rozwiązanie problemu uczenie się przez wzmacnianie za pomocą procesu decyzyjnego Markowa
Ten artykuł został opublikowany w ramach Blogathonu Data Science.
wprowadzenie
Reinforcement Learning (RL) to metodologia uczenia się, dzięki której uczeń uczy się zachowywać w interaktywnym środowisku, wykorzystując własne działania i nagrody za swoje działania. Uczeń, często nazywany agentem, odkrywa, które działania dają maksymalną nagrodę, wykorzystując je i eksplorując.

kluczowe pytanie brzmi – czym RL różni się od uczenia nadzorowanego i nienadzorowanego?
różnica tkwi w perspektywie interakcji. Nadzorowane uczenie mówi użytkownikowi / agentowi bezpośrednio, jakie działania musi wykonać, aby zmaksymalizować nagrodę, korzystając z zestawu danych szkoleniowych z oznaczonych przykładów. Z drugiej strony, RL bezpośrednio umożliwia agentowi korzystanie z nagród (pozytywnych i negatywnych) dostaje się do wyboru jego działania. Różni się więc od uczenia się bez nadzoru, ponieważ uczenie bez nadzoru polega na znajdowaniu struktury ukrytej w zbiorach nieoznakowanych danych.
formułowanie uczenia się przez wzmocnienie za pomocą procesu decyzyjnego Markowa (MDP)
podstawowe elementy problemu uczenia się przez wzmocnienie to:
- środowisko: świat zewnętrzny, z którym agent wchodzi w interakcje
- Stan: Aktualna sytuacja agenta
- Nagroda: numeryczny sygnał sprzężenia zwrotnego ze środowiska
- Polityka: metoda mapowania stanu agenta do działań. Zasada jest używana do wybierania akcji w danym stanie
- wartość: przyszła nagroda (opóźniona nagroda), którą agent otrzyma, podejmując akcję w danym stanie
proces decyzyjny Markowa (MDP) to matematyczna struktura opisująca środowisko w procesie uczenia się wzmacniającego. Poniższy rysunek pokazuje interakcję agent-środowisko w MDP:
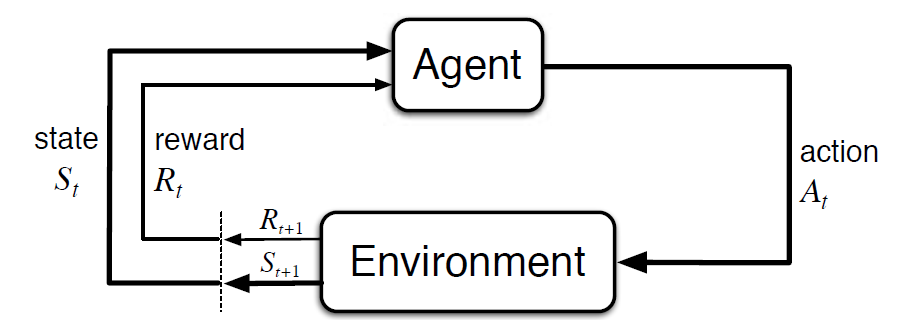
mówiąc dokładniej, agent i środowisko współdziałają na każdym dyskretnym kroku czasowym, t = 0, 1, 2, 3…At za każdym razem agent otrzymuje informacje o stanie środowiska St. Na podstawie stanu środowiska w momencie t, agent wybiera akcję At. W następnej chwili agent otrzymuje również numeryczny sygnał nagrody RT+1. Daje to zatem początek sekwencji takiej jak S0, A0, R1, S1, A1, R2…
zmienne losowe RT i St mają dobrze zdefiniowane dyskretne rozkłady prawdopodobieństwa. Te rozkłady prawdopodobieństwa są zależne tylko od stanu poprzedzającego i działania na mocy własności Markowa. Niech S, A i R będą zestawami Stanów, działań i nagród. Następnie prawdopodobieństwo, że wartości St, Rt i przy przyjmowaniu wartości s’, r I a z poprzednim stanem S jest podane przez,
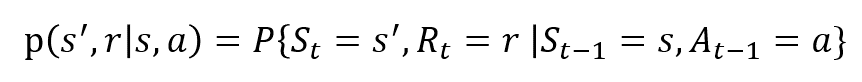
funkcja P kontroluje dynamikę procesu.
zrozummy to na przykładzie
omówmy teraz prosty przykład, w którym RL może być użyty do wdrożenia strategii sterowania dla procesu ogrzewania.
chodzi o to, aby kontrolować temperaturę w pomieszczeniu w określonych granicach temperatur. Na temperaturę wewnątrz pomieszczenia wpływają czynniki zewnętrzne, takie jak temperatura zewnętrzna, wytwarzane ciepło wewnętrzne itp.
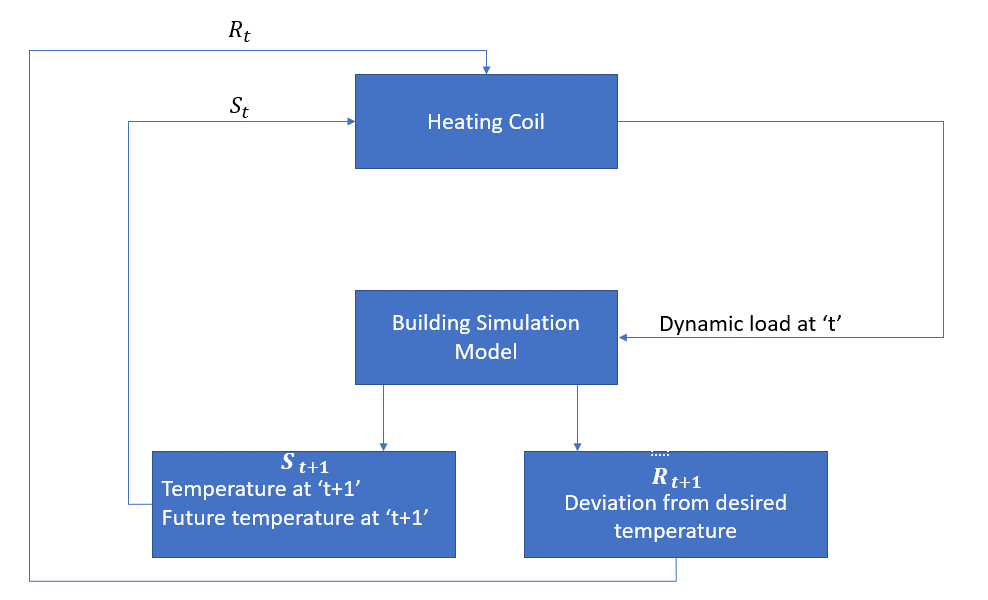
czynnikiem w tym przypadku jest cewka grzewcza, która musi decydować o ilości ciepła wymaganej do kontrolowania temperatury wewnątrz pomieszczenia poprzez interakcję z otoczeniem i zapewnić, że temperatura wewnątrz pomieszczenia mieści się w określonym zakresie. Nagrodą w tym przypadku jest w zasadzie koszt zapłacony za odchylenie od optymalnych limitów temperatury.
akcją dla agenta jest obciążenie dynamiczne. To dynamiczne obciążenie jest następnie podawane do symulatora pomieszczenia, który jest zasadniczo modelem wymiany ciepła, który oblicza temperaturę na podstawie obciążenia dynamicznego. W tym przypadku środowisko jest modelem symulacji. Zmienna stanowa St zawiera zarówno obecne, jak i przyszłe nagrody.
poniższy schemat blokowy wyjaśnia, w jaki sposób MDP może być używany do kontrolowania temperatury w pomieszczeniu:
ograniczenia tej metody
Uczenie Się zbrojenia uczy się od państwa. Państwo jest wkładem w kształtowanie polityki. W związku z tym dane wejściowe stanu powinny być poprawnie podane. Również jak widzieliśmy, istnieje wiele zmiennych i wymiarowość jest ogromna. Więc używanie go do rzeczywistych systemów fizycznych byłoby trudne!
Czytaj dalej
aby dowiedzieć się więcej o RL, pomocne mogą być następujące materiały:
- Reinforcement Learning: an Introduction by Richard.S. Sutton i Andrew.Przewodniczący: http://incompleteideas.net/book/the-book-2nd.html
- wykłady wideo Davida Silvera dostępne na YouTube
- https://gym.openai.com/ to zestaw narzędzi do dalszej eksploracji
możesz również przeczytać ten artykuł w naszej aplikacji mobilnej![]()
