回帰木
すべての回帰手法には、単一の出力(応答)変数と1つ以上の入力(予測子)変数が含まれています。 出力変数は数値です。 一般的な回帰木構築方法論では、入力変数を連続変数とカテゴリ変数の混合物にすることができます。 デシジョンツリーは、ツリー内の各デシジョンツリーノードに入力変数の値に関するテストが含まれている場合に生成されます。 ツリーの終端ノードには、予測された出力変数値が含まれています。
回帰木は、分類方法に使用されるのではなく、実数値関数を近似するように設計された決定木の変種と考えることができます。
方法論
回帰ツリーは、データをパーティションまたは分岐に分割し、メソッドが各分岐を上に移動するにつれて各パーティションをより小さなグループに分割し続ける反復プロセスであるbinary recursive partitioningと呼ばれるプロセスを介して構築されます。
最初に、トレーニングセット内のすべてのレコード(ツリーの構造を決定するために使用される事前分類されたレコード)は、同じパーティションにグループ化 次に、アルゴリズムは、すべてのフィールドで可能なすべてのバイナリ分割を使用して、最初の二つのパーティションまたは分岐にデータの割 このアルゴリズムは、2つの別々の分割の平均からの二乗偏差の合計を最小化する分割を選択します。 この分割ルールは、新しいブランチのそれぞれに適用されます。 このプロセスは、各ノードがユーザーが指定した最小ノードサイズに達し、端末ノードになるまで続行されます。 (ノード内の平均からの偏差の二乗の合計がゼロの場合、そのノードは最小サイズに達していなくても端末ノードとみなされます。)
木の剪定
木は訓練セットから成長しているので、完全に発達した木は一般的にオーバーフィッティングに苦しんでいます(すなわち、より大きな母集団の特徴ではない可能性が高い訓練セットのランダムな要素を説明しています)。 このオーバーフィッティングにより、実際のデータのパフォーマンスが低下します。 したがって、検証セットを使用してツリーを剪定する必要があります。 XLMinerは、ツリーの成長中の各ステップでコスト複雑度係数を計算し、剪定されたツリー内の決定ノードの数を決定します。 コスト複雑度係数は、ツリーのサイズに適用される乗法係数です(端末ノードの数によって測定)。
ツリーは、次の合計を最小限に抑えるために剪定されます。1)検証データの出力変数variance、一度に一つの端子ノードを取得し、2)コスト複雑度係数と端子ノード数の積。 コスト複雑度係数がゼロとして指定されている場合、剪定とは、端末ノードの合計分散に関して検証データで最も効果的なツリーを見つけることです。 コスト複雑度係数の値が大きいほど、ツリーは小さくなります。 剪定は、最後に成長したノードが除去の対象となる最初のノードであることを意味し、最後のインファーストアウトベースで実行されます。
アンサンブルメソッド
XLMiner V2015は、回帰木で使用するための三つの強力なアンサンブルメソッドを提供しています。 回帰木アルゴリズムを使用して、新しいデータの良好な予測をもたらす1つのモデルを見つけることができます。 現在の予測子の統計行列と混乱行列を表示して、モデルがデータに適しているかどうかを確認できますが、見つかるのを待っているより良い予測子が 答えは、より良い予測変数が存在するかどうかわからないということです。 しかし、アンサンブル法では、多重の弱い回帰木モデルを組み合わせることができ、これを組み合わせると、新しい正確で強力な回帰木モデルが形成されます。 これらの方法は、複数の多様な回帰モデルを作成し、元のデータセットの異なるサンプルを取得し、それらの出力を結合することによって機能します。 (出力は、分類のための多数決および回帰のための平均化など、いくつかの手法によって組み合わせることができる)このモデルの組み合わせは、効果的に XLMinerで提供される3つのタイプのアンサンブル手法(bagging、boosting、random trees)は、1)各予測子または弱モデルの学習セットの選択、2)弱モデルの生成方法の3つの項目で異; そして3)出力がどのように結合されるか。 すべての3つの方法で、各弱いモデルは、データセットの一部に堪能になるために、トレーニングセット全体で訓練されます。
Bagging(bootstrap aggregating)は、これまでに書かれた最初のアンサンブルアルゴリズムの一つでした。 これは単純なアルゴリズムですが、非常に効果的です。 Baggingは、置換によるランダムサンプリング(ブートストラップサンプリング)を使用していくつかのトレーニングセットを生成し、各データセットに回帰木アルゴ バギングの最大の利点は、アルゴリズムを並列化できる相対的な容易さであり、非常に大きなデータセットのより良い選択になります。
Boostingは、以前のモデルで不正確な予測値を受け取ったレコードに集中するためにモデルを連続的に訓練することにより、強力なモデルを構築します。 完了すると、すべての予測子が加重多数決によって結合されます。 XLMinerは、AdaBoostアルゴリズム(今日使用されている最も一般的なアンサンブルアルゴリズムの一つ)によって実装されているようにブーストの三つのバリエー: M1(Freund)、M1(Breiman)、およびSAMME(マルチクラス指数関数を使用した段階的加法モデリング)。
M1はまず、各レコードまたは観測値に重み(wb(i))を割り当てます。 この重みはもともと1/nに設定されており、アルゴリズムの反復ごとに更新されます。 この最初のトレーニングセット(Tb)を使用して元の回帰ツリーが作成され、エラーは次のように計算されます。
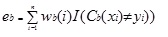
ここで、i()関数はtrueの場合は1を返し、そうでない場合は0を返します。
b番目の反復における回帰木の誤差は、定数を計算するために使用されますか?b. この定数は、重み(wb(i))を更新するために使用されます。 AdaBoostで。M1(Freund)では、定数は次のように計算されます。
ab=ln((1-eb)/eb)
AdaBoostで。M1(Breiman)、定数は次のように計算されます
ab=1/2ln((1-eb)/eb)
SAMMEでは、定数は次のように計算されます
ab=1/2ln((1-eb)/eb+ln(k-1)kはクラスの数です
カテゴリの数が2に等しい場合、SAMMEはAdaBoost Breimanと同じように動作します。3つの実装(Freund、Breiman、またはSAMME)のいずれかでは、(b+1)番目の反復の新しい重みは次のようになります。

その後、重みはすべて1の合計に再調整されます。 その結果、不正確な予測値が割り当てられた観測値に割り当てられた重みが増加し、正確な予測値が割り当てられた観測値に割り当てられた重み この調整により、次の回帰モデルは、不正確な予測が割り当てられたレコードに重点を置くようになります。 (これ? 定数は最終的な計算でも使用され、誤差が最も小さい回帰モデルにより多くの影響を与えます。)このプロセスは、b=弱い学習者の数まで繰り返されます。 次に、アルゴリズムはすべての弱い学習器の加重平均を計算し、その値をレコードに割り当てます。 Boostingは一般的にbaggingよりも優れたモデルを生成しますが、並列化できないため、欠点があります。 その結果、弱い学習器の数が多い場合、ブーストは適切ではありません。
ランダムツリーメソッド(ランダム森林)は、袋詰めのバリエーションです。 この方法は、ランダムに選択された特徴の固定数(分類の場合はsqrt、予測の場合は特徴数/3)を使用して多重弱回帰木を学習させ、弱い学習器の平均値を取り、その値を強い予測子に代入することによって機能します。 通常、生成される弱いツリーの数は、トレーニングセットのサイズと難易度に応じて数百から数千の範囲になる可能性があります。 ランダム木はバギングの変種であるため、並列化可能です。 ただし、tandomツリーは各反復で限られた量のフィーチャを選択するため、ランダムツリーのパフォーマンスは袋詰めよりも高速です。
回帰木アンサンブルメソッドは非常に強力なメソッドであり、通常は単一のツリーよりもパフォーマンスが向上します。 XLMiner V2015でのこの機能の追加により、より正確な予測モデルが提供されるため、単一ツリー法で検討する必要があります。