Få Tak I Forsterkning Læring Via Markov Decision Process
denne artikkelen ble publisert som En del Av Data Science Blogathon.
Introduksjon
Forsterkende Læring (Rl) Er En læringsmetodikk der eleven lærer å oppføre seg i et interaktivt miljø ved hjelp av egne handlinger og belønninger for sine handlinger. Eleven, ofte kalt agent, oppdager hvilke handlinger som gir maksimal belønning ved å utnytte og utforske dem.

et sentralt spørsmål er – hvordan ER RL forskjellig fra overvåket og uten tilsyn læring?
forskjellen kommer i interaksjonsperspektivet. Overvåket læring forteller brukeren / agenten direkte hvilken handling han må utføre for å maksimere belønningen ved hjelp av et treningsdatasett med merkede eksempler. PÅ DEN annen side gjør RL direkte agenten til å benytte seg av belønninger (positiv og negativ) det blir å velge sin handling. Det er dermed forskjellig fra uovervåket læring også fordi uovervåket læring handler om å finne struktur skjult i samlinger av umerkede data.
Forsterkning Læring Formulering Via Markov Decision Process (MDP)
de grunnleggende elementene i en forsterkning læring problem er:
- Miljø: omverdenen som agenten samhandler
- Tilstand: nåværende situasjon av agenten
- Belønning: Numerisk tilbakemelding signal fra miljøet
- Policy: Metode for å kartlegge agentens tilstand til handlinger. En policy brukes til å velge en handling i en gitt tilstand
- Verdi: Fremtidig belønning (forsinket belønning) som en agent vil motta ved å ta en handling i en gitt tilstand
Markov Decision Process (MDP) Er et matematisk rammeverk for å beskrive et miljø i forsterkende læring. Følgende figur viser agent-miljøinteraksjon I MDP:
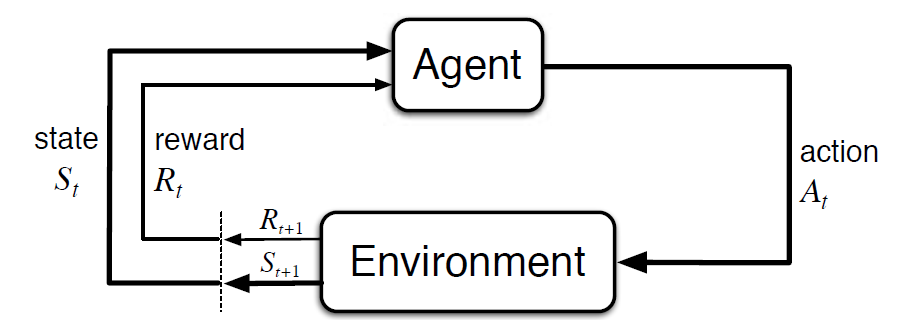
mer spesifikt, agenten og miljøet samhandle på hvert diskret tid trinn, t = 0, 1, 2, 3…At hver gang trinn, agenten får informasjon om miljøtilstanden St. Basert på miljøtilstanden på instant t, agenten velger en handling På. I det følgende øyeblikk mottar agenten også et numerisk belønningssignal Rt+1. Dette gir dermed opphav Til en sekvens Som S0, A0, R1, S1, A1, R2…
de tilfeldige variablene Rt og St har veldefinerte diskrete sannsynlighetsfordelinger. Disse sannsynlighetsfordelingene er bare avhengige av den foregående tilstanden og handlingen i kraft Av Markovs Eiendom. La S, A og R være sett av stater, handlinger og belønninger. Da er sannsynligheten for at verdiene For St, Rt og ved å ta verdiene s’, r og a med tidligere tilstand s gitt av,
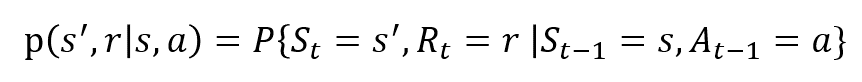
funksjonen p styrer dynamikken i prosessen..
La oss Forstå dette ved Å Bruke Et Eksempel
la oss nå diskutere et enkelt eksempel DER RL kan brukes til å implementere en kontrollstrategi for en oppvarmingsprosess.
tanken er å kontrollere temperaturen i et rom innenfor de angitte temperaturgrensene. Temperaturen inne i rommet påvirkes av eksterne faktorer som utetemperatur, den indre varmen som genereres, etc.
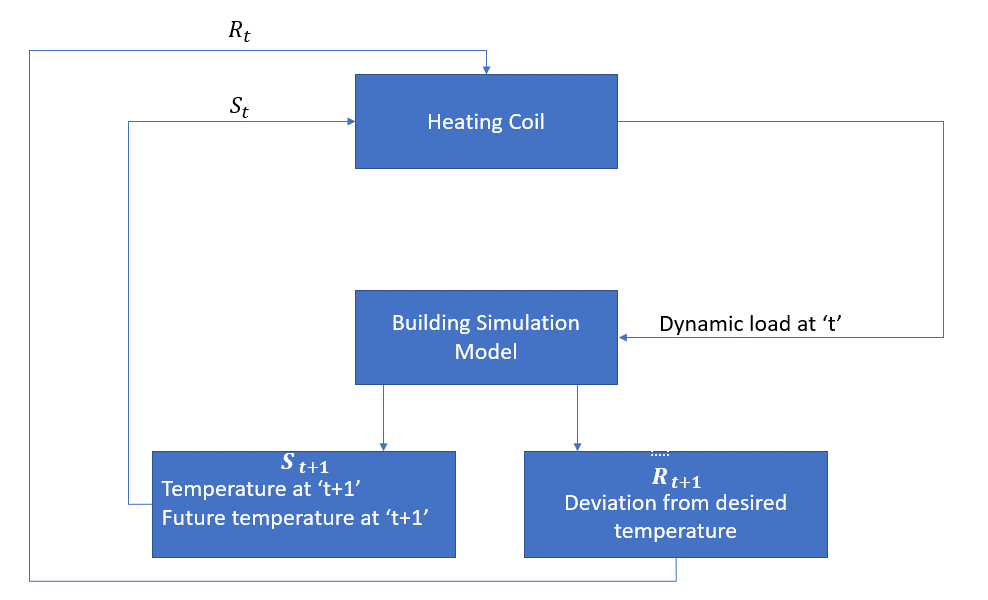
agenten er i dette tilfellet varmespolen som må bestemme mengden varme som kreves for å kontrollere temperaturen inne i rommet ved å samhandle med miljøet og sikre at temperaturen inne i rommet er innenfor det angitte området. Belønningen, i dette tilfellet, er i utgangspunktet kostnaden betalt for å avvike fra de optimale temperaturgrensene.
handlingen for agenten er den dynamiske belastningen. Denne dynamiske belastningen blir deretter matet til romsimulatoren, som i utgangspunktet er en varmeoverføringsmodell som beregner temperaturen basert på den dynamiske belastningen. Så i dette tilfellet er miljøet simuleringsmodellen. Staten variabel St inneholder nåtid så vel som fremtidige belønninger.
følgende blokkdiagram forklarer hvordan MDP kan brukes til å kontrollere temperaturen inne i et rom:
Begrensninger av Denne Metoden
Forsterkningslæring lærer av staten. Staten er innspill for politikkutforming. Derfor bør statens innganger være riktig gitt. Også som vi har sett, er det flere variabler og dimensjonaliteten er enorm. Så å bruke det for ekte fysiske systemer ville være vanskelig!
Videre Lesing
For å vite mer OM RL, kan følgende materialer være nyttige:
- Forsterkningslæring: En Introduksjon Av Richard.S. Sutton Og Andrew.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- Videoforelesninger Av David Silver tilgjengelig På YouTube
- https://gym.openai.com/ er en verktøykasse for videre utforskning
Du kan også lese denne artikkelen på Vår Mobile APP![]()
