
この記事は、Data Science Blogathonの一部として公開されました。
はじめに
強化学習(RL)は、学習者が独自の行動とその行動に対する報酬を使用して対話型環境で行動することを学習する学習方法論です。 学習者は、しばしばエージェントと呼ばれ、どの行動がそれらを悪用して探索することによって最大の報酬を与えるかを発見する。重要な質問は、rlが教師あり学習と教師なし学習とどのように異なるかということです。違いは、相互作用の観点にあります。
違いは、相互作用の観点にあります。 教師あり学習は、ラベル付きの例のトレーニングデータセットを使用して、報酬を最大化するために実行する必要があるアクションをユーザー/エージ 一方、RLは、エージェントがその行動を選択するために取得する報酬(正と負)を直接利用することを可能にします。 教師なし学習は、ラベルのないデータのコレクションに隠された構造を見つけることに関するものであるため、教師なし学習とは異なります。
マルコフ決定プロセス(MDP)を介した強化学習定式化
強化学習問題の基本的な要素は次のとおりです。
- 環境:エージェントが相互作用する外の世界
- 状態:エージェ ポリシーは、特定の状態でアクションを選択するために使用されます
- 値:エージェントが特定の状態でアクションを取ることによって受け取る将来の報 次の図は、MDPでのエージェントと環境の相互作用を示しています:
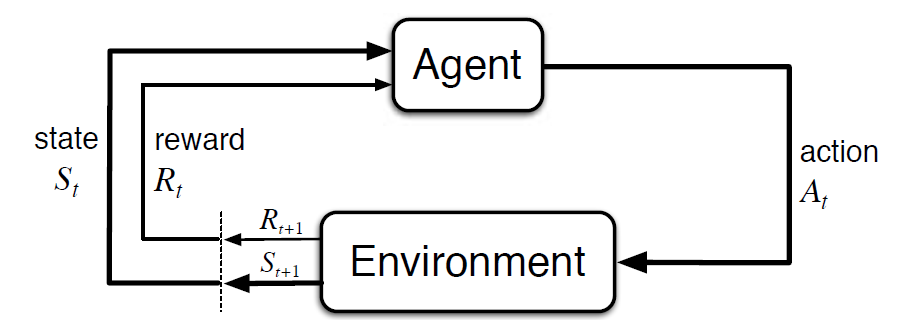
より具体的には、エージェントと環境は、各離散時間ステップ、t=0、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、19、19、19、19、19、19、19、19、19、19、19、19、19、19、19、19、19、19、19、19、3…At 各タイムステップでは、エージェントは環境状態Stに関する情報を取得します。 次の瞬間に、エージェントはまた、数値報酬信号Rt+1を受信する。 したがって、これはs0、A0、R1、S1、A1、R2…
確率変数RtとStは明確に定義された離散確率分布を持っているようなシーケンスを生じさせます。 これらの確率分布は、マルコフ特性のおかげで、先行する状態と行動にのみ依存します。 S、A、およびRを状態、アクション、および報酬のセットとします。 次に、St、RtおよびAtの値が前の状態sを持つ値s’、rおよびaを取る確率は、
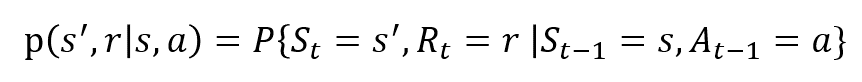
関数pはプロセスのダイナミクスを制御します。
例を使用してこれを理解しましょう
ここで、rlを使用して加熱プロセスの制御戦略を実装できる簡単な例について説明しましょう。アイデアは、指定された温度制限内で部屋の温度を制御することです。
部屋の中の温度は外気温、発生する内部熱、等のような外的な要因によって影響を及ぼされます。
エージェントは、この場合、環境との相互作用によって室内の温度を制御し、室内の温度が指定された範囲内にあることを確認するために必要な熱量を決定しなければならない加熱コイルである。 この場合の報酬は、基本的に最適な温度制限から逸脱するために支払われるコストです。
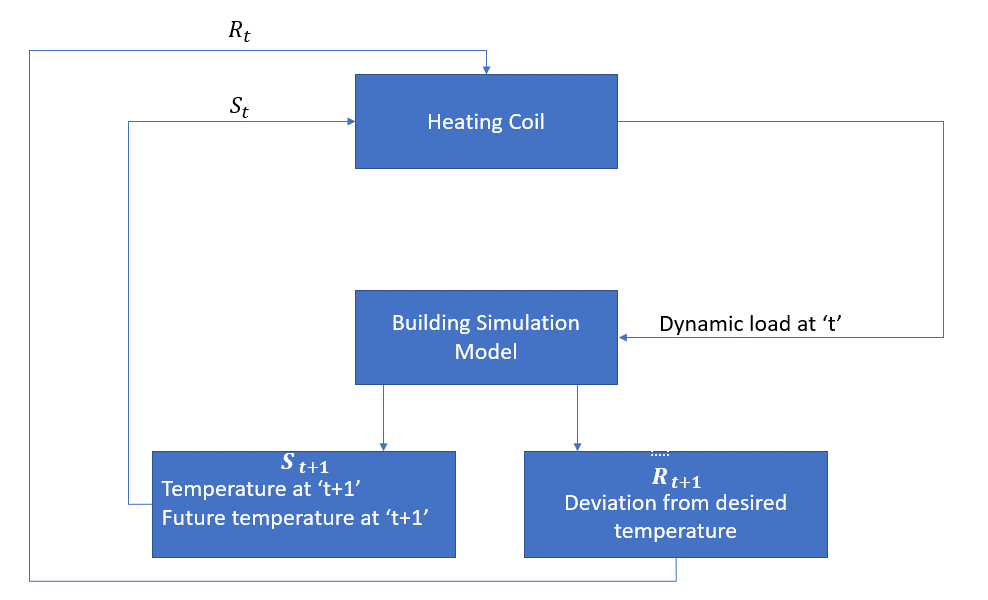
エージェントのアクションは動的負荷です。 この動的負荷は基本的に動的負荷に基づいて温度を計算する熱伝達モデルである部屋のシミュレーターにそれから与えられる。 したがって、この場合、環境はシミュレーションモデルです。 状態変数Stには、現在の報酬と将来の報酬が含まれます。
次のブロック図は、MDPが室内の温度を制御するためにどのように使用できるかを説明しています。
この方法の制限
強化学習は状態から学習します。 状態は政策立案のための入力です。 したがって、状態入力を正しく指定する必要があります。 また、私たちが見てきたように、複数の変数があり、次元は巨大です。 したがって、実際の物理システムに使用するのは難しいでしょう!
さらに読む
RLについての詳細を知るには、次の資料が役立つかもしれません。
- 強化学習:Richardによる紹介。S.サットンとアンドリュー。G・バルトー: http://incompleteideas.net/book/the-book-2nd.html
- Youtubeで利用可能なデビッド*シルバーによるビデオ講義
- https://gym.openai.com/さらに探査のためのツールキットです
また、私たちfe5a49d07f”>