as árvores de regressão
Todas as técnicas de regressão contêm uma única variável de saída (resposta) e uma ou mais variáveis de entrada (predictor). A variável de saída é numérica. A metodologia geral de regressão de construção de árvores permite que as variáveis de entrada sejam uma mistura de variáveis contínuas e categóricas. Uma árvore de decisão é gerada quando cada nó de decisão na árvore contém um teste sobre o valor de alguma variável de entrada. Os nós terminais da árvore contêm os valores das variáveis de saída previstas. uma árvore de regressão pode ser considerada como uma variante das árvores de decisão, projetada para aproximar funções de valor real, em vez de ser usada para métodos de classificação.
metodologia
uma árvore de regressão é construída através de um processo conhecido como particionamento recursivo binário, que é um processo iterativo que divide os dados em partições ou ramos, e então continua dividindo cada partição em grupos menores à medida que o método se move para cima de cada ramo.
inicialmente, todos os registros no conjunto de treinamento (registros pré-classificados que são usados para determinar a estrutura da árvore) são agrupados na mesma partição. O algoritmo então começa a alocar os dados nas duas primeiras partições ou ramificações, usando cada divisão binária possível em cada campo. O algoritmo seleciona a divisão que minimiza a soma dos desvios ao quadrado da média nas duas partições separadas. Esta regra de divisão é então aplicada a cada um dos novos ramos. Este processo continua até que cada nó atinja um tamanho mínimo de nó especificado pelo Usuário e se torne um nó terminal. (Se a soma dos desvios ao quadrado da média de um nó é zero, então esse nó é considerado um nó terminal mesmo que ele não tenha atingido o tamanho mínimo.)
a Poda da Árvore
uma vez que a árvore é cultivada a partir do Conjunto de Treinamento, totalmente desenvolvido árvore normalmente sofre de over-fitting (i.é, ele está explicando aleatória de elementos do Conjunto de Treinamento que não são susceptíveis de ser características da população). Este excesso de ajuste resulta em mau desempenho em dados da vida real. Por isso, a árvore deve ser podada utilizando o conjunto de validação. XLMiner calcula o Fator de complexidade de custo em cada etapa durante o crescimento da árvore e decide o número de nós de decisão na árvore podada. O Fator de complexidade de custo é o fator multiplicativo que é aplicado ao tamanho da árvore (medido pelo número de nós terminais).
A árvore é podada para minimizar a soma de: 1) a variância da variável de saída nos dados de validação, tomada de um nó terminal de cada vez; e 2) o produto do fator de complexidade de custo e o número de nós terminais. Se o Fator de complexidade de custo é especificado como zero, então a poda é simplesmente encontrar a árvore que tem melhor desempenho em dados de validação em termos de variância total do nó terminal. Valores maiores do fator de complexidade de custo resultam em árvores menores. A poda é realizada numa base de primeira saída, o que significa que o último nó cultivado é o primeiro a ser sujeito a eliminação.
Métodos de Conjunto
XLMiner V2015 oferece três poderosos métodos de conjunto para uso com árvores de regressão: ensacamento (agregação de bootstrap), reforço e árvores aleatórias. O algoritmo Da Árvore de regressão pode ser usado para encontrar um modelo que resulta em boas previsões para os novos dados. Podemos ver as matrizes estatísticas e confusão do predictor atual para ver se nosso modelo é um bom ajuste aos dados; mas como saberemos se há um predictor melhor apenas esperando para ser encontrado? A resposta é que não sabemos se existe um melhor preditor. No entanto, os métodos ensemble permitem combinar múltiplos modelos de árvore de regressão fraca, que quando tomados juntos formam um novo, preciso, forte modelo de árvore de regressão. Estes métodos funcionam criando múltiplos modelos de regressão diversificados, recolhendo diferentes amostras do conjunto de dados original e, em seguida, combinando as suas saídas. (As saídas podem ser combinadas por várias técnicas, por exemplo, votação maioritária para classificação e média para regressão) esta combinação de modelos efetivamente reduz a variância no modelo forte. Os três tipos de métodos de conjunto oferecidos em XLMiner (ensacamento, impulso e árvores aleatórias) diferem em três itens: 1) a seleção do conjunto de treinamento para cada predictor ou modelo fraco; 2) como os modelos fracos são gerados; e 3) como as saídas são combinadas. Em todos os três métodos, cada modelo fraco é treinado em todo o conjunto de treinamento para se tornar proficiente em alguma parte do conjunto de dados.
Bagging (aggregating bootstrap) foi um dos primeiros algoritmos ensemble a ser escrito. É um algoritmo simples, mas muito eficaz. Bagging gera vários conjuntos de treinamento usando amostragem aleatória com substituição( amostragem bootstrap), aplica o algoritmo árvore de regressão a cada conjunto de dados, em seguida, leva a média entre os modelos para calcular as previsões para os novos dados. A maior vantagem do bagging é a relativa facilidade que o algoritmo pode ser paralelizado, o que o torna uma melhor seleção para conjuntos de dados muito grandes.
Boosting constrói um modelo forte através da formação sucessiva de modelos para se concentrar em registros que recebem valores previstos imprecisos em modelos anteriores. Uma vez concluídos, todos os predictores são combinados por maioria ponderada. XLMiner oferece três variações de impulso conforme implementado pelo algoritmo AdaBoost (um dos algoritmos de conjunto mais populares em uso atualmente): M1 (Freund), M1 (Breiman), and SAMME (Stagewise Additive Modeling using a Multi-class Exponential). Adaboost.M1 primeiro atribui um peso (wb (i)) a cada registro ou observação. Este peso é originalmente definido como 1 / n, e será atualizado em cada iteração do algoritmo. É criada uma árvore de regressão original usando este primeiro conjunto de treino (Tb) e calcula-se um erro como
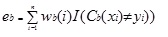
onde, a função I() devolve 1 Se for verdadeiro e 0 se não for.
o erro da árvore de regressão na iteração B é usado para calcular a constante ?b. Esta constante é usada para atualizar o peso (wb (i). Em AdaBoost.M1 (Freund), a constante é calculada como
ab= ln ((1-eb)/eb)
no AdaBoost.M1 (Breiman), a constante é calculada como:
ab= 1/2ln((1-eb)/eb)
Em SAMME, a constante é calculada como:
ab= 1/2ln((1-eb)/eb + ln(k-1), onde k é o número de classes
onde, o número de categorias é igual a 2, SAMME se comporta o mesmo que adaboost de aprendizagem de máquina Breiman.
Em qualquer uma das três implementações (Freund, Breiman, ou SAMME), o novo peso para a (b + 1)ésima iteração será

Depois, os pesos são todos reajustada para a soma de 1. Como resultado, os pesos atribuídos às observações que foram atribuídos imprecisas valores previstos são aumentados, e os pesos atribuídos às observações que foram atribuídos precisas valores previstos são diminuídos. Este ajuste força o modelo de regressão seguinte a colocar mais ênfase nos registros que foram atribuídos predições imprecisas. (Isto ? constante também é usada no cálculo final, o que dará maior influência ao modelo de regressão com o erro mais baixo.) Este processo repete-se até b = Número de alunos fracos. O algoritmo então calcula a média ponderada entre todos os aprendizes fracos e atribui esse valor ao registro. Boosting geralmente produz melhores modelos do que bagging; no entanto, ele tem uma desvantagem, uma vez que não é paralelizável. Como resultado, se o número de alunos fracos é grande, impulsionar não seria adequado. o método das árvores aleatórias (florestas aleatórias) é uma variação de ensacamento. Este método funciona treinando várias árvores de regressão fraca usando um número fixo de características aleatoriamente selecionadas (sqrt para classificação e número de características/3 para previsão), em seguida, toma o valor médio para os alunos fracos e atribui esse valor ao forte predictor. Normalmente, o número de árvores fracas geradas pode variar de várias centenas a vários milhares, dependendo do tamanho e dificuldade do conjunto de treinamento. Árvores aleatórias são paralelizáveis, uma vez que são uma variante de bagging. No entanto, uma vez que as árvores tandom selecionam uma quantidade limitada de recursos em cada iteração, o desempenho das árvores aleatórias é mais rápido do que ensacar.
os métodos de regressão de Conjuntos de árvores são métodos muito poderosos, e tipicamente resultam em melhor desempenho do que uma única árvore. Esta adição de recursos no XLMiner V2015 fornece modelos de previsão mais precisos, e deve ser considerada ao longo do método de árvore única.