Blog
într-o postare anterioară pe blog, am discutat despre modul în care supermarketurile folosesc datele pentru a înțelege mai bine nevoile consumatorilor și, în cele din urmă, pentru a-și crește cheltuielile globale. Una dintre tehnicile cheie utilizate de marii comercianți cu amănuntul se numește analiza coșului de piață (MBA), care descoperă asocieri între produse căutând combinații de produse care coexistă frecvent în tranzacții. Cu alte cuvinte, permite supermarketurilor să identifice relațiile dintre produsele pe care oamenii le cumpără. De exemplu, clienții care cumpără un creion și hârtie sunt susceptibili să cumpere un cauciuc sau o riglă.
„analiza coșului de piață permite comercianților cu amănuntul să identifice relațiile dintre produsele pe care oamenii le cumpără.”
comercianții cu amănuntul pot utiliza informațiile obținute din MBA în mai multe moduri, inclusiv:
- gruparea produselor care coexistă în proiectarea aspectului unui magazin pentru a crește șansa de vânzare încrucișată;
- conducerea motoarelor de recomandare online („clienții care au achiziționat acest produs au văzut și acest produs”); și
- direcționarea campaniilor de marketing prin trimiterea de cupoane promoționale către clienți pentru produsele legate de articolele pe care le-au achiziționat recent.
având în vedere cât de popular și valoros MBA este, ne-am gândit să producem următorul ghid pas cu pas care descrie modul în care funcționează și cum ai putea merge despre întreprinderea propria analiză coș de piață.
cum funcționează analiza coșului de piață?
pentru a efectua un MBA veți avea nevoie mai întâi de un set de date de tranzacții. Fiecare tranzacție reprezintă un grup de articole sau produse care au fost cumpărate împreună și adesea denumite „itemset”. De exemplu, un set de articole ar putea fi: {creion, hârtie, capse, cauciuc} caz în care toate aceste articole au fost cumpărate într-o singură tranzacție.într-un MBA, tranzacțiile sunt analizate pentru a identifica regulile de asociere. De exemplu, o regulă ar putea fi: {creion, hârtie} => {cauciuc}. Aceasta înseamnă că, dacă un client are o tranzacție care conține un creion și hârtie, atunci este probabil să fie interesat să cumpere și un cauciuc.
înainte de a acționa în conformitate cu o regulă, un comerciant cu amănuntul trebuie să știe dacă există suficiente dovezi care să sugereze că va avea un rezultat benefic. Prin urmare, măsurăm puterea unei reguli calculând următoarele trei valori (notă sunt disponibile și alte valori, dar acestea sunt cele mai utilizate trei):
suport: procentul de tranzacții care conțin toate elementele dintr-un set de elemente (de exemplu, creion, hârtie și cauciuc). Cu cât suportul este mai mare, cu atât mai frecvent apare itemset. Normele cu un sprijin ridicat sunt preferate, deoarece acestea sunt susceptibile de a fi aplicabile unui număr mare de tranzacții viitoare.
încredere: probabilitatea ca o tranzacție care conține elementele din partea stângă a regulii (în exemplul nostru, creion și hârtie) să conțină și elementul din partea dreaptă (un cauciuc). Cu cât este mai mare încrederea, cu atât este mai mare probabilitatea ca articolul din partea dreaptă să fie achiziționat sau, cu alte cuvinte, cu atât este mai mare rata de rentabilitate pe care o puteți aștepta pentru o anumită regulă.
Lift: probabilitatea ca toate elementele dintr-o regulă să apară împreună (altfel cunoscut sub numele de suport) împărțit la produsul probabilităților elementelor din partea stângă și dreaptă care apar ca și cum nu ar exista nicio asociere între ele. De exemplu, dacă creionul, hârtia și cauciucul au avut loc împreună în 2,5% din toate tranzacțiile, creionul și hârtia în 10% din tranzacții și cauciucul în 8% din tranzacții, atunci ridicarea ar fi: 0.025/(0.1*0.08) = 3.125. O ridicare mai mare de 1 sugerează că prezența creionului și a hârtiei crește probabilitatea ca un cauciuc să apară și în tranzacție. În general, lift rezumă puterea de asociere între produsele de pe partea stângă și dreaptă a regulii; cu cât este mai mare ascensorul, cu atât este mai mare legătura dintre cele două produse.
pentru a efectua o analiză a coșului de piață și pentru a identifica potențialele reguli, este utilizat în mod obișnuit un algoritm de extragere a datelor numit ‘algoritmul Apriori’, care funcționează în două etape:
- identificați sistematic seturile de elemente care apar frecvent în setul de date cu un suport mai mare decât un prag prestabilit.
- calculați încrederea tuturor regulilor posibile, având în vedere seturile de articole frecvente și păstrați-le doar pe cele cu o încredere mai mare decât un prag prestabilit.
pragurile la care se setează suportul și încrederea sunt specificate de utilizator și sunt susceptibile să varieze între seturile de date privind tranzacțiile. R are valori implicite, dar vă recomandăm să experimentați cu acestea pentru a vedea cum afectează numărul de reguli returnate (mai multe despre acest lucru mai jos). În cele din urmă, deși algoritmul Apriori nu utilizează lift pentru a stabili reguli, veți vedea în cele ce urmează că folosim lift atunci când explorăm Regulile pe care algoritmul le returnează.
efectuarea analizei coșului de piață în R
pentru a demonstra cum să realizăm un MBA am ales să folosim R și, în special, pachetul arules. Pentru cei care sunt interesați, am inclus codul R pe care l-am folosit la sfârșitul acestui blog.
aici, urmăm același exemplu folosit în vinieta Arulesviz și folosim un set de date de vânzări alimentare care conține 9.835 de tranzacții individuale cu 169 de articole. Primul lucru pe care îl facem este să aruncăm o privire asupra elementelor din tranzacții și, în special, să trasăm frecvența relativă a celor mai frecvente 25 de articole din Figura 1. Acest lucru este echivalent cu sprijinul acestor elemente în cazul în care fiecare itemset conține doar un singur element. Acest grafic de bare ilustrează alimentele care sunt cumpărate frecvent la acest magazin și este de remarcat faptul că sprijinul chiar și al celor mai frecvente articole este relativ scăzut (de exemplu, cel mai frecvent articol apare doar în aproximativ 2,5% din tranzacții). Folosim aceste informații pentru a informa pragul minim atunci când rulăm algoritmul Apriori; de exemplu, știm că, pentru ca algoritmul să returneze un număr rezonabil de reguli, va trebui să setăm pragul de asistență la mult sub 0.025.
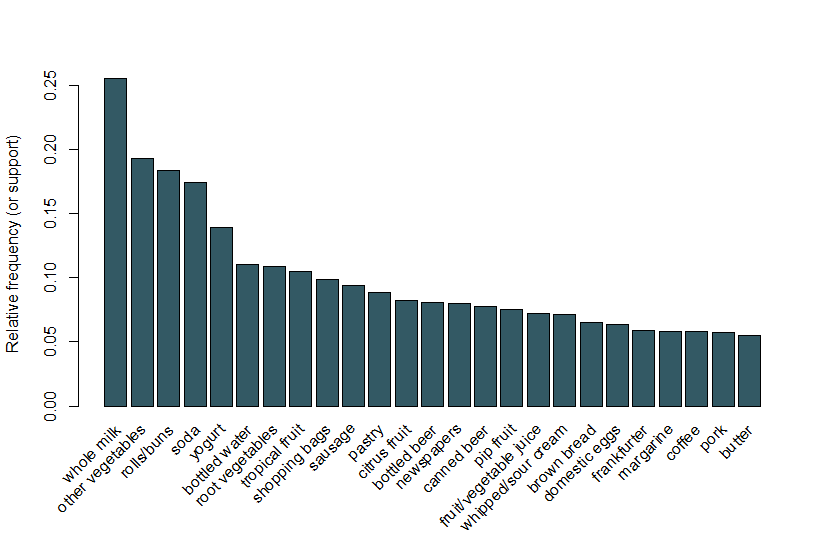
Figura 1 un bar complot de sprijin a 25 Cele mai frecvente elemente cumpărate.
prin stabilirea unui prag de suport de 0,001 și încredere de 0,5, putem rula algoritmul Apriori și obține un set de 5.668 de rezultate. Aceste valori de prag sunt alese astfel încât numărul de reguli returnate să fie ridicat, dar acest număr s-ar reduce dacă am crește oricare dintre praguri. Vă recomandăm să experimentați aceste praguri pentru a obține cele mai potrivite valori. Deși există prea multe reguli pentru a le putea privi pe toate individual, putem analiza cele cinci reguli cu cel mai mare lift:
| regulă | suport | încredere | Lift |
| {produse alimentare instant,soda}=>{carne de hamburger} | 0,001 | 0,632 | 19,00 |
| {soda, popcorn}=>{gustări sărate} | 0.001 | 0.632 | 16.70 |
| {flour, baking powder}=>{sugar} | 0.001 | 0.556 | 16.41 |
| {ham, processed cheese}=>{white bread} | 0.002 | 0.633 | 15.05 |
| {whole milk, instant food products}=>{hamburger meat} | 0.002 | 0.500 | 15.04 |
Table 1: The five rules with the largest lift.
These rules seem to make intuitive sense. De exemplu, prima regulă ar putea reprezenta tipul de articole achiziționate pentru un grătar, a doua pentru o noapte de film și a treia pentru coacere.
în loc să se utilizeze pragurile pentru a reduce Regulile la un set mai mic, este obișnuit ca un set mai mare de reguli să fie returnat, astfel încât să existe șanse mai mari de a genera reguli relevante. Alternativ, putem folosi tehnici de vizualizare pentru a inspecta setul de reguli returnate și pentru a le identifica pe cele care ar putea fi utile.
folosind pachetul arulesviz, trasăm Regulile prin încredere, sprijin și ridicare în Figura 2. Acest grafic ilustrează relația dintre diferitele valori. S-a demonstrat că regulile optime sunt cele care se află pe ceea ce este cunoscut sub numele de „limita de sprijin-încredere”. În esență, acestea sunt regulile care se află la marginea dreaptă a complotului, unde fie sprijinul, încrederea, fie ambele sunt maximizate. Funcția plot din pachetul arulesviz are o funcție interactivă utilă care vă permite să selectați reguli individuale (făcând clic pe punctul de date asociat), ceea ce înseamnă că regulile de la graniță pot fi identificate cu ușurință.
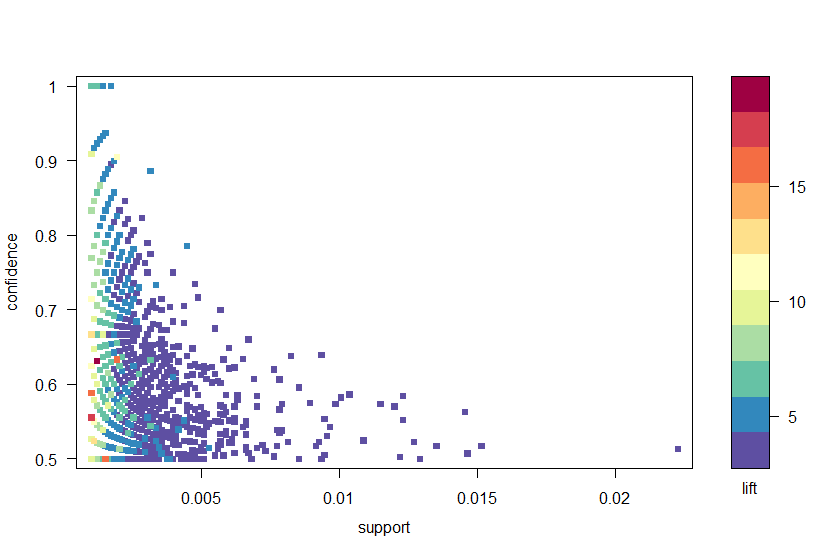
Figura 2: un grafic scatter al valorilor de încredere, suport și ridicare.
există o mulțime de alte parcele disponibile pentru a vizualiza regulile, dar o altă cifră pe care am recomanda Explorarea este vizualizarea bazată pe grafice (a se vedea Figura 3) a primelor zece reguli în ceea ce privește ridicarea (puteți include mai mult de zece, dar aceste tipuri de grafice se pot aglomera cu ușurință). În acest grafic elementele grupate în jurul unui cerc reprezintă un itemset și săgețile indică relația în reguli. De exemplu, o regulă este că achiziționarea de zahăr este asociată cu achizițiile de făină și praf de copt. Dimensiunea cercului reprezintă nivelul de încredere asociat regulii și culoarea nivelului de ridicare (cu cât cercul este mai mare și cu cât este mai întunecat griul, cu atât mai bine).
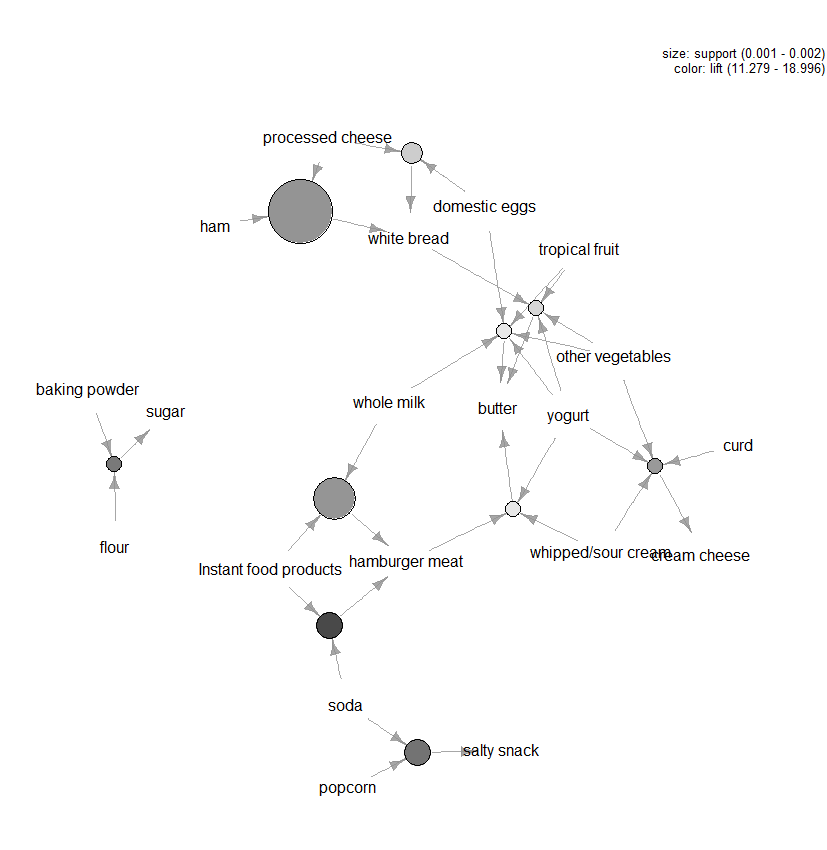
Figura 3: vizualizarea pe bază de grafic a primelor zece reguli în ceea ce privește ridicarea.analiza coșului de piață este un instrument util pentru comercianții cu amănuntul care doresc să înțeleagă mai bine relațiile dintre produsele pe care oamenii le cumpără. Există multe instrumente care pot fi aplicate la efectuarea MBA și cele mai dificile aspecte ale analizei sunt stabilirea pragurilor de încredere și sprijin în algoritmul Apriori și identificarea regulilor care merită urmărite. De obicei, aceasta din urmă se realizează prin măsurarea regulilor în termeni de valori care rezumă cât de interesante sunt, folosind tehnici de vizualizare și, de asemenea, statistici multivariate mai formale. În cele din urmă, cheia MBA este de a extrage valoare din datele dvs. de tranzacție prin construirea unei înțelegeri a nevoilor consumatorilor dvs. Acest tip de informații este de neprețuit dacă sunteți interesat de activități de marketing, cum ar fi vânzările încrucișate sau campaniile direcționate.
Dacă doriți să aflați mai multe despre cum să analizați datele tranzacției dvs., vă rugăm să ne contactați și vă vom ajuta cu plăcere.
R Code
library("arules")
library("arulesViz")
#Load data set:
data("Groceries")
summary(Groceries)
#Look at data:
inspect(Groceries)
LIST(Groceries)
#Calculate rules using apriori algorithm and specifying support and confidence thresholds:
rules = apriori(Groceries, parameter=list(support=0.001, confidence=0.5))
#Inspect the top 5 rules in terms of lift:
inspect(head(sort(rules, by ="lift"),5))
#Plot a frequency plot:
itemFrequencyPlot(Groceries, topN = 25)
#Scatter plot of rules:
library("RColorBrewer")
plot(rules,control=list(col=brewer.pal(11,"Spectral")),main="")
#Rules with high lift typically have low support.
#The most interesting rules reside on the support/confidence border which can be clearly seen in this plot.