T-Testen
t-testen vurderer om midlene til to grupper er statistisk forskjellige fra hverandre. Denne analysen er hensiktsmessig når du vil sammenligne middelene til to grupper, og spesielt hensiktsmessig som analysen for posttest-bare to-gruppe randomisert eksperimentell design.
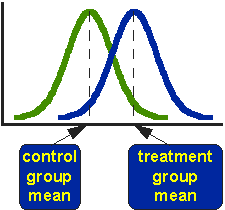
Figur 1. Idealiserte fordelinger for behandlede og sammenligningsgruppens posttestverdier.
Figur 1 viser fordelingene for de behandlede (blå) og kontrollgruppene (grønne) i en studie. Faktisk viser figuren den idealiserte fordelingen – den faktiske fordelingen vil vanligvis bli avbildet med et histogram eller stolpediagram. Figuren indikerer hvor kontroll – og behandlingsgruppens midler er plassert. Spørsmålet t-test adressene er om midlene er statistisk forskjellige.
hva betyr det å si at gjennomsnittene for to grupper er statistisk forskjellige? Vurder de tre situasjonene som er vist i Figur 2. Det første du må legge merke til om de tre situasjonene er at forskjellen mellom midlene er den samme i alle tre. Men du bør også legge merke til at de tre situasjonene ikke ser like ut – de forteller svært forskjellige historier. Toppeksemplet viser en kasus med moderat variasjon av skår innenfor hver gruppe. Den andre situasjonen viser den høye variabiliteten. den tredje viser tilfellet med lav variabilitet. Klart vil vi konkludere med at de to gruppene virker mest forskjellige eller distinkte i bunn-eller lavvariabilitetssaken. Hvorfor? Fordi det er relativt lite overlapping mellom de to klokkeformede kurver. I tilfelle av høy variabilitet synes gruppeforskjellen minst slående fordi de to klokkeformede fordelingene overlapper så mye.
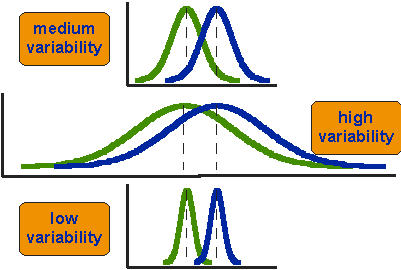
Figur 2. Tre scenarier for forskjeller mellom midler.Dette fører oss til en svært viktig konklusjon: når vi ser på forskjellene mellom score for to grupper, må vi dømme forskjellen mellom deres midler i forhold til spredningen eller variabiliteten av deres score. T-testen gjør nettopp dette.
Statistisk Analyse av t-testen
formelen for t-testen er et forhold. Den øverste delen av forholdet er bare forskjellen mellom de to middelene eller gjennomsnittene. Den nederste delen er et mål på variabiliteten eller dispersjonen av poengene. Denne formelen er i hovedsak et annet eksempel på signal-til-støy metafor i forskning: forskjellen mellom midlene er signalet som, i dette tilfellet, vi tror vårt program eller behandling innført i dataene; den nederste delen av formelen er et mål på variasjon som er i hovedsak støy som kan gjøre det vanskeligere å se gruppen forskjellen. Figur 3 viser formelen for t-testen og hvordan telleren og nevneren er relatert til fordelingene.
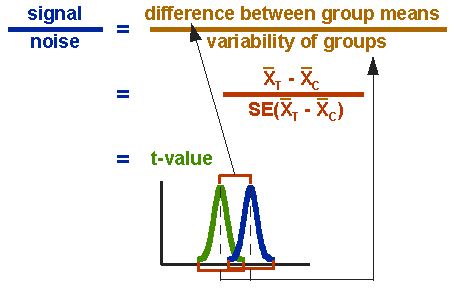
figur 3. Formel for t-testen.
den øverste delen av formelen er lett å beregne – bare finn forskjellen mellom midlene. Den nederste delen kalles standardfeilen til forskjellen. For å beregne det, tar vi variansen for hver gruppe og deler den med antall personer i den gruppen. Vi legger til disse to verdiene og tar deretter kvadratroten. Den spesifikke formelen for standardfeilen av forskjellen mellom midlene er:
$ $ \ textrm{SE} (\bar{X}_T – \bar{X}_c) = \sqrt {\frac {\textrm{var}_t}{n_T}+\frac {\textrm{var}_c}{n_C}}$$
Husk at variansen bare er kvadratet av standardavviket.
den endelige formelen for t-testen er:
$$t = \frac{\bar{X}_T-\bar{X}_c}{\sqrt{\frac{\textrm{var}_t}{n_T}+\frac{\textrm{var}_c}{n_C}}$$
t-verdien Vil Være Positiv hvis det første gjennomsnittet er større enn det andre og negativt hvis det er mindre. Når du har beregnet t-verdien, må du slå den opp i en tabell av betydning for å teste om forholdet er stort nok til å si at forskjellen mellom gruppene ikke sannsynligvis har vært en sjanse. For å teste betydningen må du sette et risikonivå (kalt alfa-nivået). I de fleste samfunnsforskning er «tommelfingerregelen» å sette alfa-nivået på .05. Dette betyr at fem ganger av hundre vil du finne en statistisk signifikant forskjell mellom midlene selv om det ikke var noen (dvs. ved «sjanse»). Du må også bestemme graden av frihet (df) for testen. I t-test er frihetsgraden summen av personene i begge gruppene minus 2. Gitt alfa-nivået, df ogt-verdien, kan du set-verdien opp i en standard tabell med signifikans (tilgjengelig som et tillegg på baksiden av de fleste statistikktekster) for å avgjøre omt-verdien er stor nok til å være signifikant. Hvis det er, kan du konkludere med at forskjellen mellom midlene for de to gruppene er forskjellig (selv gitt variabiliteten). Heldigvis, statistiske dataprogrammer rutinemessig skrive betydningen testresultater og spare deg bryet med å se dem opp i en tabell.
t-testen, enveisanalyse Av Varians (ANOVA) og en form for regresjonsanalyse er matematisk ekvivalente (se statistisk analyse av posttest-bare randomisert eksperimentell design) og vil gi identiske resultater.