arbori de regresie
toate tehnicile de regresie conțin o singură variabilă de ieșire (răspuns) și una sau mai multe variabile de intrare (predictor). Variabila de ieșire este numerică. Metodologia generală de construire a arborelui de regresie permite variabilelor de intrare să fie un amestec de variabile continue și categorice. Un arbore de decizie este generat atunci când fiecare nod de decizie din arbore conține un test asupra valorii unei variabile de intrare. Nodurile terminale ale arborelui conțin valorile variabilei de ieșire prezise.
un arbore de regresie poate fi considerat ca o variantă a arborilor de decizie, conceput pentru a aproxima funcțiile cu valoare reală, în loc să fie utilizat pentru metode de clasificare.
metodologie
un arbore de regresie este construit printr-un proces cunoscut sub numele de partiționare binară recursivă, care este un proces iterativ care împarte datele în partiții sau ramuri și apoi continuă să împartă fiecare partiție în grupuri mai mici pe măsură ce metoda se deplasează în sus pe fiecare ramură.
inițial, toate înregistrările din setul de instruire (înregistrări pre-clasificate care sunt utilizate pentru a determina structura arborelui) sunt grupate în aceeași partiție. Algoritmul începe apoi alocarea datelor în primele două partiții sau ramuri, folosind fiecare împărțire binară posibilă pe fiecare câmp. Algoritmul Selectează împărțirea care minimizează suma abaterilor pătrate de la medie în cele două partiții separate. Această regulă de divizare este apoi aplicată fiecăreia dintre ramurile noi. Acest proces continuă până când fiecare nod atinge o dimensiune minimă a nodului specificată de utilizator și devine un nod terminal. (Dacă suma abaterilor pătrate de la media dintr-un nod este zero, atunci acel nod este considerat un nod terminal chiar dacă nu a atins dimensiunea minimă.)
tăierea copacului
deoarece arborele este crescut din setul de antrenament, un copac complet dezvoltat suferă de obicei de supra-montare (adică explică elemente aleatorii ale setului de antrenament care nu sunt susceptibile de a fi caracteristici ale populației mai mari). Acest lucru are ca rezultat o performanță slabă asupra datelor din viața reală. Prin urmare, arborele trebuie tăiat folosind setul de validare. XLMiner calculează factorul de complexitate a costurilor la fiecare pas în timpul creșterii arborelui și decide numărul de noduri de decizie din arborele tăiat. Factorul de complexitate a costurilor este factorul multiplicativ care se aplică dimensiunii arborelui (măsurat prin numărul de noduri terminale).
arborele este tăiat pentru a minimiza suma: 1) varianța variabilă de ieșire din datele de validare, luată câte un nod terminal la un moment dat; și 2) produsul factorului de complexitate a costurilor și numărul de noduri terminale. Dacă factorul de complexitate a costurilor este specificat ca zero, atunci tăierea este pur și simplu găsirea arborelui care funcționează cel mai bine pe datele de validare în ceea ce privește varianța totală a nodului terminal. Valorile mai mari ale factorului de complexitate a costurilor au ca rezultat copaci mai mici. Tunderea se efectuează pe o bază de ultimă intrare, ceea ce înseamnă că ultimul nod crescut este primul supus eliminării.
metode de ansamblu
XLMiner V2015 oferă trei metode de ansamblu puternice pentru utilizarea cu arbori de regresie: insacuire (Bootstrap agregare), stimularea, și copaci aleatoare. Algoritmul arborelui de regresie poate fi utilizat pentru a găsi un model care are ca rezultat predicții bune pentru noile date. Putem vizualiza statisticile și matricile de confuzie ale predictorului actual pentru a vedea dacă modelul nostru se potrivește bine datelor; dar cum am ști dacă există un predictor mai bun care așteaptă să fie găsit? Răspunsul este că nu știm dacă există un predictor mai bun. Cu toate acestea, metodele de ansamblu ne permit să combinăm mai multe modele de arbori de regresie slabi, care, luate împreună, formează un nou model de arbore de regresie puternic, precis și puternic. Aceste metode funcționează prin crearea mai multor modele de regresie diverse, prin prelevarea de eșantioane diferite ale setului de date original și apoi combinarea rezultatelor acestora. (Rezultatele pot fi combinate prin mai multe tehnici, de exemplu, votul majorității pentru clasificare și medierea pentru regresie) această combinație de modele reduce efectiv variația modelului puternic. Cele trei tipuri de metode de ansamblu oferite în XLMiner (insacuire, stimularea, și arbori aleatoare) diferă pe trei elemente: 1) Selectarea set de formare pentru fiecare predictor sau model slab; 2) modul în care sunt generate modelele slabe; și 3) modul în care ieșirile sunt combinate. În toate cele trei metode, fiecare model slab este instruit pe întregul set de formare pentru a deveni competenți în unele părți ale setului de date.Bagging (Bootstrap aggregating) a fost unul dintre primii algoritmi de ansamblu care a fost scris vreodată. Este un algoritm simplu, dar foarte eficient. Insacuire generează mai multe seturi de formare prin utilizarea eșantionare aleatorie cu înlocuire (eșantionare bootstrap), se aplică algoritmul copac de regresie pentru fiecare set de date, apoi ia media dintre modelele pentru a calcula previziunile pentru noile date. Cel mai mare avantaj al insacuire este ușurința relativă că algoritmul poate fi paralelizat, ceea ce face o selecție mai bună pentru seturi de date foarte mari.
Boosting construiește un model puternic prin instruirea succesivă a modelelor pentru a se concentra asupra înregistrărilor care primesc valori prezise inexacte în modelele anterioare. După finalizare, toți predictorii sunt combinați printr-un vot majoritar ponderat. XLMiner oferă trei variante de stimulare implementate de algoritmul AdaBoost (unul dintre cei mai populari algoritmi de ansamblu folosiți astăzi): M1 (Freund), M1 (Breiman) și SAMME (modelare aditivă în etape folosind o exponențială Multi-clasă).
Adaboost.M1 atribuie mai întâi o greutate (wb(i)) fiecărei înregistrări sau observații. Această greutate este setată inițial la 1 / n și va fi actualizată la fiecare iterație a algoritmului. Un arbore de regresie original este creat folosind acest prim set de antrenament (Tb) și o eroare este calculată ca
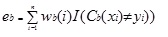
unde, funcția I () returnează 1 dacă este adevărat și 0 dacă nu.
eroarea arborelui de regresie în iterația bth este utilizată pentru a calcula Constanta ?b. Această constantă este utilizată pentru a actualiza greutatea(wb (i). În AdaBoost.M1 (Freund), Constanta este calculată ca
ab= Ln ((1-eb)/eb)
în AdaBoost.M1 (Breiman), Constanta este calculată ca
ab= 1/2LN ((1-eb)/eb)
în SAMME, Constanta este calculată ca
ab= 1/2LN ((1-eb)/eb + ln (k-1) unde k este numărul de clase
unde, numărul de categorii este egal cu 2, SAMME se comportă la fel ca AdaBoost Breiman.
în oricare dintre cele trei implementări (Freund, Breiman sau SAMME), Noua pondere pentru iterația (b + 1)va fi

după aceea, greutățile sunt toate reajustate la suma de 1. Ca urmare, ponderile atribuite observațiilor cărora li s-au atribuit valori prezise inexacte sunt crescute, iar ponderile atribuite observațiilor cărora li s-au atribuit valori prezise exacte sunt scăzute. Această ajustare forțează următorul model de regresie să pună mai mult accent pe înregistrările cărora li s-au atribuit predicții inexacte. (Asta ? Constanta este de asemenea utilizată în calculul final, ceea ce va da modelului de regresie cu cea mai mică eroare mai multă influență.) Acest proces se repetă până când b = Numărul de cursanți slabi. Algoritmul calculează apoi media ponderată între toți cursanții slabi și atribuie această valoare înregistrării. Stimularea produce, în general, modele mai bune decât ambalarea; cu toate acestea, are un dezavantaj, deoarece nu este paralelizabil. Ca urmare, dacă numărul elevilor slabi este mare, stimularea nu ar fi adecvată.
metoda random trees (păduri aleatorii) este o variație a insacuire. Această metodă funcționează prin antrenarea mai multor arbori de regresie slabi folosind un număr fix de caracteristici selectate aleatoriu (sqrt pentru clasificare și numărul de caracteristici/3 pentru predicție), apoi ia valoarea medie pentru cursanții slabi și atribuie acea valoare predictorului puternic. De obicei, numărul de copaci slabi generați ar putea varia de la câteva sute la câteva mii, în funcție de mărimea și dificultatea setului de antrenament. Copacii aleatorii sunt paralelizabili, deoarece sunt o variantă de ambalare. Cu toate acestea, deoarece copacii tandom Selectează o cantitate limitată de caracteristici în fiecare iterație, performanța copacilor aleatorii este mai rapidă decât ambalarea.
metodele ansamblului de arbori de regresie sunt metode foarte puternice și, de obicei, au ca rezultat o performanță mai bună decât un singur arbore. Această adăugare caracteristică în XLMiner V2015 oferă modele de predicție mai precise, și ar trebui să fie luate în considerare peste metoda singur copac.