Slik gjør Du Semantisk Segmentering ved Hjelp Av Deep learning
denne artikkelen er en omfattende oversikt, inkludert en trinnvis veiledning for å implementere en deep learning image segmenteringsmodell.
vi delte en ny oppdatert blogg om Semantisk Segmentering her: En 2021 guide Til Semantisk Segmentering
I Dag er semantisk segmentering et av hovedproblemene innen datasyn. Når man ser på det store bildet, er semantisk segmentering en av oppgavene på høyt nivå som baner vei mot fullstendig sceneforståelse. Betydningen av sceneforståelse som et kjerneproblem for datasyn er fremhevet av det faktum at et økende antall applikasjoner nærer fra å utlede kunnskap fra bilder. Noen av disse programmene inkluderer selvkjørende biler, menneske-datamaskin interaksjon, virtuell virkelighet etc. Med populariteten til dyp læring de siste årene, blir mange semantiske segmenteringsproblemer håndtert ved hjelp av dype arkitekturer, oftest Innviklede Nevrale Nett, som overgår andre tilnærminger med stor margin når det gjelder nøyaktighet og effektivitet.
- Hva Er Semantisk Segmentering?
- Hva er eksisterende semantisk segmentering tilnærminger?
- 1-Regionbasert Semantisk Segmentering
- 2 – Fullt Convolutional Nettverksbasert Semantisk Segmentering
- 3 — Svakt Overvåket Semantisk Segmentering
- Gjør Semantisk Segmentering Med Full-Convolutional Network
- trinn 1
- Trinn 2
- Trinn 3
- Trinn 4
- Trinn 5
- DU kan være interessert i våre siste innlegg på:
Hva Er Semantisk Segmentering?
Semantisk segmentering er et naturlig skritt i progresjonen fra grov til fin slutning: opprinnelsen kan være lokalisert ved klassifisering, som består i å lage en prediksjon for en hel inngang.Det neste trinnet er lokalisering / deteksjon, som ikke bare gir klassene, men også tilleggsinformasjon om den romlige plasseringen av disse klassene.Endelig oppnår semantisk segmentering finkornet slutning ved å lage tette spådommer som utleder etiketter for hver piksel, slik at hver piksel er merket med klassen av sin omsluttende objektmalmregion.
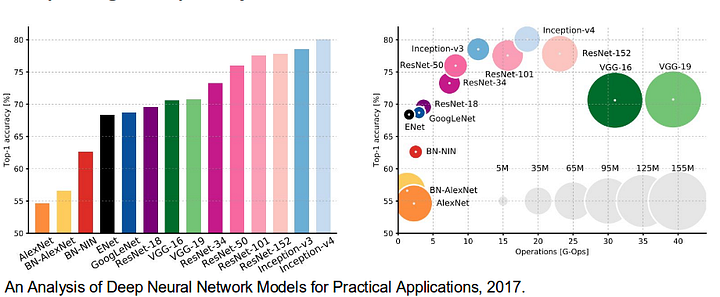
det er også verdig å gjennomgå noen standard dype nettverk som har gjort betydelige bidrag til feltet av datasyn, da de ofte brukes som grunnlag for semantiske segmenteringssystemer: alexnet: torontos banebrytende dype cnn som vant 2012 Imagenet-konkurransen med en testnøyaktighet på 84,6%. Den består av 5 convolutional lag, max-pooling seg, ReLUs som ikke-lineariteter, 3 fullt convolutional lag, og dropout.
Hva er eksisterende semantisk segmentering tilnærminger?
en generell semantisk segmenteringsarkitektur kan i stor grad betraktes som et kodernettverk etterfulgt av et dekodernettverk:
- koderen er vanligvis et pre-trent klassifiseringsnettverk som VGG/ResNet etterfulgt av et dekodernettverk.oppgaven til dekoderen er å semantisk projisere diskriminerende funksjoner (lavere oppløsning) lært av koderen på pikselrommet (høyere oppløsning) for å få en tett klassifisering.I Motsetning til klassifisering hvor sluttresultatet av det svært dype nettverket er det eneste viktige, krever semantisk segmentering ikke bare diskriminering på pikselnivå, men også en mekanisme for å projisere de diskriminerende funksjonene som læres på forskjellige stadier av koderen på pikselrommet. Ulike tilnærminger benytter forskjellige mekanismer som en del av dekodingsmekanismen. La oss utforske de 3 viktigste tilnærmingene:
1-Regionbasert Semantisk Segmentering
de regionbaserte metodene følger vanligvis» segmentering ved hjelp av anerkjennelse » – rørledningen, som først trekker ut friformregioner fra et bilde og beskriver dem, etterfulgt av regionbasert klassifisering. På testtidspunktet forvandles de regionbaserte prognosene til pikselprognoser, vanligvis ved å merke en piksel i henhold til den høyeste scoring-regionen som inneholder den.
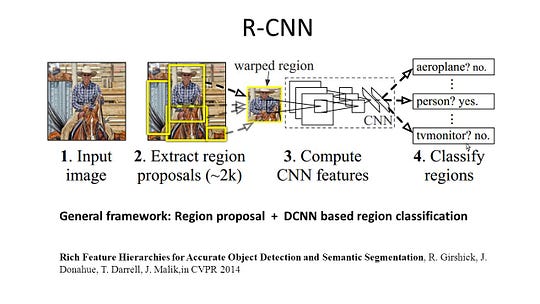
R-CNN Architecture R-Cnn (Regioner MED cnn-funksjon) er et representativt arbeid for de regionbaserte metodene. Den utfører semantisk segmentering basert på objektdeteksjonsresultatene. FOR å være spesifikk, BRUKER R-CNN først selektiv søk for å trekke ut en stor mengde objektforslag og beregner DERETTER CNN-funksjoner for hver av dem. Til slutt klassifiserer den hver region ved hjelp av klassespesifikke lineære Svm-er. Sammenlignet med tradisjonelle cnn-strukturer som hovedsakelig er ment for bildeklassifisering, KAN R-CNN løse mer kompliserte oppgaver, for eksempel objektdeteksjon og bildesegmentering, og det blir til og med et viktig grunnlag for begge feltene. Videre KAN R-CNN bygges på toppen AV NOEN cnn benchmark strukturer, Slik Som AlexNet, VGG, GoogLeNet, Og ResNet.
FOR bildesegmenteringsoppgaven hentet R-CNN ut 2 typer funksjoner for hver region: full region-funksjon og forgrunnsfunksjon, og fant ut at det kunne føre til bedre ytelse når de sammenkobles som region-funksjonen. R-CNN oppnådde betydelige ytelsesforbedringer på grunn av bruk av de svært diskriminerende cnn-funksjonene. Men det lider også av et par ulemper for segmenteringsoppgaven:
- funksjonen er ikke kompatibel med segmenteringsoppgaven.
- funksjonen inneholder ikke nok romlig informasjon for presis grensegenerering.
- Generering av segmentbaserte forslag tar tid og vil i stor grad påvirke den endelige ytelsen.På grunn av disse flaskehalsene har nyere forskning blitt foreslått for å løse problemene, inkludert SDS, Hypercolumns, Mask R-CNN.
2 – Fullt Convolutional Nettverksbasert Semantisk Segmentering
det opprinnelige Fullt Convolutional Network (FCN) lærer en kartlegging fra piksler til piksler, uten å trekke ut regionsforslagene. FCN network pipeline er en forlengelse av den klassiske CNN. Hovedideen er å gjøre den klassiske CNN ta som input vilkårlig størrelse bilder. Begrensningen Av CNNs for å akseptere og produsere etiketter bare for bestemte størrelsesinnganger kommer fra de fullt tilkoblede lagene som er faste. I motsetning til dem har Fcner bare convolutional og pooling lag som gir dem muligheten til å gjøre spådommer på vilkårlig størrelse innganger.
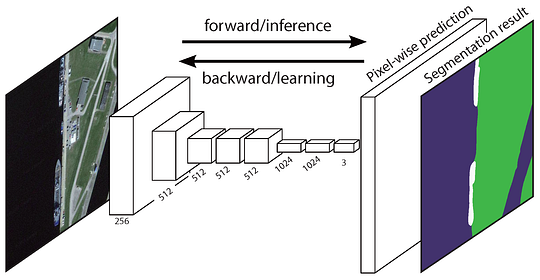
FCN Arkitektur Ett problem i denne SPESIFIKKE FCN er at ved å spre gjennom flere vekslet convolutional og pooling lag, oppløsningen av utdatafunksjonskartene er nede samplet. Derfor er de direkte spådommene TIL FCN vanligvis i lav oppløsning, noe som resulterer i relativt fuzzy objektgrenser. En rekke mer avanserte FCN – baserte tilnærminger har blitt foreslått for å løse dette problemet, inkludert SegNet, DeepLab-CRF og Utvidede Konvolutter.
3 — Svakt Overvåket Semantisk Segmentering
De fleste av de relevante metodene i semantisk segmentering er avhengige av et stort antall bilder med pikselvise segmenteringsmasker. Men manuelt kommentere disse maskene er ganske tidkrevende, frustrerende og kommersielt dyrt. Derfor har noen svakt overvåkede metoder nylig blitt foreslått, som er dedikert til å oppfylle den semantiske segmenteringen ved å benytte annoterte avgrensningsbokser.

Boxsup Training For eksempel Brukte Boxsup markeringsboksannotasjonene som et tilsyn for å trene nettverket og iterativt forbedre estimerte masker for semantisk segmentering. Simple does It behandlet svak tilsyn begrensning som en sak av input label støy og utforsket rekursiv trening som en de-noising strategi. Merking på pikselnivå tolket segmenteringsoppgaven i læringsrammen for flere forekomster og la til et ekstra lag for å begrense modellen til å tildele mer vekt til viktige piksler for bildenivå klassifisering.
Gjør Semantisk Segmentering Med Full-Convolutional Network
i denne delen, La oss gå gjennom en trinnvis implementering av den mest populære arkitekturen for semantisk Segmentering-Full-Convolutional Net (FCN). Vi implementerer det ved Hjelp Av tensorflow-biblioteket I Python 3, sammen med andre avhengigheter som Numpy og Scipy.In denne ovelsen vil vi merke pikslene til en vei i bilder ved HJELP AV FCN. Vi vil jobbe Med Kitti Road Datasett for vei / kjørefelt deteksjon. Dette er en enkel øvelse Fra Udacity ‘ S Self-Driving Car Nano-degree program, som du kan lære mer om oppsettet i Denne GitHub repo.

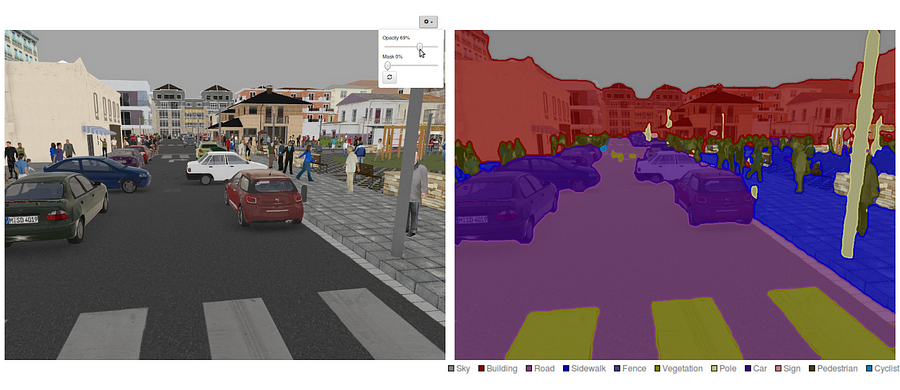
Kitti Road Datasett Treningseksempel (Kilde: http://www.cvlibs.net/datasets/kitti/eval_road_detail.php?result=3748e213cf8e0100b7a26198114b3cdc7caa3aff) her er de viktigste funksjonene i fcn arkitektur:
- fcn overfører kunnskap fra vgg16 å utføre semantisk segmentering.
- de fullt tilkoblede lagene AV VGG16 konverteres til fullt innviklede lag, ved hjelp av 1×1-innvikling. Denne prosessen gir en klasse tilstedeværelse varmekart i lav oppløsning.
- samplingen av disse semantiske funksjonskartene med lav oppløsning gjøres ved hjelp av transponerte konvolutter (initialisert med bilinære interpoleringsfiltre).
- på hvert trinn blir oppsamplingsprosessen ytterligere forbedret ved å legge til funksjoner fra grovere, men høyere oppløsningsfunksjonskart fra lavere lag I VGG16.
- Hopp over tilkobling blir introdusert etter hver konvolusjonsblokk for å aktivere den påfølgende blokken for å trekke ut mer abstrakte, klasseviktige funksjoner fra de tidligere sammenslåtte funksjonene.
Det er 3 versjoner AV FCN (FCN-32, FCN-16, FCN-8). VI implementerer FCN-8, som detaljert trinn for trinn nedenfor:
- Encoder: en pre-trent VGG16 brukes som en koder. Dekoderen starter fra Lag 7 AV VGG16.
- FCN Layer-8: det siste fullt tilkoblede laget AV VGG16 er erstattet av en 1×1-konvolusjon.
- FCN Lag-9: FCN Layer-8 er upsampled 2 ganger for å matche dimensjoner med Lag 4 AV VGG 16, ved hjelp av transponert konvolusjon med parametere: (kernel=(4,4), stride=(2,2), paddding=’same’). Etter det ble en skip-tilkobling lagt til Mellom Lag 4 AV VGG16 og FCN Layer-9.
- FCN Layer-10: FCN Layer-9 er samplet 2 ganger for å matche dimensjoner Med Lag 3 AV VGG16, ved hjelp av transponert konvolusjon med parametere: (kernel=(4,4), stride=(2,2), paddding= ‘same’). Etter det ble en hoppeforbindelse tilsatt Mellom Lag 3 AV VGG 16 og FCN Layer-10.
- FCN Lag-11: FCN Layer-10 er upsampled 4 ganger for å matche dimensjoner med inngangsbildestørrelse, slik at vi får det faktiske bildet tilbake og dybden er lik antall klasser, ved hjelp av transponert konvolusjon med parametere: (kernel=(16,16), stride=(8,8), paddding=’same’).
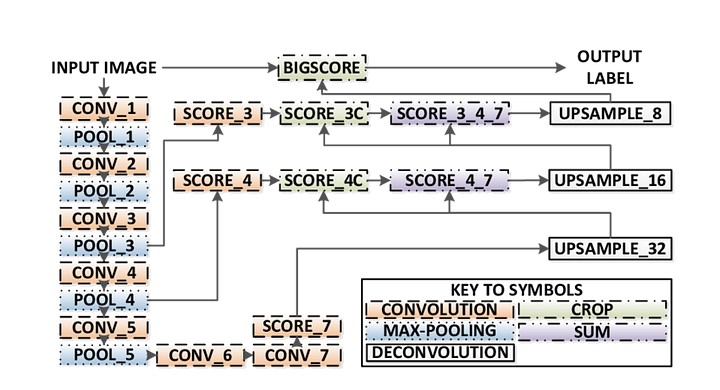
FCN-8 Arkitektur (Kilde: https://www.researchgate.net/figure/Illustration-of-the-FCN-8s-network-architecture-as-proposed-in-20-In-our-method-the_fig1_305770331) trinn 1
vi laster først den pre-trente vgg-16-modellen inn i tensorflow. Når Vi tar i tensorflow-økten og banen TIL Vgg-Mappen (som kan lastes ned her), returnerer vi tuple av tensorer FRA VGG-modellen, inkludert bildeinngangen, keep_prob (for å kontrollere dropout rate), layer 3, layer 4 og layer 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7vgg16 funksjon
Trinn 2
nå fokuserer vi på å lage lagene for EN FCN, ved hjelp av tensorene FRA VGG-modellen. Gitt tensorene FOR vgg-lagutgang og antall klasser å klassifisere, returnerer vi tensoren for det siste laget av den utgangen. Spesielt bruker vi en 1×1-konvolusjon til koderlagene, og legger deretter dekoderlag til nettverket med hopp over tilkoblinger og oppsampling.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11Lag funksjon
Trinn 3
det neste trinnet er å optimalisere våre nevrale nettverk, aka bygge TensorFlow tap funksjoner og optimizer operasjoner. Her bruker vi kryss entropi som vår tapsfunksjon og Adam som vår optimaliseringsalgoritme.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opOptimaliser funksjon
Trinn 4
her definerer vi train_nn-funksjonen, som tar inn viktige parametere, inkludert antall epoker, batchstørrelse, tapsfunksjon, optimaliseringsoperasjon og plassholdere for inngangsbilder, etikettbilder, læringsfrekvens. For treningsprosessen setter vi også keep_probability til 0,5 og learning_rate til 0,001. For å holde oversikt over fremdriften, skriver vi også ut tapet under trening.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Trinn 5
Endelig er det På tide å trene nettet vårt! I denne run-funksjonen bygger vi først nettet vårt ved hjelp av load_vgg, layers og optimize-funksjonen. Deretter trener vi nettet ved hjelp av train_nn-funksjonen og lagrer slutningsdataene for poster.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)Kjør funksjon
Om våre parametere velger vi epoker = 40, batch_size = 16, num_classes = 2 og image_shape = (160, 576). Etter å ha gjort 2 prøvepass med dropout = 0,5 og dropout = 0,75, fant vi ut at 2. prøve gir bedre resultater med bedre gjennomsnittlige tap.

Treningseksempler for å se hele koden, sjekk ut denne linken: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
hvis du likte dette stykket, ville jeg elske det dele det 👏 og spre kunnskapen.
DU kan være interessert i våre siste innlegg på:
- AWS Textract
- Data Extraction
Begynn å bruke Nanonets For Automatisering
Prøv modellen eller be om en demo i dag!
PRØV nå
