drzewa regresji
wszystkie techniki regresji zawierają jedną zmienną wyjściową (odpowiedź) i jedną lub więcej zmiennych wejściowych (predyktor). Zmienna wyjściowa jest numeryczna. Ogólna metodologia budowania drzewa regresji pozwala zmiennym wejściowym być mieszaniną zmiennych ciągłych i kategorycznych. Drzewo decyzyjne jest generowane, gdy każdy węzeł decyzyjny w drzewie zawiera test na wartości zmiennej wejściowej. Węzły końcowe drzewa zawierają przewidywane wartości zmiennych wyjściowych.
drzewo regresji może być uważane za wariant drzew decyzyjnych, zaprojektowany w celu przybliżenia funkcji o wartości rzeczywistej, zamiast być używany do metod klasyfikacji.
Metodologia
drzewo regresji jest budowane przez proces znany jako binarne partycjonowanie rekurencyjne, który jest procesem iteracyjnym, który dzieli dane na partycje lub gałęzie, a następnie kontynuuje dzielenie każdej partycji na mniejsze grupy, gdy metoda przesuwa się w górę każdej gałęzi.
Początkowo wszystkie rekordy w zestawie treningowym (wstępnie sklasyfikowane rekordy, które są używane do określenia struktury drzewa) są zgrupowane w tej samej partycji. Algorytm następnie rozpoczyna przydzielanie danych do dwóch pierwszych partycji lub gałęzi, wykorzystując każdy możliwy podział binarny na każdym polu. Algorytm wybiera podział, który minimalizuje sumę kwadratowych odchyleń od średniej w dwóch oddzielnych partycjach. Ta reguła podziału jest następnie stosowana do każdej z nowych gałęzi. Proces ten trwa do momentu, gdy każdy węzeł osiągnie określony przez użytkownika minimalny rozmiar węzła i stanie się węzłem terminalowym. (Jeśli suma kwadratowych odchyleń od średniej w węźle wynosi zero, to węzeł ten jest uważany za węzeł końcowy, nawet jeśli nie osiągnął minimalnego rozmiaru.)
przycinanie drzewa
ponieważ drzewo wyrasta z zestawu treningowego, w pełni rozwinięte drzewo zwykle cierpi na nadmierne dopasowanie (tzn. wyjaśnia losowe elementy zestawu treningowego, które prawdopodobnie nie są cechami większej populacji). To nadmierne dopasowanie skutkuje słabą wydajnością rzeczywistych danych. Dlatego drzewo musi być przycinane za pomocą zestawu walidacyjnego. XLMiner oblicza współczynnik złożoności kosztów na każdym etapie wzrostu drzewa i decyduje o liczbie węzłów decyzyjnych w przyciętym drzewie. Współczynnik złożoności kosztów jest czynnikiem mnożnikowym, który jest stosowany do wielkości drzewa (mierzonej liczbą węzłów końcowych).
drzewo jest przycinane, aby zminimalizować sumę: 1) wariancji zmiennej wyjściowej w danych walidacyjnych, pobranych po jednym węźle terminalowym; oraz 2) iloczynu współczynnika złożoności kosztów i liczby węzłów terminalowych. Jeśli współczynnik złożoności kosztów jest określony jako zero, przycinanie to po prostu znalezienie drzewa, które najlepiej sprawdza się na danych walidacyjnych pod względem całkowitej wariancji węzła końcowego. Większe wartości współczynnika złożoności kosztów skutkują mniejszymi drzewami. Przycinanie odbywa się na zasadzie last-in first-out, co oznacza, że ostatni wyhodowany węzeł jest pierwszym, który podlega eliminacji.
metody Ensemble
XLMiner V2015 oferuje trzy potężne metody ensemble do użycia z drzewami regresji: bagging (agregowanie bootstrap), boosting i random trees. Algorytm drzewa regresji może być użyty do znalezienia jednego modelu, który daje dobre prognozy dla nowych danych. Możemy przeglądać statystyki i macierze splątania bieżącego predyktora, aby sprawdzić, czy nasz model dobrze pasuje do danych; ale skąd będziemy wiedzieć, czy istnieje lepszy predyktor, który tylko czeka na znalezienie? Odpowiedź jest taka, że nie wiemy, czy istnieje lepszy predyktor. Jednak metody ensemble pozwalają nam łączyć wiele słabych modeli drzewa regresji, które po połączeniu tworzą nowy, dokładny, silny model drzewa regresji. Metody te działają poprzez tworzenie wielu różnych modeli regresji, poprzez pobieranie różnych próbek oryginalnego zestawu danych, a następnie łączenie ich wyników. (Wyniki mogą być łączone za pomocą kilku technik, na przykład, większość głosów dla klasyfikacji i uśredniania dla regresji) ta kombinacja modeli skutecznie zmniejsza wariancję w silnym modelu. Trzy rodzaje metod zespołowych oferowanych w xlminer (bagging, boosting i random trees) różnią się w trzech elementach: 1) Wybór zestawu treningowego dla każdego predyktora lub słabego modelu; 2) sposób generowania słabych modeli; i 3) sposób łączenia wyników. We wszystkich trzech metodach każdy słaby model jest szkolony na całym zestawie treningowym, aby stać się biegłym w pewnej części zestawu danych.
Bagging (agregowanie bootstrap) był jednym z pierwszych algorytmów, jakie kiedykolwiek powstały. Jest to prosty algorytm, ale bardzo skuteczny. Bagging generuje kilka zestawów treningowych za pomocą Losowego próbkowania z wymianą (próbkowanie bootstrap), stosuje algorytm drzewa regresji do każdego zestawu danych, a następnie pobiera średnią spośród modeli, aby obliczyć prognozy dla nowych danych. Największą zaletą baggingu jest względna łatwość równoległości algorytmu, co czyni go lepszym wyborem dla bardzo dużych zbiorów danych.
Boosting buduje silny model, sukcesywnie trenując modele, aby skoncentrować się na rekordach otrzymujących niedokładne przewidywane wartości w poprzednich modelach. Po zakończeniu wszystkie predyktory są łączone za pomocą ważonej większości głosów. XLMiner oferuje trzy odmiany boostingu zaimplementowane przez algorytm AdaBoost (jeden z najpopularniejszych algorytmów w użyciu): M1 (Freund), M1 (Breiman) i SAMME (Stagewise Additive Modeling using a Multi-class Exponential).
Adaboost.M1 najpierw przypisuje wagę(wb (i)) każdemu zapisowi lub obserwacji. Ta waga jest pierwotnie ustawiona na 1 / n i będzie aktualizowana przy każdej iteracji algorytmu. Oryginalne drzewo regresji jest tworzone przy użyciu tego pierwszego zestawu treningowego (Tb) i błąd jest obliczany jako
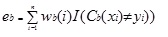
gdzie funkcja i () zwraca 1, jeśli prawda, a 0, jeśli nie.
błąd drzewa regresji w iteracji bth służy do obliczenia stałej ?b. Stała ta jest używana do aktualizacji wagi (wb (i). W AdaBoost.M1 (Freund), stała jest obliczana jako
ab= LN((1-eb)/eb)
w AdaBoost.M1 (Breiman), stała jest obliczana jako
ab= 1/2LN ((1-eb)/EB)
w SAMME stała jest obliczana jako
ab= 1/2LN ((1-EB)/EB + ln (k-1) gdzie k jest liczbą klas
gdzie liczba kategorii jest równa 2, SAMME zachowuje się tak samo jak Adaboost Breiman.
W dowolnej z trzech implementacji (Freund, Breiman lub SAMME), nowa waga dla iteracji (b + 1)będzie wynosić

następnie wagi są ponownie dostosowywane do sumy 1. W rezultacie wagi przypisane do obserwacji, którym przypisano niedokładne przewidywane wartości, są zwiększane, a wagi przypisane do obserwacji, którym przypisano dokładne przewidywane wartości, są zmniejszane. Ta regulacja zmusza następny model regresji, aby położyć większy nacisk na rekordy, którym przypisano niedokładne prognozy. (To ? stała jest również używana w ostatecznym obliczeniu, co da model regresji z NAJNIŻSZYM błędem większy wpływ.) Ten proces powtarza się aż do b = Liczba słabych uczniów. Algorytm następnie oblicza średnią ważoną wśród wszystkich słabych uczniów i przypisuje tę wartość do rekordu. Boosting ogólnie daje lepsze modele niż pakowanie; ma jednak wadę, ponieważ nie jest równoległy. W rezultacie, jeśli liczba słabych uczniów jest duża, boosting nie byłby odpowiedni.
metoda losowych drzew (random trees) jest odmianą workowania. Ta metoda działa poprzez szkolenie wielu słabych drzew regresji przy użyciu stałej liczby losowo wybranych funkcji (sqrt dla klasyfikacji i liczby funkcji/3 dla przewidywania), a następnie pobiera średnią wartość dla słabych uczniów i przypisuje tę wartość silnemu predyktorowi. Zazwyczaj liczba generowanych słabych drzew może wynosić od kilkuset do kilku tysięcy w zależności od wielkości i trudności zestawu treningowego. Losowe drzewa są równoległe, ponieważ są odmianą workowania. Ponieważ jednak drzewa tandomowe wybierają ograniczoną liczbę funkcji w każdej iteracji, wydajność losowych drzew jest szybsza niż pakowanie.
Regression Tree ensemble methods are very powerful methods, and usually result in better performance than a single tree. Ta funkcja dodawana w XLMiner V2015 zapewnia dokładniejsze modele predykcji i powinna być uwzględniona w metodzie pojedynczego drzewa.