et pap-smear analyseverktøy (PAT) for påvisning av livmorhalskreft fra pap-smear-bilder
Bildeanalyse
bildeanalysen for utvikling av et pap-smear analyseverktøy for påvisning av livmorhalskreft fra pap-smears presentert i Dette papiret er avbildet I Fig. 1.

tilnærmingen for å oppnå livmorhalskreft deteksjon fra pap-smøre bilder
bildeoppkjøp
tilnærmingen ble vurdert ved hjelp av tre datasett. Datasett 1 består av 917 enkeltceller Av Harlev pap-smøre bilder utarbeidet Av Jantzen et al. . Datasettet inneholder pap-smear-bilder tatt med en oppløsning på 0,201@m / pixel av dyktige cytopatologer ved hjelp av et mikroskop koblet til en ramme grabber. Bildene ble segmentert VED HJELP AV CHAMP kommersiell programvare og deretter klassifisert i syv klasser med distinkte egenskaper som vist i Tabell 2. Av disse 200 bildene ble brukt til trening og 717 bilder for testing.
Datasett 2 består av 497 full lysbilde pap-smøre bilder utarbeidet Av Norup et al. . Av disse 200 bildene ble brukt til trening og 297 bilder for testing. Videre ble ytelsen til klassifikatoren evaluert på Datasett 3 av prøver av 60 pap-smears (30 normale og 30 unormale) hentet fra Mbarara Regional Referral Hospital (MRRH). Prøvene ble avbildet ved Hjelp Av Et Olympus BX51 lysfeltmikroskop utstyrt med en 40×, 0.95 NA-linse og Et HAMAMATSU ORCA – 05g 1.4 mpx monokrom kamera, noe som ga en pikselstørrelse på 0.25 µ med 8-bit grå dybde. Hvert bilde ble deretter delt inn i 300 områder med hvert område som inneholdt mellom 200 og 400 celler. Basert på meninger fra cytopatologene ble 10.000 objekter i bilder avledet fra de 60 forskjellige pap-smear-lysbildene valgt, hvorav 8000 var frittliggende cervikale epitelceller (3000 normale celler fra normale smører og 5000 unormale celler fra unormale smører) og de resterende 2000 var rusk gjenstander. Dette pap-smøre segmentering ble oppnådd Ved Hjelp Av Trainable Weka segmentering toolkit å konstruere en pixel nivå segmentering klassifiserer.
Bildeforbedring
EN KONTRAST lokal adaptiv histogramutjevning (CLAHE) ble brukt på gråtonebildet for bildeforbedring . I CLAHE er valg av clip-limit som angir ønsket form av histogrammet til bildet avgjørende, da det kritisk påvirker kvaliteten på det forbedrede bildet. Den optimale verdien av klippegrensen ble valgt empirisk ved hjelp av metoden definert Av Joseph et al. . En optimal klipp grenseverdi på 2.0 ble bestemt å være hensiktsmessig for å gi tilstrekkelig bildeforbedring samtidig som de mørke funksjonene for datasettene ble bevart. Konvertering til gråtoner ble oppnådd ved hjelp av en gråtoneteknikk implementert Ved Hjelp Av Eq. 1 som definert i .
Hvor R = Rød, G = Grønn Og B = Blå farge bidrag til det nye bildet.Anvendelse AV CLAHE for bildeforbedring resulterte i merkbare endringer i bildene ved å justere bildeintensiteter hvor mørkningen av kjernen, så vel som cytoplasmens grenser, ble lett identifiserbar ved hjelp av en klippgrense på 2,0.
Scenesegmentering
for å oppnå scenesegmentering ble en pikselnivåklassifisering utviklet ved Hjelp AV Trainable WEKA Segmentation (TWS) toolkit. Flertallet av celler observert i en pap-smøre er ikke overraskende cervical epitelceller . I tillegg er varierende antall leukocytter, erytrocytter og bakterier vanligvis tydelige, mens små antall andre forurensende celler og mikroorganismer noen ganger observeres. Imidlertid inneholder pap-smear fire hovedtyper av squamous cervical celler-overfladisk, mellomliggende, parabasal og basal – hvorav overfladiske og mellomliggende celler representerer det overveldende flertallet i et konvensjonelt smear; derfor brukes disse to typene vanligvis til en konvensjonell pap-smear-analyse . En trainable weka segmentering ble brukt til å identifisere og segmentere de ulike objektene på lysbildet. På dette stadiet ble en pikselnivåklassifisering trent på cellekjerner, cytoplasma, bakgrunn og ruskidentifikasjon ved hjelp av en dyktig cytopatolog ved Hjelp Av Trainable Weka Segmentation (TWS) toolkit . Dette ble oppnådd ved å tegne linjer / utvalg gjennom interesseområder og tildele dem til en bestemt klasse. Pikslene under linjene / utvalget ble tatt for å være representant for kjernene, cytoplasma, bakgrunn og rusk.
omrissene trukket innenfor hver klasse ble brukt til å generere en funksjonsvektor, \(\mathop F \ limits^ {\to}\) som ble avledet fra antall piksler som tilhører hver disposisjon. Funksjonsvektoren fra hvert bilde (200 Fra Datasett 1 og 200 Fra Datasett 2) ble definert Av Eq. 2.
Hvor Ni, Ci, Bi og Di er antall piksler fra kjernen, cytoplasma, bakgrunn og rusk av bilde \(i\) som vist på Fig. 2.

Generering av funksjonsvektoren fra treningsbildene
Hver piksel hentet fra bildet representerer Ikke bare intensiteten, Men også et sett med bildefunksjoner som inneholder mye informasjon, inkludert tekstur, grenser og farge innenfor et pikselområde på 0.201@m2. Å velge en passende funksjonsvektor for å trene klassifikatoren var en stor utfordring og en ny oppgave i den foreslåtte tilnærmingen. Pixel level classifier ble trent med totalt 226 treningsfunksjoner FRA TWS. Klassifikatoren ble trent ved hjelp AV ET sett MED TWS treningsfunksjoner som inkluderte: (i) Støyreduksjon: Kuwahara og Bilaterale filtre i TWS toolkit ble brukt til å trene klassifikatoren på støyfjerning. Disse har blitt rapportert å være gode filtre for å fjerne støy mens kantene bevares , (ii) Kantdeteksjon: Et Sobel-filter, Hessisk matrise og Gabor-filter ble brukt til å trene klassifikatoren på grensedeteksjon i et bilde, og (iii) Teksturfiltrering: Gjennomsnittlig, varians, median, maksimum, minimum og entropi filtre ble brukt til teksturfiltrering.
Rusk fjerning
hovedårsaken til dagens begrensninger av mange av de eksisterende automatiserte pap-smøre analysesystemer er at de sliter med å overvinne kompleksiteten i pap-smøre strukturer, ved å prøve å analysere lysbildet som helhet, som ofte inneholder flere celler og rusk. Dette har potensial til å forårsake feilen i algoritmen og krever høyere beregningskraft . Prøver er dekket av gjenstander—som blodceller, overlappende og brettede celler og bakterier – som hemmer segmenteringsprosessene og genererer et stort antall mistenkelige gjenstander. Det har vist seg at klassifikatorer designet for å skille mellom normale celler og prekreftceller vanligvis gir uforutsigbare resultater når gjenstander finnes i pap-smear . I dette verktøyet, en teknikk for å identifisere cervix celler ved hjelp av en tre-fase sekvensiell eliminering ordningen (avbildet I Fig. 3) brukes.

tre-fase sekvensiell eliminering tilnærming for rusk avvisning
den foreslåtte tre-fase eliminering ordningen sekvensielt fjerner rusk fra pap-smøre hvis det anses usannsynlig å være en cervixcelle. Denne tilnærmingen er gunstig da det tillater en lavere dimensjonal beslutning å bli gjort i hvert trinn.
Størrelsesanalyse
Størrelsesanalyse er et sett med prosedyrer for å bestemme en rekke størrelsesmålinger av partikler . Området er en av de mest grunnleggende funksjonene som brukes innen automatisert cytologi for å skille celler fra rusk. Pap-smear-analysen er et godt studert felt med mye forkunnskap om celleegenskaper . En av de viktigste endringene med kjerneområdet vurdering er imidlertid at kreftceller gjennomgår en betydelig økning i kjernefysisk størrelse . Derfor er det mye vanskeligere å bestemme en øvre størrelsesgrense som ikke systematisk utelukker diagnostiske celler, men har fordelen av å redusere søkeplassen. Metoden som presenteres i dette papiret er basert på en lavere størrelse og øvre størrelsesgrense for livmorhalscellene. Pseudokoden for tilnærmingen er vist I Eq. 3.
hvor \(Area_{max} = 85,267\,{\upmu \text{m}}^{2}\) og \(Area_{Min} = 625\,{\upmu \Text{M}}^{2}\) avledet fra tabell 2.
objektene i bakgrunnen betraktes som rusk og dermed kasseres fra bildet. Partikler som faller mellom \(Area_{min}\) og \(Area_ {max}\) analyseres videre i de neste stadiene av tekstur og formanalyse.
Formanalyse
formen på objektene i en celleprøve er et nøkkelelement i differensieringen mellom celler og rusk . Det finnes en rekke metoder for gjenkjenning av formbeskrivelser, og disse inkluderer regionbaserte og konturbaserte tilnærminger . Regionbaserte metoder er mindre følsomme for støy, men mer beregningsmessig intensive, mens konturbaserte metoder er relativt effektive å beregne, men mer følsomme for støy . I dette papiret har en regionbasert metode (perimeter2/area (P2A)) blitt brukt . P2a-beskrivelsen ble valgt på grunn av at den beskriver likheten til et objekt til en sirkel. Dette gjør det godt egnet som en cellekjerne descriptor siden kjerner er generelt sirkulære i sitt utseende. P2A er også referert til som form kompakthet og er definert Av Eq. 4.
hvor c er verdien av formkompaktitet, A er området og p er omkretsen av kjernen. Rusk ble antatt å være objekter MED EN p2a-verdi større enn 0,97 eller mindre enn 0,15 i henhold til treningsfunksjonene (avbildet I Tabell 2).
Teksturanalyse
Tekstur Er et svært viktig karakteristisk trekk som kan skille mellom kjerner og rusk. Bildetekstur er et sett med beregninger som er utformet for å kvantifisere den oppfattede tekstur av et bilde . Innenfor en pap-smøre, fordelingen av gjennomsnittlig kjernefysisk flekk intensitet er mye smalere enn flekken intensitet variasjon blant rusk objekter . Dette faktum ble brukt som grunnlag for å fjerne rusk basert På bildeintensiteter og fargeinformasjon ved Hjelp Av Zernike moments (ZM) . Zernike moments brukes til en rekke mønstergjenkjenningsprogrammer og er kjent for å være robuste med hensyn til støy og å ha en god rekonstruksjonskraft. I dette arbeidet, ZM som presentert Av Malm et al. av funksjon \(f\venstre ({r,\theta } \ høyre)\), i polarkoordinater inne i en disk sentrert i firkantet bilde \(i \venstre ({x,y}\ høyre)\) av størrelse \(m\ ganger m\) gitt Av Eq. 5 ble brukt.
\(v_{nl }^{*} \venstre( {r,\Theta } \høyre)\) betegner det komplekse konjugatet til zernike-polynomet \(v_{nl} \venstre( {r,\theta } \høyre)\). For å produsere et teksturmål, er størrelsene fra \(a_{nl}\) sentrert ved hver piksel i teksturbildet i gjennomsnitt .
Feature extraction
suksessen til en klassifiseringsalgoritme er i stor grad avhengig av korrektheten av funksjonene hentet fra bildet. Cellene i celleprøvene i datasettet som brukes er delt inn i syv klasser basert på egenskaper som størrelse, areal, form og lysstyrke av kjernen og cytoplasma. Funksjonene hentet fra bildene inkludert morfologi funksjoner tidligere brukt av andre . I dette papiret tre geometriske funksjoner (soliditet, kompakthet og eksentrisitet) og seks tekstlige funksjoner (gjennomsnitt, standardavvik, varians, glatthet, energi og entropi) ble også hentet fra kjernen, noe som resulterer i 29 funksjoner totalt som vist i Tabell 3.
Funksjonsvalg
Funksjonsvalg er prosessen med å velge delsett av de ekstraherte funksjonene som gir de beste klassifiseringsresultatene. Blant disse funksjonene hentet, noen kan inneholde støy mens den valgte klassifikatoren ikke kan utnytte andre. Derfor må et optimalt sett med funksjoner bestemmes, muligens ved å prøve alle kombinasjoner. Men når det er mange funksjoner, eksploderer de mulige kombinasjonene i antall, og dette øker algoritmenes beregningskompleksitet. Funksjon utvalg algoritmer er grovt klassifisert i filteret, wrapper og innebygde metoder .
metoden som brukes av verktøyet kombinerer simulert glødning med en wrapper-tilnærming. Denne tilnærmingen er foreslått i, men, i denne artikkelen, ytelsen til funksjonen utvalget er evaluert ved hjelp av en dobbel-strategi tilfeldig skog algoritme . Simulert annealing er en probabilistisk teknikk for å tilnærme det globale optimumet av en gitt funksjon. Tilnærmingen er godt egnet for å sikre at det optimale settet av funksjoner er valgt. Søket etter det optimale settet styres av en treningsverdi . Når simulert glødning er ferdig, sammenlignes alle de forskjellige delsettene av funksjoner og den fitteste (det vil si den som utfører det beste) velges. Fitness value search ble oppnådd med en wrapper hvor k-fold kryssvalidering ble brukt til å beregne feilen på klassifiseringsalgoritmen. Ulike kombinasjoner fra de ekstraherte funksjonene blir utarbeidet, evaluert og sammenlignet med andre kombinasjoner. En prediktiv modell brukes deretter til å evaluere en kombinasjon av funksjoner og tildele en poengsum basert på modellens nøyaktighet. Fitness feil gitt av wrapper brukes som fitness feil av simulert annealing algoritmen. En fuzzy c-means algoritme ble pakket inn i en svart boks, hvorfra en estimert feil ble oppnådd for de forskjellige funksjonskombinasjonene som vist I Fig. 4.

fuzzy C-midler er pakket inn i en svart boks hvorfra en estimert feil er oppnådd
Fuzzy C-midler tillater datapunkter i datasett til å tilhøre alle klyngene, med medlemskap i intervallet (0-1) som vist i eq. 6.
hvor \(m_{ik}\) er medlemskapet for datapunkt k til klyngesenter i, \(d_{jk}\) er avstanden fra klyngesenter j til datapunkt k og q € er en eksponent som bestemmer hvor sterk medlemskapet skal være. Fuzzy C-means-algoritmen ble implementert ved hjelp av fuzzy toolbox I Matlab.
defuzzification
en fuzzy c-means-algoritme forteller oss ikke hvilken informasjon klyngene inneholder og hvordan denne informasjonen skal brukes til klassifisering. Det definerer imidlertid hvordan datapunkter tilordnes medlemskap i de forskjellige klyngene, og dette fuzzy medlemskapet brukes til å forutsi klassen av et datapunkt . Dette overvinnes gjennom defuzzification. En rekke defuzzification metoder eksisterer . Men i dette verktøyet har hver klynge et fuzzy medlemskap (0-1) av alle klasser i bildet. Treningsdata er tilordnet klyngen nærmest den. Prosentandelen av treningsdata for hver klasse som tilhører klynge a gir klyngens medlemskap, klynge a = til de forskjellige klassene, hvor jeg er inneslutning I klynge A og j i den andre klyngen. Intensitetsmålet legges til medlemskapsfunksjonen for hver klynge ved hjelp av en uklar clustering defuzzification-algoritme. En populær tilnærming for defuzzification av fuzzy partisjon er anvendelsen av maksimal medlemskap grad prinsippet der datapunkt k er tildelt klasse m hvis, og bare hvis, dens medlemskap grad \(m_{ik}\) til klynge i, er den største. Chuang et al. foreslått å justere medlemskapsstatusen for hvert datapunkt ved hjelp av medlemskapsstatusen til sine naboer.
i den foreslåtte tilnærmingen brukes en defuzzifiseringsmetode basert På Bayesiansk sannsynlighet for å generere en probabilistisk modell av medlemsfunksjonen for hvert datapunkt og anvende modellen på bildet for å produsere klassifiseringsinformasjonen. Den probabilistiske modellen beregnes som nedenfor:
-
Konverter mulighetsfordelingene i partisjonsmatrisen (klynger) til sannsynlighetsfordelinger.
-
Konstruer en probabilistisk modell av datafordelingene som i .
-
Bruk modellen til å produsere klassifiseringsinformasjonen for hvert datapunkt ved Hjelp Av Eq. 7.
hvor \(p\venstre ({a_ {i}} \høyre),i = 0 \ldots .c\) er den tidligere sannsynligheten for \(a_{i}\) som kan beregnes ved hjelp av metoden der den tidligere sannsynligheten alltid er proporsjonal med massen av hver klasse.
antall klynger som skulle brukes ble bestemt for å sikre at den bygde modellen kan beskrive dataene på best mulig måte. Hvis for mange klynger er valgt, er det fare for overfitting av støyen i dataene. Hvis for få klynger er valgt, kan en dårlig klassifiserer være resultatet. Derfor ble det utført en analyse av antall klynger mot kryssvalideringstestfeilen. Et optimalt antall 25 klynger ble oppnådd og overtraining skjedde over disse antall klynger. En defuzzification eksponent av 1.0930 ble oppnådd med 25 klynger, tifold kryssvalidering og 60 repriser og ble brukt til å beregne fitness feil for funksjonsvalg der totalt 18 funksjoner ut av 29 funksjoner ble valgt for bygging av klassifikatoren. De valgte funksjonene var: kjernen området; kjernen grå nivå; kjernen korteste diameter; kjernen lengste; kjernen perimeter; maxima i kjernen; minima i kjernen; cytoplasma området; cytoplasma grå nivå; cytoplasma perimeter; kjernen til cytoplasma ratio; kjernen eksentrisitet, kjernen standardavvik, kjernen grå nivå varians; kjernen grå nivå entropi; nucleus relative posisjon; nucleus grå nivå gjennomsnitt og nucleus grå verdier energi.
Klassifiseringsevaluering
i dette papiret ble den hierarkiske modellen for effekten av diagnostiske bildesystemer foreslått av Fryback og Thornbury vedtatt som et ledende prinsipp for evalueringen av verktøyet som vist i Tabell 4.
sensitivitet måler andelen faktiske positive som er korrekt identifisert som sådan, mens spesifisitet måler andelen faktiske negative som er korrekt identifisert som sådan. Sensitivitet og spesifisitet beskrives Med Eq. 8.
HVOR TP = Sanne positiver, FN = Falske negativer, TN = Sanne negativer og Fp = Falske positiver.
GUI design og integrasjon
bildebehandlingsmetodene beskrevet ovenfor ble implementert I Matlab og utføres via Et Java graphical user interface (GUI) vist I Fig. 5. Verktøyet har et panel hvor en pap-smøre bilde er lastet og cytotechnician velger en passende metode for scene segmentering (basert PÅ TWS klassifikator), rusk fjerning (basert på tre sekvensiell eliminering tilnærming) og grense deteksjon (hvis det anses nødvendig, Ved Hjelp Av Canny edge detection metode), etter som funksjoner er hentet ved hjelp av ekstrakt funksjoner knappen.
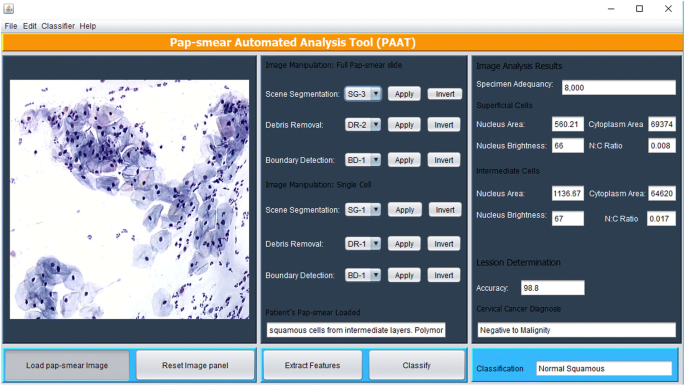
PAT grafisk brukergrensesnitt
verktøyet skanner gjennom pap-smear for å analysere alle objektene som ble igjen etter fjerning av rusk. De 18 funksjonene som er beskrevet i funksjonsvalg, hentes fra hvert objekt og brukes til å klassifisere hver celle ved hjelp av fuzzy C-means-algoritmen beskrevet i klassifiseringsmetoden. Tilfeldig, ekstraherte funksjoner av en overfladisk celle og en mellomliggende celle vises i bildeanalyseresultatpanelet. Når funksjonene er trukket ut, trykker cytoteknikeren (brukeren) på klassifiseringsknappen og verktøyet avgir en diagnose (positiv til malignitet eller negativ til malignitet) og klassifiserer diagnosen til en av de 7 klassene/stadiene av livmorhalskreft i henhold til treningsdatasettet.