seaborn.histplot¶
seaborn.histplot(data=Ingen, *, x=Ingen, y=Ingen, hue=Ingen, vekter=ingen, stat=’count’, hyller=’auto’, binwidth=Ingen, binrange=ingen, diskret=Ingen, kumulativ=False, common_bins=True, common_norm=True, multiple=’layer’, element=’bars’, fill=true, shrink=1, kde=false, kde_kws=none, line_kws=none, thresh=0, pthresh=none, pmax=none, cbar=false, cbar_ax=none, Cbar_kws=none, Palette=none, hue_order=none, hue_norm=none, color=none, log_scale=none, legend=true, ax=none, **Kwargs)¶
plot univariate eller bivariate histogrammer for å vise distribusjoner av datasett.et histogram er et klassisk visualiseringsverktøy som representerer fordelingen av en eller flere variabler ved å telle antall observasjoner som faller inn i indisrete hyller.
denne funksjonen kan normalisere statistikken beregnet i hver bin for å estimatefrekvens, tetthet eller sannsynlighetsmasse, og den kan legge til en jevn kurve oppnådd ved hjelp av et kjernetetthetsestimat, som ligner på kdeplot().
Mer informasjon finnes i brukerhåndboken.
Parametere datapandas.DataFramenumpy.ndarray, tilordning eller sekvens
inndatastruktur. Enten en langformet samling av vektorer som kan tilordnes navngitte variabler eller et bredt datasett som vil bli internallyreshaped.
x, yvektorer eller taster idata
Variabler som angir posisjoner på x-og y-aksene.
huevector eller nøkkel idata
Semantisk variabel som er kartlagt for å bestemme fargen på plottelementer.
weightsvector eller nøkkel idata
hvis oppgitt, vekt bidraget til de tilsvarende datapunktenemot tellingen i hver bin av disse faktorene.
stat {«count», «frequency», «density», «probability»}
Samlet statistikk for å beregne i hver bin.
-
countviser antall observasjoner -
frequencyviser antall observasjoner dividert med bin bredde -
densitynormaliserer teller slik at arealet av histogrammet er 1 -
probabilitynormaliserer teller slik at summen av barhøydene er 1
binsstr, tall, vektor, eller et par av slike verdier
generisk bin parameter som kan være navnet på en referanseregel,antall hyller, eller pauser av hyllene.Sendt til numpy.histogram_bin_edges().Bredden på hver bin, overstyrer bins men kan brukes med binrange.Laveste og høyeste verdi for bin kanter; kan brukes enten med bins eller binwidth. Standard til data ekstremer.
discretebool
hvis Sann, standard til binwidth=1 og tegne stolpene slik at de er sentrert på deres tilsvarende datapunkter. Dette unngår «hull» som kanellers vises når du bruker diskrete (heltall) data.
cumulativebool
hvis Sann, plott de kumulative teller som hyller øke.hvis Sant, bruk de samme hyllene når semantiske variabler produserer multiplott. Hvis du bruker en referanseregel for å bestemme hyllene, vil den bli beregnet med hele datasettet.
common_normbool
Hvis Sann og bruker en normalisert statistikk, vil normaliseringen gjelde over hele datasettet. Ellers normaliser hvert histogram uavhengig.
multiple{«layer», «dodge», «stack», «fill»}
Tilnærming til å løse flere elementer når semantisk kartlegging skaper delsett.Kun relevant med univariate data.
element{«bars»,» step»,» poly»}
Visuell representasjon av histogramstatistikken .Kun relevant med univariate data.
fillbool
hvis Sann, fyll ut plassen under histogrammet.Kun relevant med univariate data.
shrinknumber
Skaler bredden på hver stolpe i forhold til binbredden med denne faktoren.Kun relevant med univariate data.hvis Sann, beregne et kjernetetthetsestimat for å jevne ut distribusjonen og vis på plottet som (en eller flere) linjer.Kun relevant med univariate data.
Kde_kwsdict
Parametere som styrer kde-beregningen, som i kdeplot().
line_kwsdict
Parametere som styrer kde-visualiseringen, sendes til matplotlib.axes.Axes.plot().
threshnumber eller Ingen
Celler med en statistikk mindre enn eller lik denne verdien vil være gjennomsiktig.Kun relevant med bivariate data.
pthreshnumber or None
Somthresh, men en verdi i slik at celler med aggregerte teller (eller annen statistikk, når de brukes) opp til denne andelen av totalen vil væregjennomsiktig.
pmaxnumber or None
en verdi i dette angir metningspunktet for fargekartet til en verdi slik at cellene under er forstoppet denne andelen av det totale antallet (eller annen statistikk, når den brukes).
cbarbool
hvis Sann, legg til et fargefelt for å annotere fargetilordningen i et bivariat-plott.Merk: støtter for øyeblikket ikke tomter med enhue variabel brønn.
cbar_axmatplotlib.axes.Axes
eksisterende akser for colorbar.
cbar_kwsdict
Flere parametere sendes til matplotlib.figure.Figure.colorbar().
palettestring, list, dict ellermatplotlib.colors.Colormap
Metode for å velge farger som skal brukes når du tilordnerhue semantisk.Strengverdier sendes til color_palette(). Liste eller dict valuesimply kategorisk kartlegging, mens en colormap objekt innebærer numerisk kartlegging.
hue_ordervector av strenger
Angi rekkefølgen for behandling og plotting for kategoriske nivåer avhue semantisk.
hue_normtuple ellermatplotlib.colors.Normalize
enten et par verdier som angir normaliseringsområdet i dataenhetereller et objekt som vil kartlegge fra dataenheter til et intervall. Usageimplies numerisk kartlegging.
fargematplotlib color
Enkeltfargespesifikasjon for når hue-kartlegging ikke brukes. Ellers, theplot vil prøve å koble inn i matplotlib eiendom syklus.
log_scalebool eller tall, Eller par bools eller numbers
Sett en loggskala på dataaksen (eller akser, med bivariate data) med gitt base (standard 10), og evaluer KDE i loggplass.
legendbool
hvis False, skjul forklaringen for semantiske variabler.
axmatplotlib.axes.Axes
eksisterende akser for plottet. Ellers kaller dumatplotlib.pyplot.gca()internt.
kwargs
andre søkeordargumenter sendes til en av følgende matplotlibfunksjoner:
-
matplotlib.axes.Axes.bar()(univariate, element=»bars») -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
Plott univariate eller bivariate distribusjoner ved hjelp av kjernetetthetsestimering.
rugplot
Plott et kryss ved hver observasjonsverdi langs x-og / eller y-aksene.
ecdfplot
Plott empiriske kumulative fordelingsfunksjoner.
jointplot
Tegn et bivariat plott med univariate marginale fordelinger.
Merknader
valget av hyller for å beregne og plotte et histogram kan utøve betydelig innflytelse på innsiktene som man kan tegne fravisualisering. Hvis hyllene er for store, kan de slette viktige funksjoner.På den annen side kan hyller som er for små, domineres av randomvariabilitet, som skjuler formen på den sanne underliggende fordelingen. Standard bin-størrelsen bestemmes ved hjelp av en referanseregel som avhenger av prøvestørrelse og varians. Dette fungerer bra i mange tilfeller, (dvs.med» veloppdragen » data), men det mislykkes i andre. Det er alltid et godt å prøvedifferent bin størrelser for å være sikker på at du ikke mangler noe viktig.Denne funksjonen lar deg angi hyller på flere forskjellige måter, for eksempel ved å angi totalt antall hyller som skal brukes, bredden på hver hylle eller bestemte steder der hyllene skal bryte.
Eksempler
Tilordne en variabel tilx for å plotte en univariat fordeling langs x-aksen:
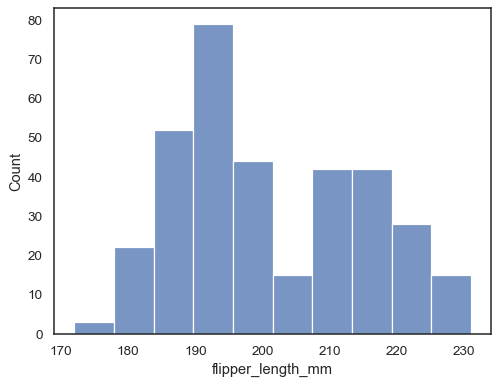
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
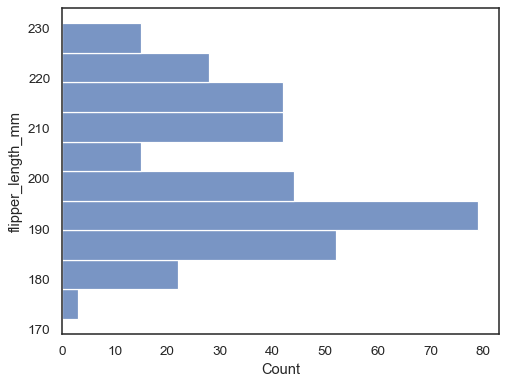
Vend plottet ved å tilordne datavariabelen til y-aksen:
sns.histplot(data=penguins, y="flipper_length_mm")
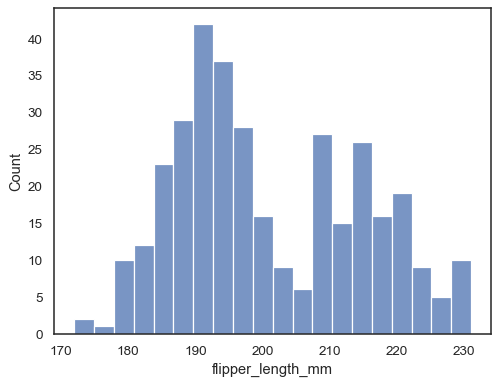
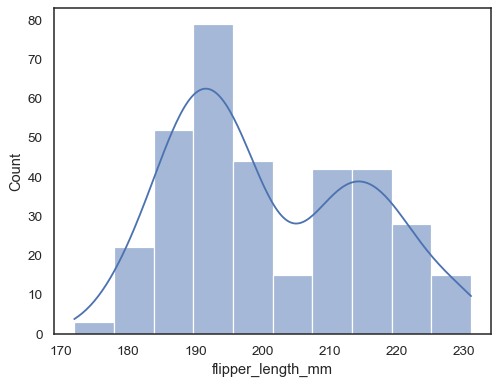
Kontroller hvor godt histogrammet representerer dataene ved å angi adifferent bin bredde:
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
du kan også definere totalt antall hyller som skal brukes:
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
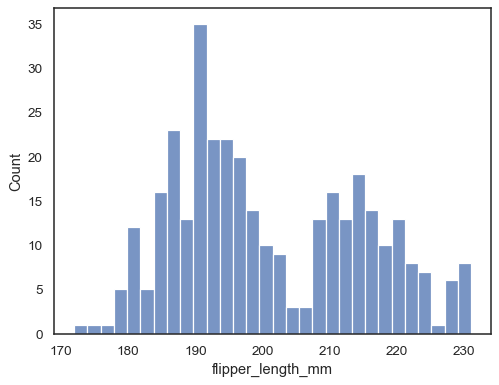
Legg til et kjernetetthetsestimat for å jevne ut histogrammet, og gi utfyllende informasjon om formen på fordelingen:
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
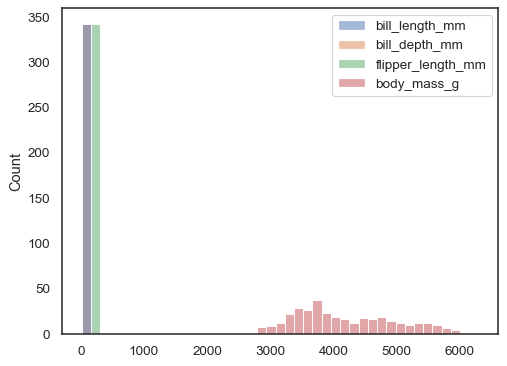
hvis ingen av delene x eller y behandles sombred form, og et histogram tegnes for hver numeriske kolonne:
sns.histplot(data=penguins)
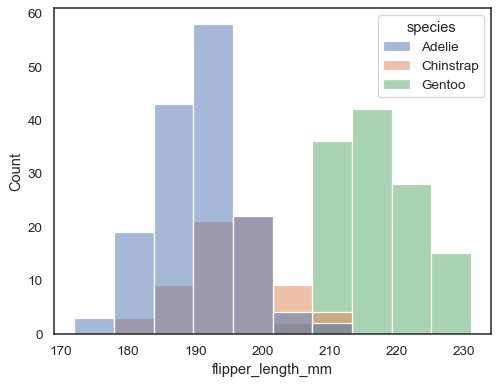
du kan ellers tegne flere histogrammer fra et datasett med lang form medhue-tilordning:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
standard tilnærming til å plotte flere distribusjoner er å «lag»dem, men du kan også «stable» dem:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
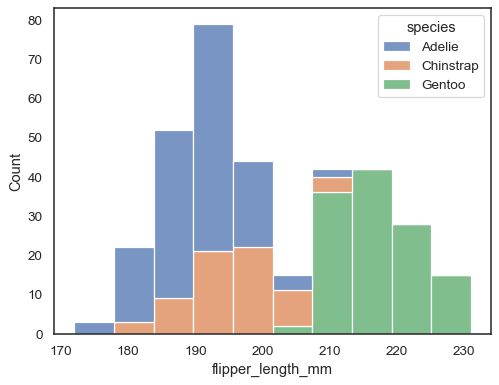
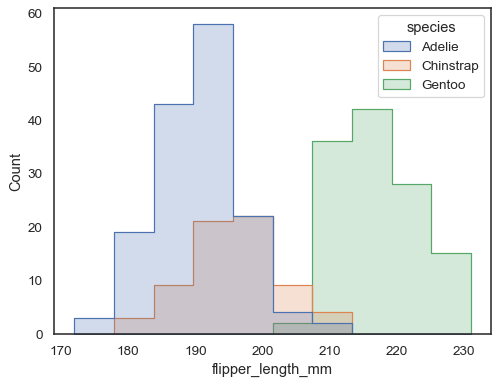
Overlappende stolper kan være vanskelig å visuelt løse. En annen tilnærming ville være å tegne en trinnfunksjon:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
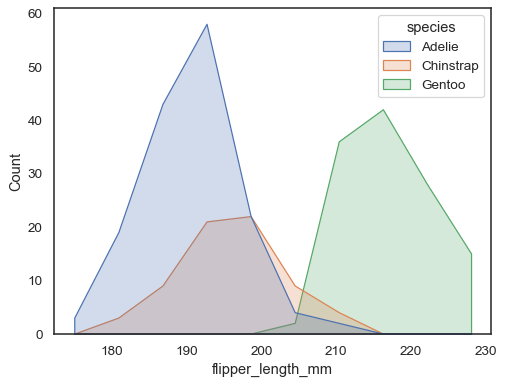
du kan flytte enda lenger bort fra stolpene ved å tegne et polygon medvertices i midten av hver bin. Dette kan gjøre det lettere å se distribusjonsformen, men bruk med forsiktighet: det vil være mindre åpenbart for publikum at de ser på et histogram:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
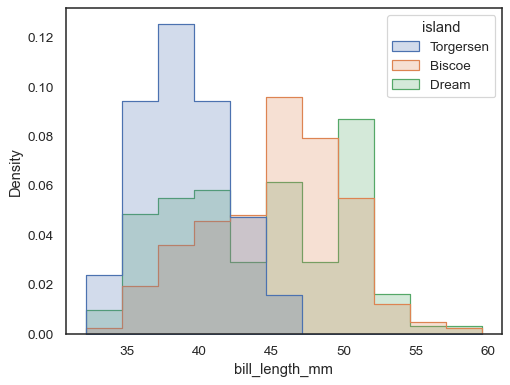
for å sammenligne fordelingen av delsett som avviker vesentlig insize, bruk uavhengig tetthet normalisering:
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
det er også mulig å normalisere slik at hver bar høyde viser aprobability, som gir mer mening for diskrete variabler:
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
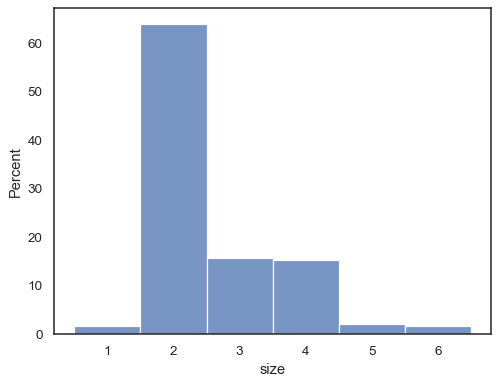
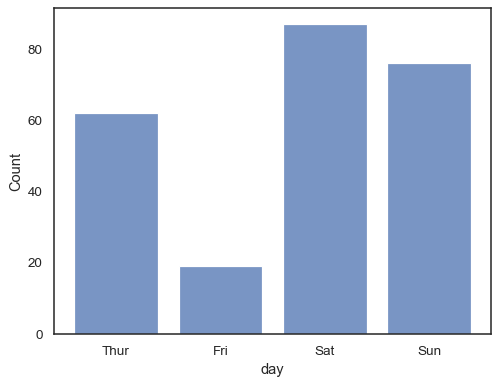
du kan til og med tegne et histogram over kategoriske variabler (selv om dette er en eksperimentell funksjon):
sns.histplot(data=tips, x="day", shrink=.8)
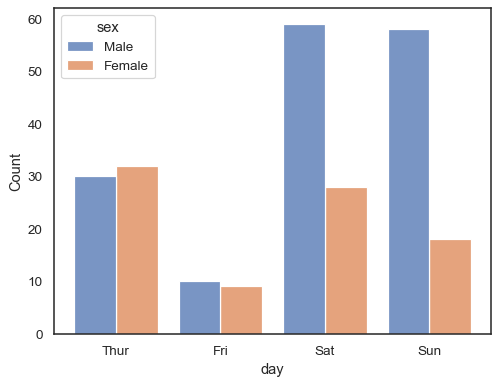
når du bruker enhue semantisk med diskrete data, kan det være fornuftig å»unnvike» nivåene:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
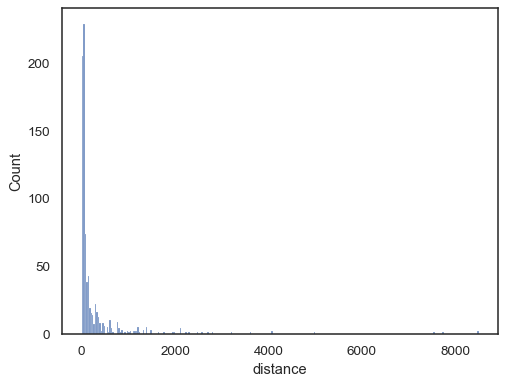
Virkelige data er ofte skjevt. For tungt skjevfordelinger er det bedre å definere hyllene i loggplass. Sammenligne:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
To the log-scale version:
sns.histplot(data=planets, x="distance", log_scale=True)
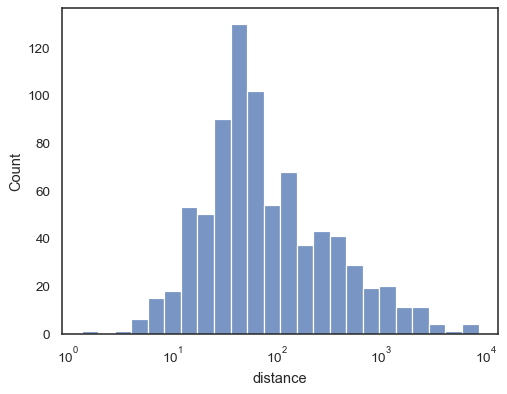
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
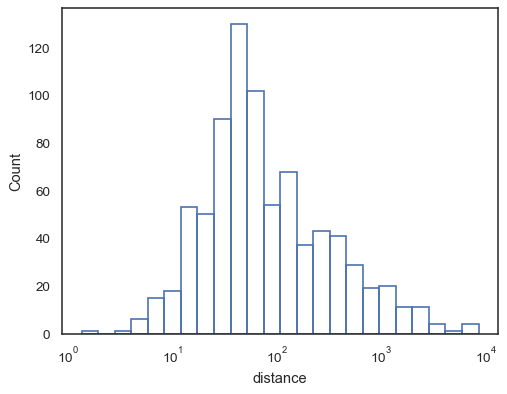
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
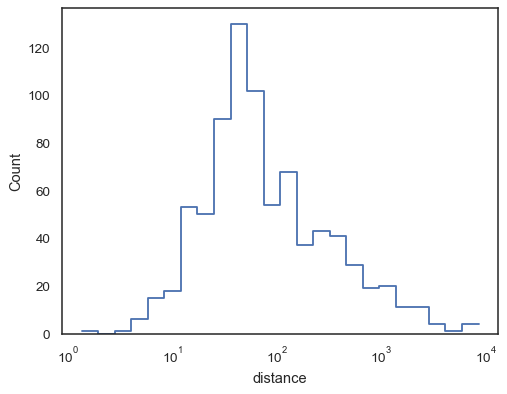
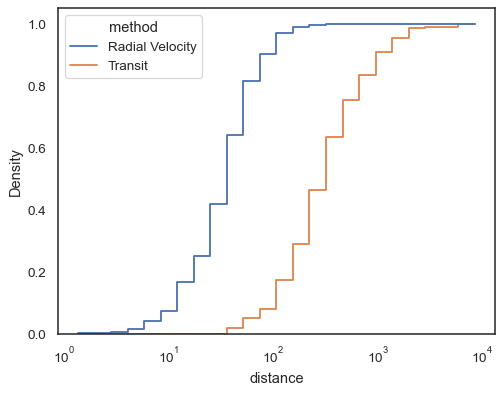
Trinnfunksjoner, spesielt når de ikke fylles ut, gjør det enkelt å sammenlignecumulative histogrammer:
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
når både x og y beregnes et bivariat histogram og vises som et varmekart:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
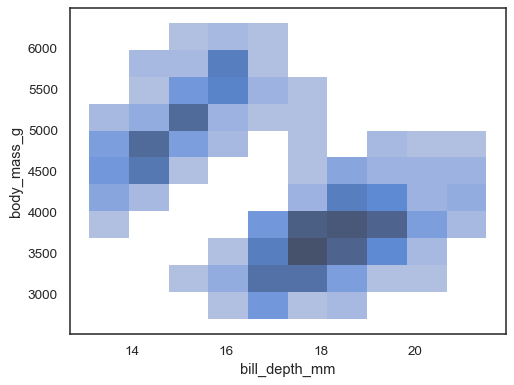
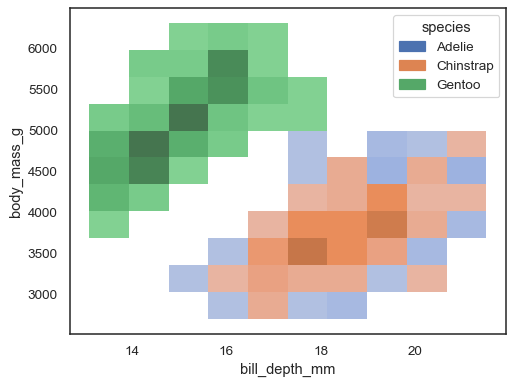
det er mulig å tilordne en hue variabel også, selv om dette ikke fungerer bra hvis data fra de forskjellige nivåene har betydelig overlapping:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
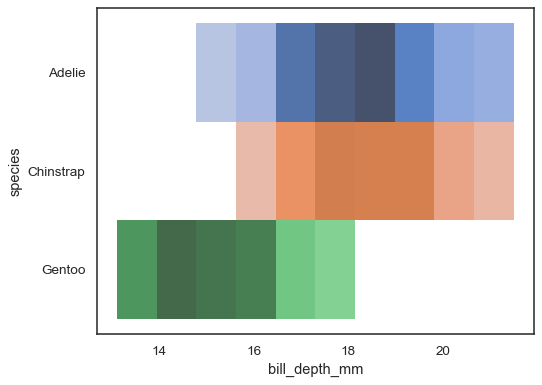
Flere fargekart kan gi mening når en av variablene er diskrete:
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
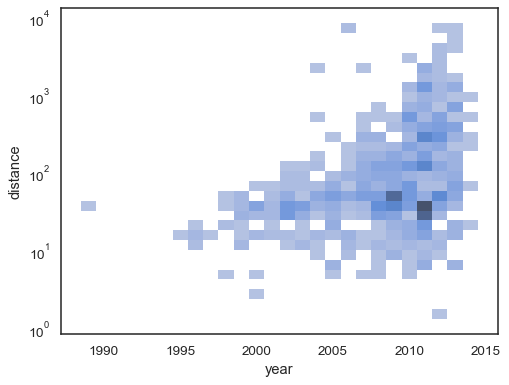
det bivariate histogrammet aksepterer alle de samme alternativene for beregningsom sin univariate motpart, bruker tuples til parametrize x ogy uavhengig:
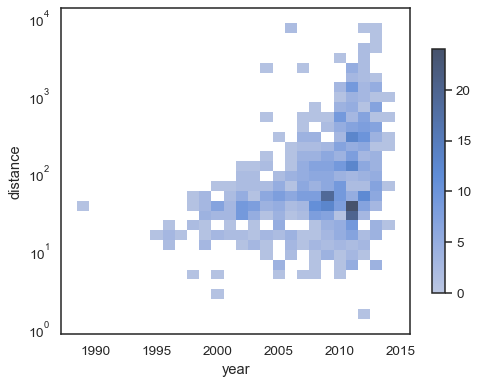
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
standard virkemåte gjør celler uten observasjoner gjennomsiktige,selv om dette kan deaktiveres:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
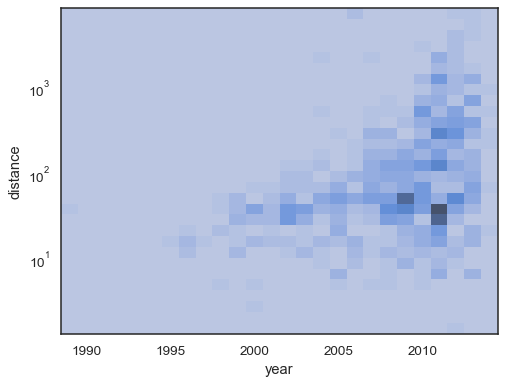
det er også mulig å sette terskelen og fargekartet metningspunkt interms av andelen av kumulative teller:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
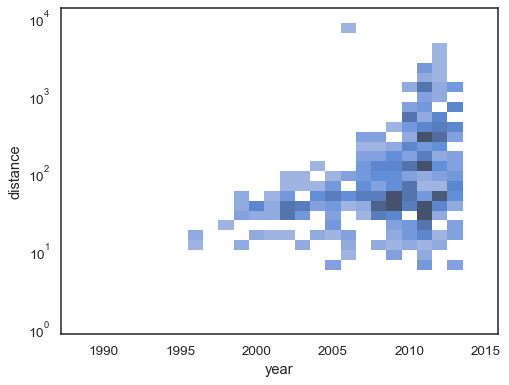
for å annotere fargekartet, legg til et fargefelt:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)