Regresjon Trær
alle regresjon teknikker inneholder en enkelt utgang (respons) variabel og en eller flere input (predictor) variabler. Utgangsvariabelen er numerisk. Den generelle regresjon tree building metodikk tillater input variabler å være en blanding av kontinuerlige og kategoriske variabler. Et beslutningstreet genereres når hver beslutning node i treet inneholder en test på noen input variabel verdi. Terminalnodene i treet inneholder de anslåtte variabelverdiene for utdata. Et Regresjonstre kan betraktes som en variant av beslutningstrær, designet for å tilnærme reelle funksjoner, i stedet for å bli brukt til klassifiseringsmetoder. et regresjonstre er bygget gjennom en prosess kjent som binær rekursiv partisjonering, som er en iterativ prosess som deler dataene i partisjoner eller grener, og fortsetter deretter å splitte hver partisjon i mindre grupper etter hvert som metoden beveger seg opp hver gren.
I Utgangspunktet grupperes alle poster i Treningssettet (forhåndsklassifiserte poster som brukes til å bestemme strukturen til treet) i samme partisjon. Algoritmen begynner deretter å allokere dataene i de to første partisjonene eller grenene, ved å bruke alle mulige binære splittelser på hvert felt. Algoritmen velger splitten som minimerer summen av de kvadrerte avvikene fra gjennomsnittet i de to separate partisjonene. Denne splittregelen brukes deretter på hver av de nye grenene. Denne prosessen fortsetter til hver node når en brukerdefinert minimum nodestørrelse og blir en terminal node. (Hvis summen av kvadrerte avvik fra gjennomsnittet i en node er null, betraktes den noden som en terminal node selv om den ikke har nådd minimumsstørrelsen.)
Beskjæring Av Treet
Siden treet vokser fra Treningssettet, lider et fullt utviklet tre vanligvis av overtilpasning (dvs.det forklarer tilfeldige elementer I Treningssettet som ikke sannsynligvis vil være trekk ved den større befolkningen). Dette over-montering resulterer i dårlig ytelse på virkelige data. Derfor må treet beskjæres ved Hjelp Av Valideringssettet. XLMiner beregner kostnadskompleksitetsfaktoren ved hvert trinn under veksten av treet og bestemmer antall beslutningsnoder i det beskårne treet. Kostnadskompleksitetsfaktoren er multiplikasjonsfaktoren som brukes på størrelsen på treet (målt ved antall terminale noder).
treet beskjæres for å minimere summen av: 1) utgangsvariabelvariansen i valideringsdataene, tatt en terminalnode om gangen; og 2) produktet av kostnadskompleksitetsfaktoren og antall terminalnoder. Hvis kostnadskompleksitetsfaktoren er angitt som null, er beskjæring ganske enkelt å finne treet som fungerer best på valideringsdata når det gjelder total terminalnodeavvik. Større verdier av kostnadskompleksitetsfaktoren resulterer i mindre trær. Beskjæring utføres på en siste inn først ut basis, noe som betyr at den siste voksen node er den første til å bli gjenstand for eliminering. Xlminer V2015 tilbyr tre kraftige ensemble metoder for bruk Med Regresjon trær: bagging( bootstrap aggregating), boosting, og tilfeldige trær. Regresjonstrealgoritmen kan brukes til å finne en modell som resulterer i gode spådommer for de nye dataene. Vi kan se statistikken og forvirringsmatrisene til den nåværende prediktoren for å se om modellen vår passer godt til dataene; men hvordan vil vi vite om det er en bedre prediktor som bare venter på å bli funnet? Svaret er at vi ikke vet om en bedre prediktor eksisterer. Ensemblemetoder tillater oss imidlertid å kombinere flere svake regresjonstremodeller, som sammen danner en ny, nøyaktig, sterk regresjonstremodell. Disse metodene fungerer ved å opprette flere forskjellige regresjonsmodeller, ved å ta forskjellige prøver av det opprinnelige datasettet, og deretter kombinere utgangene. (Utganger kan kombineres med flere teknikker for eksempel flertall for klassifisering og gjennomsnitt for regresjon) denne kombinasjonen av modeller reduserer effektivt variansen i den sterke modellen. De tre typene ensemble-metoder som Tilbys I XLMiner (bagging, boosting og random trees) varierer på tre elementer: 1) valg Av Treningssett for hver prediktor eller svak modell; 2) hvordan de svake modellene genereres; og 3) hvordan utgangene kombineres. I alle tre metodene er hver svak modell trent på hele Treningssettet for å bli dyktig i en del av datasettet.Bagging (bootstrap aggregating) var en av de første ensemble algoritmer noensinne å bli skrevet. Det er en enkel algoritme, men svært effektiv. Bagging genererer flere Treningssett ved hjelp av tilfeldig prøvetaking med erstatning( bootstrap sampling), gjelder regresjon treet algoritmen til hvert datasett, så tar gjennomsnittet blant modellene for å beregne spådommer for de nye dataene. Den største fordelen med bagging er den relative enkelheten at algoritmen kan parallelliseres, noe som gjør det til et bedre valg for svært store datasett. Boosting bygger en sterk modell ved suksessivt å trene modeller for å konsentrere seg om poster som mottar unøyaktige forventede verdier i tidligere modeller. Etter fullført, er alle prediktorer kombinert med en vektet flertall. XLMiner tilbyr tre varianter av boosting som implementert Av AdaBoost algoritmen (en av de mest populære ensemble algoritmer i bruk i dag): M1 (Freund), M1 (Breiman), OG SAMME (Stagewise Additiv Modellering ved Hjelp Av En Multi-klasse Eksponentiell).
Adaboost.M1 tildeler først en vekt (wb (i)) til hver post eller observasjon. Denne vekten er opprinnelig satt til 1 / n, og vil bli oppdatert på hver iterasjon av algoritmen. Et opprinnelig regresjonstre opprettes ved hjelp av Dette Første Treningssettet (Tb), og en feil beregnes som
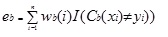
hvor returnerer i () – funksjonen 1 hvis sann og 0 hvis ikke.
feilen til regresjonstreet i bth-iterasjonen brukes til å beregne konstanten ?b. Denne konstanten brukes til å oppdatere vekten (wb (i). I AdaBoost.M1 (Freund), konstanten beregnes som
ab= ln ((1-eb)/eb)
I AdaBoost.M1 (Breiman), konstanten beregnes som
ab= 1 / 2ln ((1-eb)/eb)
I SAMME beregnes konstanten som
ab= 1/2ln ((1-eb)/eb + ln (k-1) hvor k er antall klasser
hvor, antall kategorier er lik 2, SAMME oppfører Seg som AdaBoost Breiman.
I noen av de tre implementeringene (Freund, Breiman eller SAMME), vil den nye vekten for (b + 1)iterasjonen være

etterpå blir vektene alle justert til summen av 1. Som et resultat økes vektene som er tildelt observasjonene som ble tildelt unøyaktige forventede verdier, og vektene som er tildelt observasjonene som ble tildelt nøyaktige forventede verdier, reduseres. Denne justeringen tvinger den neste regresjonsmodellen til å legge mer vekt på postene som ble tildelt unøyaktige spådommer. (Dette ? konstant brukes også i den endelige beregningen, noe som vil gi regresjonsmodellen med den laveste feilen mer innflytelse.) Denne prosessen gjentas til b = antall svake elever. Algoritmen beregner deretter det veide gjennomsnittet blant alle svake elever og tilordner denne verdien til posten. Boosting gir generelt bedre modeller enn bagging; det har imidlertid en ulempe da det ikke er parallelizable. Som et resultat, hvis antall svake elever er store, ville boosting ikke være egnet.
random trees-metoden (random forests) er en variant av bagging. Denne metoden fungerer ved å trene flere svake regresjonstrær ved hjelp av et fast antall tilfeldig valgte funksjoner (sqrt for klassifisering og antall funksjoner/3 for prediksjon), og tar deretter gjennomsnittsverdien for de svake elevene og tildeler den verdien til den sterke prediktoren. Vanligvis kan antall svake trær generert variere fra flere hundre til flere tusen, avhengig av størrelsen og vanskeligheten til treningssettet. Tilfeldige trær er parallelliserbare, siden de er en variant av bagging. Men siden tandom trees velger en begrenset mengde funksjoner i hver iterasjon, er ytelsen til tilfeldige trær raskere enn bagging. Regresjonstreet Ensemble metoder er svært kraftige metoder, og resulterer vanligvis i bedre ytelse enn et enkelt tre. Denne funksjonen tillegg I XLMiner V2015 gir mer noyaktige prediksjonsmodeller, og bor vurderes over single tree-metoden.