Controlo da aprendizagem reforçada através do processo de decisão Markov
este artigo foi publicado como parte do blog Data Science Blogathon.
introdução
aprendizagem de reforço (RL) é uma metodologia de aprendizagem através da qual o aluno aprende a comportar-se num ambiente interactivo utilizando as suas próprias acções e recompensas pelas suas acções. O aprendiz, muitas vezes chamado de agente, descobre quais ações dão a máxima recompensa explorando-as e explorando-as.

uma questão chave é – como é RL diferente da aprendizagem supervisionada e não supervisionada?
a diferença vem na perspectiva da interação. Aprendizagem supervisionada diz ao usuário/agente diretamente que ação ele tem para realizar para maximizar a recompensa usando um conjunto de dados de treinamento de exemplos rotulados. Por outro lado, RL permite diretamente ao Agente fazer uso de recompensas (positivas e negativas) que ele começa a selecionar sua ação. É, portanto, diferente da aprendizagem não supervisionada também porque a aprendizagem não supervisionada é tudo sobre encontrar estrutura escondida em coleções de dados não rotulados.os elementos básicos de um problema de aprendizagem de reforço são:
- ambiente: o mundo exterior com o qual o agente interage
- Estado: Situação actual do agente
- recompensa: sinal numérico de feedback do ambiente
- Política: método para mapear o estado do agente às acções. Uma diretiva é usada para selecionar uma ação em um determinado estado
- Valor: recompensa Futura (atraso de recompensa) que um agente gostaria de receber por tomar uma ação em um determinado estado
o Processo de Decisão de Markov (MDP) é um modelo matemático para descrever um ambiente de aprendizado por reforço. A figura seguinte mostra a interacção agente-ambiente na PDD:
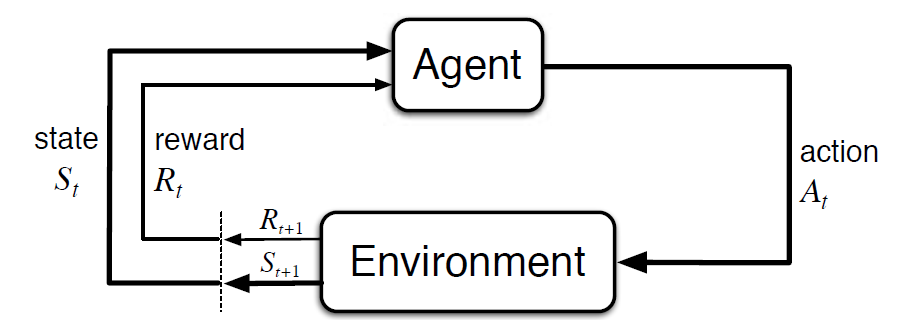
Mais especificamente, o agente e o ambiente interagem em cada passo de tempo discreto, t = 0, 1, 2, 3…Em cada passo de tempo, o agente obtém informações sobre o estado do ambiente São Baseados em o estado do ambiente no instante t, o agente escolhe uma ação A. No instante seguinte, o agente também recebe um sinal numérico de recompensa Rt+1. Isto dá origem a uma sequência como S0, A0, R1, S1, A1, R2…
as variáveis aleatórias Rt e St têm distribuições discretas de probabilidade bem definidas. Estas distribuições de probabilidade são dependentes apenas do estado anterior e ação em virtude da propriedade Markov. Vamos, A, E R ser os conjuntos de Estados, ações e recompensas. Então a probabilidade de que os valores de St, Rt e tomando valores de s’, r e com o estado anterior de s é dada por,
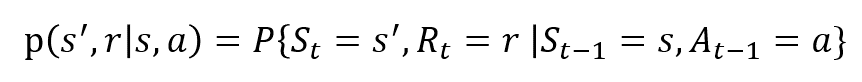
A função p controla a dinâmica do processo.
Vamos Entender isso Usando um Exemplo
Vamos agora discutir um exemplo simples onde RL pode ser usado para implementar uma estratégia de controle para um processo de aquecimento.
a ideia é controlar a temperatura de uma sala dentro dos limites de temperatura especificados. A temperatura dentro da sala é influenciada por fatores externos como a temperatura exterior, o calor interno gerado, etc.
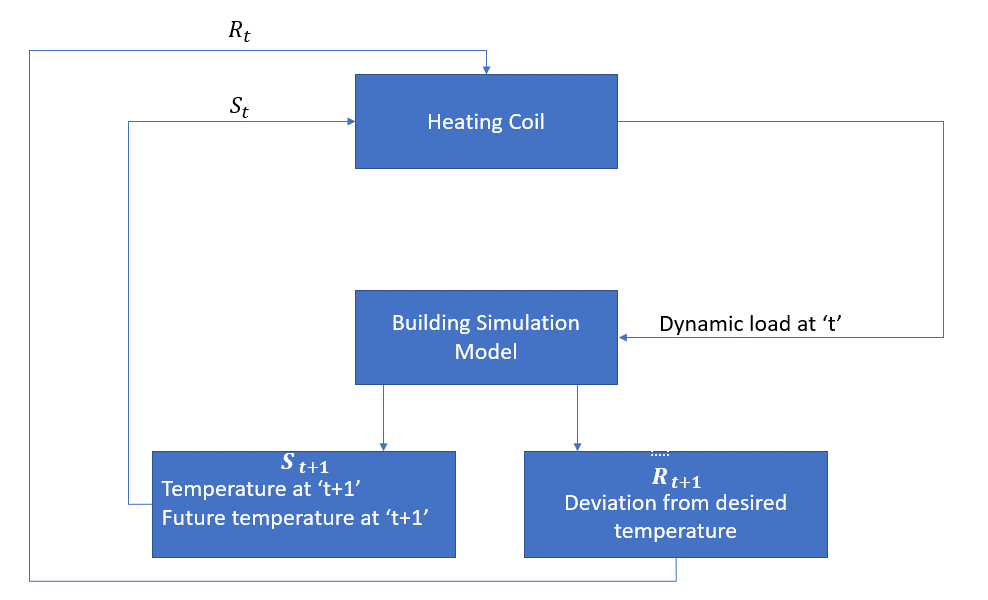
O agente, neste caso, é a bobina de aquecimento, que deve decidir a quantidade de calor necessária para controlar a temperatura dentro do quarto interagindo com o ambiente e assegurar que a temperatura no interior da sala está dentro da faixa especificada. A recompensa, neste caso, é basicamente o custo pago para se desviar dos limites de temperatura ideais.
a acção para o agente é a carga dinâmica. Esta carga dinâmica é então alimentada ao simulador de sala, que é basicamente um modelo de transferência de calor que calcula a temperatura com base na carga dinâmica. Então, neste caso, o ambiente é o modelo de simulação. A variável Estado St contém as recompensas presentes e futuras.
O seguinte diagrama de blocos explica como MDP pode ser utilizada para controlar a temperatura dentro de um quarto:
Limitações deste Método
Reforço de aprendizagem aprende com o estado. O estado é o contributo para a elaboração de políticas. Assim, os dados do Estado devem ser dados corretamente. Também como vimos, existem múltiplas variáveis e a dimensionalidade é enorme. Então usá-lo para sistemas físicos reais seria difícil!
Leitura Adicional
para saber mais sobre RL, os seguintes materiais podem ser úteis:
- aprendizagem de Reforço: Uma Introdução Por Richard.S. Sutton and Andrew.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- Aulas em Vídeo com o David Silver está disponível no YouTube
- https://gym.openai.com/ é um kit de ferramentas para uma maior exploração
Você também pode ler este artigo em nosso APLICATIVO Móvel ![]()
