Reading Code Right, With Some Help From The Lexer
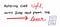
Software is all about logic. 프로그래밍은 수학 및 미친 방정식에 무거운 분야 인의 명성을 얻고있다. 그리고 컴퓨터 과학은 이러한 오해의 핵심이있는 것 같습니다.물론,몇 가지 수학과 몇 가지 공식이 있습니다-그러나 우리 중 누구도 실제로 기계가 어떻게 작동하는지 이해하기 위해 미적분학 박사 학위를 가질 필요가 없습니다! 사실,코드를 작성하는 과정에서 우리가 배우는 많은 규칙과 패러다임은 복잡한 컴퓨터 과학 개념에 적용되는 규칙과 패러다임입니다. 그리고 때때로,그 아이디어는 실제로 컴퓨터 과학에서 유래,우리는 이제까지 그것을 몰랐다.우리가 사용하는 프로그래밍 언어에 관계없이,우리 대부분이 코드를 작성할 때,우리는 고유 한 것을 클래스,객체 또는 메소드에 캡슐화하여 코드의 다른 부분과 관련된 부분을 의도적으로 분리하는 것을 목표로합니다. 즉,우리는 하나의 클래스,객체 또는 메소드가 단 하나의 것에 대해서만 관심을 갖고 책임을 지도록 코드를 나누는 것이 일반적으로 좋은 일이라는 것을 알고 있습니다. 우리가 이렇게 하지 않은 경우,것 들 슈퍼 지저분 하 고 웹의 혼란에 얽혀 얻을 수 있습니다. 때때로 이것은 여전히 심지어 우려의 분리와 함께 발생합니다.밝혀진 바와 같이,우리 컴퓨터의 내부 동작조차도 매우 유사한 디자인 패러다임을 따릅니다. 예를 들어 컴파일러는 서로 다른 부분을 가지고 있으며 각 부분은 컴파일 프로세스의 특정 부분을 처리 할 책임이 있습니다. 우리는 우리가 구문 분석 트리를 만드는 책임이 파서에 대해 알게되었을 때,이 지난 주 조금 발생했습니다. 그러나 파서는 아마도 모든 것을 맡을 수 없습니다.파서는 친구의 도움이 필요하며 마침내 우리가 그들이 누구인지 배울 때입니다!우리가 최근에 구문 분석에 대해 배웠을 때,우리는 문법,구문,그리고 컴파일러가 프로그래밍 언어 내에서 그러한 것들에 어떻게 반응하고 반응하는지에 대해 발가락을 담갔다. 그러나 우리는 컴파일러가 정확히 무엇인지 강조하지 않았습니다! 우리가 컴파일 프로세스의 내부 동작에 들어갈 때,우리는 컴파일러 디자인에 대해 많은 것을 배울 것입니다,그래서 우리가 정확히 우리가 여기서 무슨 말을하는지 이해하는 것이 중요합니다.컴파일러는 무서운 것처럼 들릴 수 있지만,그들의 작업은 실제로 이해하기에는 너무 복잡하지 않습니다—특히 우리가 컴파일러의 다른 부분을 한 입 크기의 부분으로 나눌 때.그러나 먼저 가능한 가장 간단한 정의부터 시작하겠습니다. 컴파일러는 코드(또는 모든 프로그래밍 언어로 된 코드)를 읽고 다른 언어로 변환하는 프로그램입니다.2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년일반적으로 컴파일러는 실제로 높은 수준의 언어에서 낮은 수준의 언어로 코드를 번역 할 것입니다. 컴파일러가 코드를 변환하는 하위 수준 언어를 어셈블리 코드,기계 코드 또는 개체 코드라고 합니다. 그것은 대부분의 프로그래머가 정말 처리 또는 기계 코드를 작성하지 않는 것을 언급 할 가치가있다;오히려,우리는 우리의 프로그램을 가지고 우리의 컴퓨터가 실행 프로그램으로 실행됩니다 무엇 기계 코드로 번역하는 컴파일러에 따라 달라집니다.우리는 컴파일러를 우리,프로그래머 및 컴퓨터 사이의 중개인으로 생각할 수 있으며,이는 낮은 수준의 언어로만 실행 가능한 프로그램을 실행할 수 있습니다.컴파일러는 우리 기계가 이해할 수 있고 실행 가능한 방식으로 우리가 원하는 것을 번역하는 작업을 수행합니다.컴파일러가 없다면 우리는 기계 코드를 작성하여 컴퓨터와 통신해야 할 것입니다.이 코드는 믿을 수 없을 정도로 읽을 수없고 해독하기 어렵습니다. 기계 코드는 종종 인간의 눈에 0 과 1 의 무리처럼 보일 수 있습니다. -읽기,쓰기 및 디버깅이 매우 어렵습니다. 그것은 매우 쉽게 우리가 기계 코드에 대해 생각하지 훨씬 더 우아하고 명확하고 읽기 쉬운 언어를 사용하여 프로그램을 작성하기 위해 만든 때문에 컴파일러는 프로그래머로 우리를 위해 기계 코드를 멀리 추상화.우리는 앞으로 몇 주 동안 신비한 컴파일러에 대해 점점 더 많은 것을 풀 것이며,그 과정에서 수수께끼가 줄어들 것입니다. 하지만 지금은,의 손에 질문을 다시하자:컴파일러의 가장 간단한 부분은 무엇인가?각 컴파일러는 설계 방법에 관계없이 별개의 단계를 가지고 있습니다. 이 단계는 컴파일러의 고유 한 부분을 구별하는 방법입니다.2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년: 우리는 최근에 파서와 구문 분석 트리에 대해 알게되었을 때 이미 컴파일 모험의 단계 중 하나를 발견했습니다. 우리는 구문 분석이 어떤 입력을 취하고 구문 분석 트리를 만드는 과정이라는 것을 알고 있습니다.이 구문 분석은 구문 분석 행위라고도합니다. 결과적으로 구문 분석 작업은 구문 분석이라는 컴파일 프로세스의 단계에 따라 다릅니다.그러나 파서는 허공에서 구문 분석 트리를 만드는 것이 아닙니다. 그것은 약간의 도움이 있습니다! 파서에는 일부 토큰(터미널이라고도 함)이 주어지며 해당 토큰에서 구문 분석 트리를 작성한다는 것을 상기 할 것입니다. 그러나 그 토큰은 어디에서 얻습니까? 파서 운,그것은 진공 상태에서 작동 할 필요가 없습니다;대신,그것은 약간의 도움이 있습니다.여기에 표시된 이미지는 셰익스피어의 문장에 대한이 과정을 보여줍니다. 우리는 우리의 스캐너가 우리의 문장에서 각 문자에 대한 라인과 열을 표시하는 것을 볼 수 있습니다. 우리는 행과 열 표현을 행렬 또는 문자 배열로 생각할 수 있습니다.우리 파일에는 단 하나의 줄만 있기 때문에 모든 것이 줄에 있습니다. 그러나 문장을 통해 작업 할 때 각 문자의 열이 증가합니다. 그것은 또한 언급 할 가치가있는 것,이후 스캐너 읽spacesnewlineseof고,모든 구두점으로 문자,그에 나타나 우리의 문자,테이블도!2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년소스 텍스트를 스캔하고 표시되면,우리의 컴파일러는 단어로 이러한 문자를 설정 할 준비가되어 있습니다. 스캐너는 파일의 위치뿐만 아니라 주변의 다른 문자와 관련하여 어디에 살고 있는지 알고 있기 때문에 문자를 스캔하여 필요에 따라 개별 문자열로 나눌 수 있습니다.이 예제에서는 스캐너에서 문자를 확인한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 해당 문자를 검사한 다음 스캐너가 공백을 발견하기 전에 가능한 가장 간단한 문자 조합인 자체 단어로 나눕니다.이 경우 다음 단어를 찾을 수 있습니다. 그러나 이 시나리오에서는 구두점인그러나,이 모든 작업에도 불구하고,어휘 분석 단계의이 시점에서,우리의 스캐너는이 단어에 대해 아무것도 몰라. 물론,그것은 다른 모양과 크기의 단어로 텍스트를 분할하지만,지금까지 그 단어가 무엇인지 스캐너는 아무 생각이 없습니다! 단어는 리터럴 문자열 일 수도 있고 구두점 일 수도 있고 완전히 다른 것일 수도 있습니다!스캐너는 단어 자체 또는 단어의”유형”에 대해 아무것도 모릅니다. 그것은 단지 단어가 텍스트 자체 내에서 끝나고 시작되는 곳을 알고 있습니다.이것은 어휘 분석의 두 번째 단계 인 평가를 위해 우리를 설정합니다. 우리는 우리의 텍스트를 스캔하고 개별 어휘 단위로 소스 코드를 분해 한 후,우리는 스캐너가 우리에게 반환 된 단어를 평가하고 우리가 다루고있는 단어의 유형을 파악해야합니다-특히,우리는 우리가 컴파일하려는 언어에서 특별한 것을 의미하는 중요한 단어를 찾아야합니다.우리는 우리의 소스 텍스트를 스캔 완료하고 우리의 어휘를 식별 한 후,우리는 우리의 어휘”단어”로 뭔가를해야합니다. 이것은 어휘 분석의 평가 단계이며,이는 종종 컴플라이어 디자인에서 입력을 렉싱 또는 토큰 화하는 프로세스라고합니다.2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년우리가 스캔 한 코드를 평가할 때,우리가 실제로하고있는 것은 스캐너가 생성 한 각 어휘에 대해 자세히 살펴 보는 것입니다. 우리의 컴파일러는 각 어휘 단어를보고 그것이 어떤 종류의 단어인지 결정해야합니다. 텍스트의 각”단어”가 어떤 종류의 어휘인지 결정하는 과정은 컴파일러가 각 개별 어휘를 토큰으로 전환하여 입력 문자열을 토큰화하는 방법입니다.우리는 구문 분석 나무에 대해 배울 때 토큰을 처음 접했습니다. 토큰은 각 프로그래밍 언어의 핵심에 있는 특수 기호입니다. 토큰은 모두 컴파일러가 식의 다른 부분과 다양한 요소가 서로 어떻게 관련되어 있는지 이해하는 데 도움이됩니다. 구문 분석 단계의 중심 인 파서는 어딘가에서 토큰을 수신 한 다음 해당 토큰을 구문 분석 트리로 변환합니다.2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년이 문제를 해결하는 데 도움이되는 몇 가지 방법이 있습니다. 우리는 마침내”어딘가에”를 알아 냈습니다! 밝혀진 바와 같이,파서로 전송되는 토큰은 토크 나이저에 의해 어휘 분석 단계에서 생성됩니다(렉서라고도 함).2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년 12 월 1 일,2018 년따라서 토큰은 정확히 어떻게 생겼습니까? 토큰은 매우 간단하며 일반적으로 토큰 이름과 일부 값(선택 사항)으로 구성된 쌍으로 표시됩니다.예를 들어 셰익스피어 문자열을 토큰 화하면 대부분 문자열 리터럴과 구분 기호가 될 토큰으로 끝날 것입니다. 이 경우 토큰은 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성된다. 이 경우 토큰은 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성 된 토큰에 의해 생성된다.우리는 이러한 각 토큰이 어휘를 전혀 수정하지 않는다는 것을 알게 될 것입니다—그들은 단순히 추가 정보를 추가하고 있습니다. 특히 추가 된 세부 사항은 우리가 다루고있는 토큰의 범주(어떤 유형의”단어”)를 알려줍니다.이제 우리는 셰익스피어의 문장을 토큰화 했으므로 소스 파일의 토큰 유형에 그렇게 많은 다양성이 없다는 것을 알 수 있습니다. 우리의 문장은 문자열과 문장 부호를 가지고 있었다-하지만 토큰 빙산의 일각에 불과! 어휘로 분류 될 수있는”단어”의 다른 유형이 많이 있습니다.우리는 우리의 소스 코드 내에서 발견 된 토큰의 일반적인 형태.우리는 우리의 소스 코드 내에서 발견 된 토큰의 일반적인 형태.우리는 우리의 소스 코드 내에서 발견 된 토큰의 일반적인 형태.우리는 우리의 소스 코드 내에서 발견 된 토큰의 일반적인 형태.우리는 우리의 소스 코드 내에서 발견 된 토큰의 일반적인 형태.우리는 우리의 소스 코드 내에서 발견 된 토큰의 일반적인 형태.우리는 우리의 소스 코드 내에서 발견 된 토큰의 일반적인 형태.우리는 우리의 소스 코드 내에서 발견 된 토큰의 일반적인 형태.여기에 표시된 표는 컴파일러가 거의 모든 프로그래밍 언어로 소스 파일을 읽을 때 볼 수있는 가장 일반적인 토큰 중 일부를 보여줍니다. 우리는 문자열,숫자 또는 논리/부울 값뿐만 아니라 중괄호(괄호)와 괄호(괄호)를 포함한 모든 유형의 구두점 일 수 있습니다.
However, there are also keywords, which are terms that are reserved in the language (such as ifvarwhilereturn), as well as operators, which operate on arguments and return some value ( +-x/keywordvaridentifiertoSleep는 방법으로,우리는 우리가 이름의 변수를 참조하는 값이 올 수 있습니다. 이 토큰은 토큰이며,그 다음에 문자열 리터럴이 이어집니다. 한 줄의 끝을 나타내고 공백을 구분하는 구분 기호로 끝납니다.토큰 화 프로세스에 대해 주목해야 할 중요한 점은 공백(공백,줄 바꿈,탭,줄 끝 등)을 토큰 화하지 않는다는 것입니다.),파서에 전달하지 않습니다. 토큰만 파서에 주어지고 구문 분석 트리에서 끝날 것이라는 점을 기억하십시오.또한 다른 언어가 공백을 구성하는 다른 문자를 가질 것임을 언급 할 가치가 있습니다. 예를 들어,일부 상황에서 파이썬 프로그래밍 언어는 함수의 범위가 어떻게 변하는 지 나타 내기 위해 탭과 공백을 포함하여 들여 쓰기를 사용합니다. 따라서 파이썬 컴파일러의 토크 나이저는 특정 상황에서 실제로 파서에 전달 될 필요가 있기 때문에 실제로 단어로 토큰 화 될 필요가 있다는 사실을 인식해야합니다!2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년 12 월 1 일,2015 년토크나이저의 이 측면은 렉서/토크나이저가 스캐너와 어떻게 다른지 대조하는 좋은 방법입니다. 스캐너는 무지하고 텍스트를 가능한 더 작은 부분(“단어”)으로 나누는 방법 만 알고 있지만 렉서/토크 나이저는 비교할 때 훨씬 더 잘 알고 더 정확합니다.토크나이저는 컴파일 중인 언어의 복잡성과 사양을 알아야 합니다. 컴파일되는 언어에서 특정 의미를 가질 수 있는 경우 토크나이저는 이러한 세부 사항을 인식해야 합니다. 다른 한편으로,스캐너는 심지어 그것이 나누는 단어가 무엇인지,훨씬 덜 의미하는 것을 알지 못합니다.컴파일러의 스캐너는 훨씬 더 언어에 구애받지 않는 반면,토크나이저는 정의에 따라 언어별이어야 합니다.어휘 분석 프로세스의 이 두 부분은 서로 연관되어 있으며,이 두 부분은 컴파일 프로세스의 첫 번째 단계의 중심입니다. 물론 다른 컴플라이언스는 고유 한 방식으로 설계되었습니다. 일부 컴파일러는 단일 프로세스와 단일 프로그램으로 스캔 및 토큰 화 단계를 수행하는 반면 다른 컴파일러는 다른 클래스로 분할합니다.이 경우 토크 나이저는 스캐너 클래스를 실행할 때 호출됩니다.2018 년 11 월 1 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년 12 월 15 일,2018 년두 경우 모두 구문 분석 단계가 직접 의존하기 때문에 어휘 분석 단계가 컴파일에 매우 중요합니다. 그리고 컴파일러의 각 부분에는 고유 한 역할이 있지만 좋은 친구가 항상하는 것처럼 서로에게 의지하고 서로 의존합니다.컴파일러를 작성하고 디자인하는 방법에는 여러 가지가 있기 때문에 컴파일러를 가르치는 방법에는 여러 가지가 있습니다. 편집의 기초에 대한 충분한 연구를 할 경우,일부 설명이 다른 설명보다 훨씬 더 자세히 들어가는 것이 분명해지며,이는 도움이 될 수도 있고 그렇지 않을 수도 있습니다. 더 많은 것을 배우고 싶다면,아래는 어휘 분석 단계에 초점을 맞춘 컴파일러에 대한 다양한 리소스입니다.제 4 장-통역 제작,로버트 나이스트롬 컴파일러 구축,앨런 고트립 교수,제임스 앨런 파렐 교수,앤디 발람 프로그래밍 언어 작성—렉서,앤디 발람 파서와 컴파일러가 작동하는 방식에 대한 노트,스티븐 레이몬드 퍼그 토큰과 어휘의 차이점은 무엇입니까? 이 문제를 해결하는 방법은 무엇입니까?