Regressiebomen
alle regressietechnieken bevatten één output (response) variabele en één of meer input (predictor) variabelen. De output variabele is numeriek. De Algemene regressieboombouwmethodologie laat invoervariabelen toe om een mengsel van continue en categorische variabelen te zijn. Een beslissingsboom wordt gegenereerd wanneer elk beslissingsknooppunt in de boom een test bevat op de waarde van een bepaalde invoervariabele. De terminalknooppunten van de boomstructuur bevatten de voorspelde waarden van de uitvoervariabele.
een Regressieboom kan worden beschouwd als een variant van beslissingsbomen, ontworpen om reële functies te benaderen, in plaats van te worden gebruikt voor classificatiemethoden.
methodologie
een regressieboom wordt gebouwd door een proces dat bekend staat als binaire recursieve partitionering, wat een iteratief proces is dat de gegevens splitst in partities of branches, en vervolgens elke partitie verder splitst in kleinere groepen als de methode elke branch omhoog beweegt.
aanvankelijk worden alle records in de trainingsset (vooraf geclassificeerde records die worden gebruikt om de structuur van de boom te bepalen) gegroepeerd in dezelfde partitie. Het algoritme begint dan de toewijzing van de gegevens in de eerste twee partities of branches, met behulp van elke mogelijke binaire splitsing op elk veld. Het algoritme selecteert de splitsing die de som van de kwadraatafwijkingen van het gemiddelde in de twee afzonderlijke partities minimaliseert. Deze splitsingsregel wordt dan toegepast op elk van de nieuwe branches. Dit proces gaat door totdat elk knooppunt een door de gebruiker opgegeven minimum knooppuntgrootte bereikt en een terminalknooppunt wordt. (Als de som van kwadraatafwijkingen van het gemiddelde in een knoop nul is, dan wordt dat knooppunt beschouwd als een eindknooppunt, zelfs als het niet de minimumgrootte heeft bereikt.)
snoeien van de boom
aangezien de boom wordt gekweekt uit de trainingsset, lijdt een volledig ontwikkelde boom doorgaans aan over-fitting (dat wil zeggen, het verklaart willekeurige elementen van de trainingsset die waarschijnlijk geen kenmerken van de grotere populatie zijn). Dit over-fitting resulteert in slechte prestaties op real life data. Daarom moet de boom worden gesnoeid met behulp van de Validatieset. XLMiner berekent de kosten complexiteit factor bij elke stap tijdens de groei van de boom en bepaalt het aantal beslissingen knooppunten in de gesnoeide boom. De kostencomplexiteitsfactor is de multiplicatieve factor die wordt toegepast op de grootte van de boom (gemeten aan de hand van het aantal terminalknooppunten).
De boom wordt gesnoeid om de som te minimaliseren van: 1) de variantie van de uitvoervariabele in de validatiegegevens, genomen één terminalknooppunt per keer; en 2) het product van de kostencomplexiteitsfactor en het aantal terminalknooppunten. Als de kosten complexiteit factor is opgegeven als nul, dan snoeien is gewoon het vinden van de boom die het beste presteert op validatie gegevens in termen van totale terminal knooppunt variantie. Grotere waarden van de kostencomplexiteitsfactor resulteren in kleinere bomen. Snoeien wordt uitgevoerd op een last-in first-out basis, wat betekent dat de laatste gegroeid knooppunt is de eerste te worden onderworpen aan eliminatie.
Ensemble methoden
XLMiner V2015 biedt drie krachtige ensemble methoden voor gebruik met Regressiebomen: bagging( bootstrap aggregating), boosting, en willekeurige bomen. De Regressieboom algoritme kan worden gebruikt om een model dat resulteert in goede voorspellingen voor de nieuwe gegevens te vinden. We kunnen de statistieken en verwarmingsmatrices van de huidige voorspeller bekijken om te zien of ons model goed past bij de gegevens; maar hoe zouden we weten of er een betere voorspeller is die gewoon wacht om gevonden te worden? Het antwoord is dat we niet weten of er een betere voorspeller bestaat. Ensemble methoden stellen ons echter in staat om meerdere zwakke regressieboommodellen te combineren, die samen een nieuw, nauwkeurig, sterk regressieboommodel vormen. Deze methoden werken door het creëren van meerdere diverse regressiemodellen, door het nemen van verschillende monsters van de oorspronkelijke dataset, en vervolgens het combineren van hun outputs. (Outputs kunnen worden gecombineerd met verschillende technieken, bijvoorbeeld meerderheidsstemming voor classificatie en middeling voor regressie) deze combinatie van modellen vermindert effectief de variantie in het sterke model. De drie soorten ensemble methoden aangeboden in XLMiner (bagging, boosting, en willekeurige bomen) verschillen op drie items: 1) de selectie van de Training Set voor elke voorspeller of zwak model; 2) Hoe de zwakke modellen worden gegenereerd; en 3) Hoe de uitgangen worden gecombineerd. In alle drie methoden wordt elk zwak model getraind op de gehele trainingsset om bekwaam te worden in een deel van de dataset.
Bagging (bootstrap aggregating) was een van de eerste ensemble algoritmen ooit geschreven. Het is een eenvoudig algoritme, maar toch zeer effectief. Bagging genereert verschillende Trainingssets met behulp van willekeurige bemonstering met vervanging (bootstrap sampling), past het regressieboomalgoritme toe op elke gegevensset en neemt vervolgens het gemiddelde van de modellen om de voorspellingen voor de nieuwe gegevens te berekenen. Het grootste voordeel van bagging is het relatieve gemak dat het algoritme kan worden parallelliseerd, waardoor het een betere selectie voor zeer grote datasets.
Boosting bouwt een sterk model door opeenvolgende opleidingsmodellen om zich te concentreren op records die onjuiste voorspelde waarden in eerdere modellen ontvangen. Eenmaal voltooid, worden alle voorspellers gecombineerd met een gewogen meerderheid van stemmen. XLMiner biedt drie variaties van het stimuleren zoals geïmplementeerd door de AdaBoost algoritme (een van de meest populaire ensemble algoritmen in gebruik vandaag): M1 (Freund), M1 (Breiman), en SAMME (Stagewise Additive Modeling met behulp van een Multi-class Exponential).
Adaboost.M1 kent eerst een gewicht (wb (i)) toe aan elke record of waarneming. Dit gewicht is oorspronkelijk ingesteld op 1 / n, en zal worden bijgewerkt op elke iteratie van het algoritme. Een originele regressie boom wordt gemaakt met behulp van deze eerste Training Set (Tb) en een fout wordt berekend als
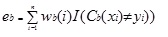
waarbij de functie I() 1 retourneert indien waar en 0 indien niet.
de fout van de regressieboom in de bth-iteratie wordt gebruikt om de constante te berekenen ?b. Deze constante wordt gebruikt om het gewicht (wb(i) bij te werken. In AdaBoost.M1 (Freund), wordt de constante berekend als
ab= ln((1-eb)/eb)
in AdaBoost.M1 (Breiman), wordt de constante berekend als
ab= 1/2ln((1-eb)/eb)
in SAMME wordt de constante berekend als
ab= 1/2ln((1-eb)/EB + ln(k-1) waarbij k het aantal klassen
is waarbij het aantal categorieën gelijk is aan 2, gedraagt SAMME zich hetzelfde als AdaBoost Breiman.
in een van de drie implementaties (Freund, Breiman, of SAMME)zal het nieuwe gewicht voor de (b + 1) de iteratie

daarna worden alle gewichten bijgesteld tot de som van 1. Als gevolg daarvan worden de gewichten toegekend aan de waarnemingen die werden toegewezen onnauwkeurige voorspelde waarden verhoogd, en de gewichten toegekend aan de waarnemingen die werden toegewezen nauwkeurige voorspelde waarden worden verlaagd. Deze aanpassing dwingt het volgende regressiemodel om meer nadruk te leggen op de records waaraan onjuiste voorspellingen zijn toegewezen. (Dit ? constant wordt ook gebruikt in de uiteindelijke berekening, die het regressiemodel met de laagste fout meer invloed zal geven.) Dit proces herhaalt zich tot b = Aantal zwakke leerlingen. Het algoritme berekent dan het gewogen gemiddelde van alle zwakke leerlingen en wijst die waarde toe aan het record. Boosting levert over het algemeen betere modellen op dan bagging; het heeft echter een nadeel omdat het niet parallelliseerbaar is. Als het aantal zwakke leerlingen groot is, zou boosting daarom niet geschikt zijn.
de methode voor willekeurige bomen (random forests) is een variatie op bagging. Deze methode werkt door het trainen van meerdere zwakke regressiebomen met behulp van een vast aantal willekeurig geselecteerde functies (sqrt voor classificatie en aantal functies/3 voor voorspelling), neemt dan de gemiddelde waarde voor de zwakke leerlingen en wijst die waarde toe aan de sterke voorspeller. Typisch, het aantal zwakke bomen gegenereerd kan variëren van enkele honderden tot enkele duizenden, afhankelijk van de grootte en de moeilijkheidsgraad van de training set. Willekeurige bomen zijn parallelliseerbaar, omdat ze een variant zijn van zakken. Echter, omdat tandom bomen selecteert een beperkt aantal functies in elke iteratie, de prestaties van willekeurige bomen is sneller dan bagging.
regressie boom Ensemble methoden zijn zeer krachtige methoden, en meestal resulteren in betere prestaties dan een enkele boom. Deze functie toevoeging in XLMiner V2015 biedt meer nauwkeurige voorspelling modellen, en moet worden overwogen over de single tree methode.