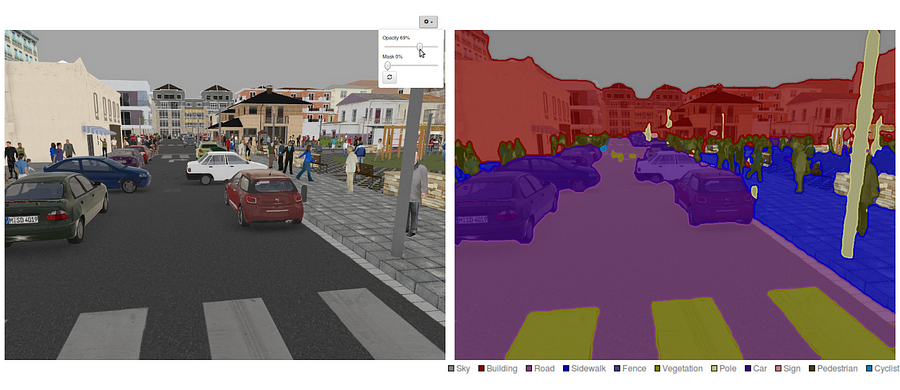
Cum se face segmentarea semantică folosind învățarea profundă
Acest articol este o imagine de ansamblu cuprinzătoare, inclusiv un ghid pas cu pas pentru implementarea unui model de segmentare a imaginii de învățare profundă.
am împărtășit un nou blog actualizat despre segmentarea semantică aici: un ghid 2021 pentru segmentarea semantică
în zilele noastre, segmentarea semantică este una dintre problemele cheie din domeniul viziunii computerizate. Privind imaginea de ansamblu, segmentarea semantică este una dintre sarcinile la nivel înalt care deschide calea către înțelegerea completă a scenei. Importanța înțelegerii scenei ca problemă de bază a vederii pe computer este evidențiată de faptul că un număr tot mai mare de aplicații se hrănesc din deducerea cunoștințelor din imagini. Unele dintre aceste aplicații includ vehicule cu conducere automată, interacțiune om-computer, realitate virtuală etc. Odată cu popularitatea învățării profunde în ultimii ani, multe probleme de segmentare semantică sunt abordate folosind arhitecturi profunde, cel mai adesea rețele neuronale convoluționale, care depășesc alte abordări cu o marjă mare în ceea ce privește acuratețea și eficiența.
- ce este segmentarea semantică?
- ce sunt abordările de segmentare semantică existente?
- 1 — segmentarea semantică bazată pe Regiune
- 2 — segmentarea semantică bazată pe rețea complet convoluțională
- 3 — segmentare semantică slab supravegheată
- efectuarea segmentării semantice cu rețeaua complet convoluțională
- pasul 1
- Pasul 2
- Pasul 3
- Pasul 4
- Pasul 5
- s-ar putea să vă intereseze ultimele noastre postări despre:
ce este segmentarea semantică?
segmentarea semantică este un pas natural în progresia de la inferența grosieră la cea fină:originea ar putea fi localizată la clasificare, care constă în realizarea unei predicții pentru o intrare întreagă.Următorul pas este localizarea / detectarea, care oferă nu numai clasele, ci și informații suplimentare cu privire la locația spațială a acestor clase.În cele din urmă, segmentarea semantică realizează inferență cu granulație fină făcând predicții dense care deduc etichete pentru fiecare pixel, astfel încât fiecare pixel să fie etichetat cu clasa regiunii sale de minereu de obiect care închide.
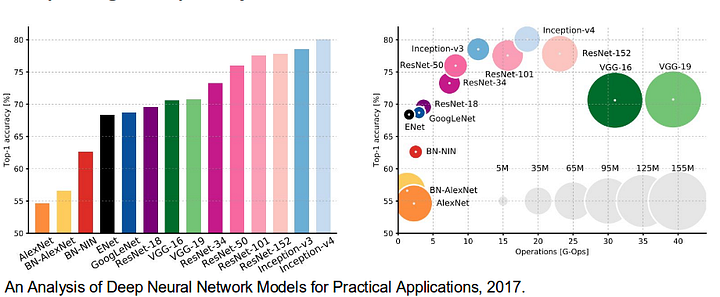
de asemenea, este demn de a revizui unele rețele profunde standard, care au adus contribuții semnificative la domeniul viziunii pe calculator, deoarece acestea sunt adesea folosite ca bază a sistemelor de segmentare semantică:
- AlexNet: Toronto de pionierat profund CNN care a câștigat competiția IMAGEnet 2012 cu o precizie de testare de 84,6%. Se compune din 5 straturi convoluționale, cele max-pooling, ReLUs ca non-liniarități, 3 straturi complet convoluționale și abandon.
- VGG-16: Acest model Oxford a câștigat competiția ImageNet din 2013 cu o precizie de 92,7%. Folosește un teanc de straturi de convoluție cu câmpuri receptive mici în primele straturi în loc de câteva straturi cu câmpuri receptive mari.
- GoogLeNet: această rețea Google a câștigat competiția ImageNet 2014 cu o precizie de 93,3%. Acesta este compus din 22 de straturi și un bloc nou introdus numit inception module. Modulul constă dintr-un strat de rețea în rețea, o operație de punere în comun, un strat de convoluție de dimensiuni mari și un strat de convoluție de dimensiuni mici.
- ResNet: acest model Microsoft a câștigat competiția ImageNet 2016 cu o precizie de 96,4%. Este bine cunoscut datorită adâncimii sale (152 straturi) și introducerii blocurilor reziduale. Blocurile reziduale abordează problema formării unei arhitecturi cu adevărat profunde prin introducerea conexiunilor de omitere a identității, astfel încât straturile să își poată copia intrările în stratul următor.
ce sunt abordările de segmentare semantică existente?
o arhitectură generală de segmentare semantică poate fi gândită în general ca o rețea de codificator urmată de o rețea de decodificator:
- codificatorul este de obicei o rețea de clasificare pre-instruită, cum ar fi VGG / ResNet, urmată de o rețea de decodificator.
- sarcina decodorului este de a proiecta semantic caracteristicile discriminative (rezoluție mai mică) învățate de codificator pe spațiul pixelilor (rezoluție mai mare) pentru a obține o clasificare densă.
spre deosebire de clasificarea în care rezultatul final al rețelei foarte profunde este singurul lucru important, segmentarea semantică nu necesită doar discriminare la nivel de pixeli, ci și un mecanism de proiectare a caracteristicilor discriminative învățate în diferite etape ale codificatorului pe spațiul pixelilor. Abordări diferite folosesc mecanisme diferite ca parte a mecanismului de decodare. Să explorăm cele 3 abordări principale:
1 — segmentarea semantică bazată pe Regiune
metodele bazate pe regiune urmează în general conducta „segmentarea folosind recunoașterea”, care extrage mai întâi regiunile de formă liberă dintr-o imagine și le descrie, urmată de clasificarea bazată pe regiune. La momentul testului, predicțiile bazate pe regiune sunt transformate în predicții ale pixelilor, de obicei prin etichetarea unui pixel în funcție de regiunea cu cel mai mare punctaj care îl conține.
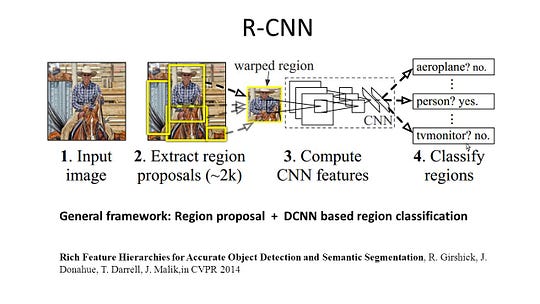
r-CNN (regiuni cu caracteristică CNN) este o lucrare reprezentativă pentru metodele bazate pe regiune. Efectuează segmentarea semantică pe baza rezultatelor detectării obiectelor. Pentru a fi specific, R-CNN utilizează mai întâi căutarea selectivă pentru a extrage o cantitate mare de propuneri de obiecte și apoi calculează caracteristicile CNN pentru fiecare dintre ele. În cele din urmă, clasifică fiecare regiune folosind SVM-urile liniare specifice clasei. În comparație cu structurile tradiționale CNN care sunt destinate în principal clasificării imaginilor, R-CNN poate aborda sarcini mai complicate, cum ar fi detectarea obiectelor și segmentarea imaginilor și devine chiar o bază importantă pentru ambele domenii. Mai mult decât atât, R-CNN poate fi construit pe partea de sus a oricăror structuri de referință CNN, cum ar fi AlexNet, VGG, GoogLeNet, și ResNet.
pentru sarcina de segmentare a imaginii, R-CNN a extras 2 tipuri de caracteristici pentru fiecare regiune: caracteristica regiunii complete și caracteristica prim-plan și a constatat că ar putea duce la o performanță mai bună atunci când le concatenează împreună ca caracteristică a regiunii. R-CNN a obținut îmbunătățiri semnificative ale performanței datorită utilizării caracteristicilor CNN extrem de discriminatorii. Cu toate acestea, suferă și de câteva dezavantaje pentru sarcina de segmentare:
- caracteristica nu este compatibilă cu sarcina de segmentare.
- caracteristica nu conține suficiente informații spațiale pentru generarea precisă a limitelor.
- generarea de propuneri bazate pe segmente necesită timp și ar afecta foarte mult performanța finală.datorită acestor blocaje, cercetările recente au fost propuse pentru a aborda problemele, inclusiv SDS, Hypercolumns, Mask R-CNN.
2 — segmentarea semantică bazată pe rețea complet convoluțională
rețeaua originală complet convoluțională (FCN) învață o mapare de la pixeli la pixeli, fără a extrage propunerile regiunii. Conducta de rețea FCN este o extensie a clasicului CNN. Ideea principală este de a face ca CNN-ul clasic să ia ca intrare imagini de dimensiuni arbitrare. Restricția CNN-urilor de a accepta și produce etichete numai pentru intrări de dimensiuni specifice provine din straturile complet conectate care sunt fixe. Contrar acestora, FCN-urile au doar straturi convoluționale și de grupare care le oferă posibilitatea de a face predicții asupra intrărilor de dimensiuni arbitrare.
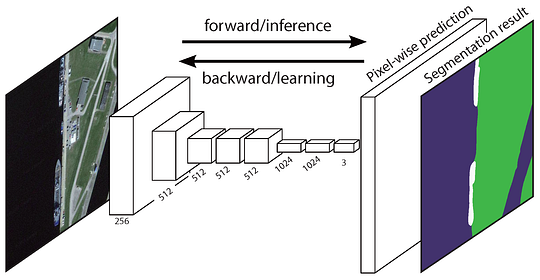
arhitectură FCN o problemă în acest FCN specific este că prin propagarea prin mai multe straturi convoluționale și de grupare alternate, rezoluția din hărțile de caracteristici de ieșire este eșantionat în jos. Prin urmare, predicțiile directe ale FCN sunt de obicei la rezoluție mică, rezultând limite relativ neclare ale obiectelor. Au fost propuse o varietate de abordări mai avansate bazate pe FCN pentru a aborda această problemă, inclusiv SegNet, Deeplab-CRF și convoluții dilatate.
3 — segmentare semantică slab supravegheată
majoritatea metodelor relevante în segmentarea semantică se bazează pe un număr mare de imagini cu măști de segmentare în funcție de pixeli. Cu toate acestea, adnotarea manuală a acestor măști este destul de consumatoare de timp, frustrantă și costisitoare din punct de vedere comercial. Prin urmare, au fost propuse recent unele metode slab supravegheate, care sunt dedicate îndeplinirii segmentării semantice prin utilizarea cutiilor de încadrare adnotate.

Boxsup Training de exemplu, Boxsup a folosit adnotările cutiei de delimitare ca supraveghere pentru a instrui rețeaua și a îmbunătăți iterativ măștile estimate pentru segmentarea semantică. Simplu nu a tratat limitarea slabă a supravegherii ca o problemă a zgomotului etichetei de intrare și a explorat formarea recursivă ca o strategie de reducere a zgomotului. Etichetarea la nivel de pixeli a interpretat sarcina de segmentare în cadrul de învățare cu mai multe instanțe și a adăugat un strat suplimentar pentru a constrânge modelul să atribuie mai multă greutate pixelilor importanți pentru clasificarea la nivel de imagine.
efectuarea segmentării semantice cu rețeaua complet convoluțională
În această secțiune, să parcurgem o implementare pas cu pas a celei mai populare arhitecturi pentru segmentarea semantică-rețeaua complet convoluțională (FCN). Vom implementa folosind biblioteca TensorFlow în Python 3, împreună cu alte dependențe, cum ar fi Numpy și Scipy.In acest exercițiu vom eticheta pixelii unui drum în imagini folosind FCN. Vom lucra cu setul de date Kitti Road pentru detectarea drumului / benzii. Acesta este un exercițiu simplu din programul de Nano-grade auto Udacity, pe care îl puteți afla mai multe despre configurarea din acest repo GitHub.

Kitti Road dataset Training Sample (Sursa: http://www.cvlibs.net/datasets/kitti/eval_road_detail.php?result=3748e213cf8e0100b7a26198114b3cdc7caa3aff) iată caracteristicile cheie ale arhitecturii FCN:
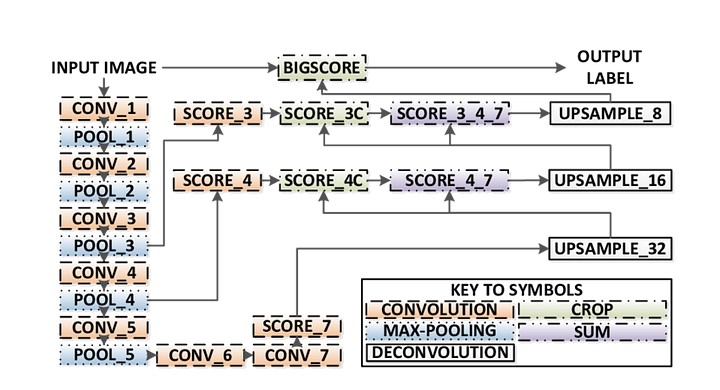
- FCN transferă cunoștințe de la vgg16 pentru a efectua segmentarea semantică.
- straturile complet conectate ale VGG16 sunt convertite în straturi complet convoluționale, folosind convoluția 1×1. Acest proces produce o hartă de căldură prezență clasă în rezoluție mică.
- eșantionarea acestor hărți de caracteristici semantice de rezoluție mică se face folosind convoluții transpuse (inițializate cu filtre de interpolare biliniare).
- în fiecare etapă, procesul de upsampling este rafinat în continuare prin adăugarea de caracteristici din Hărți de caracteristici mai grosiere, dar cu rezoluție mai mare, din straturile inferioare din VGG16.
- conexiunea Skip este introdusă după fiecare bloc de convoluție pentru a permite blocului ulterior să extragă caracteristici mai abstracte, de clasă, din caracteristicile reunite anterior.
există 3 versiuni ale FCN (FCN-32, FCN-16, FCN-8). Vom implementa FCN-8, așa cum este detaliat pas cu pas mai jos:
- Encoder: un vgg16 pre-instruit este utilizat ca codificator. Decodorul pornește de la stratul 7 al VGG16.
- FCN Layer-8: ultimul strat complet conectat al VGG16 este înlocuit cu o convoluție 1×1.
- FCN Layer-9: FCN Layer-8 este upsampled de 2 ori pentru a se potrivi dimensiuni cu stratul 4 de VGG 16, folosind convoluție transpusă cu parametrii: (kernel=(4,4), stride=(2,2), paddding=’same’). După aceea, a fost adăugată o conexiune de omitere între stratul 4 al Vgg16 și stratul FCN-9.
- FCN Layer-10: FCN Layer-9 este upsampled de 2 ori pentru a se potrivi dimensiuni cu stratul 3 de VGG16, folosind convoluție transpusă cu parametrii: (kernel=(4,4), stride=(2,2), paddding=’same’). După aceea, a fost adăugată o conexiune de omitere între stratul 3 al VGG 16 și stratul FCN-10.
- FCN Layer-11: FCN Layer-10 este upsampled de 4 ori pentru a se potrivi dimensiuni cu dimensiunea imaginii de intrare, astfel încât să obținem imaginea reală înapoi și adâncimea este egală cu numărul de clase, folosind convoluție transpusă cu parametrii:(kernel=(16,16), stride=(8,8), paddding=’same’).
FCN-8 arhitectura (Sursa: https://www.researchgate.net/figure/Illustration-of-the-FCN-8s-network-architecture-as-proposed-in-20-In-our-method-the_fig1_305770331) pasul 1
Mai întâi încărcăm modelul VGG-16 pre-instruit în TensorFlow. Luând în sesiunea TensorFlow și calea către folderul VGG (care poate fi descărcat aici), returnăm tuplul de tensori din modelul VGG, inclusiv intrarea imaginii, keep_prob (pentru a controla rata de abandon), stratul 3, stratul 4 și stratul 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7funcția VGG16
Pasul 2
acum ne concentrăm pe crearea straturilor pentru un FCN, folosind tensorii din modelul VGG. Având în vedere tensorii pentru ieșirea stratului VGG și numărul de clase de clasificat, returnăm tensorul pentru ultimul strat al acelei ieșiri. În special, aplicăm o convoluție 1×1 straturilor de codificator, apoi adăugăm straturi de decodificator în rețea cu conexiuni de omitere și eșantionare.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11straturi funcția
Pasul 3
următorul pas este de a optimiza rețeaua noastră neuronală, aka construirea TensorFlow funcții de pierdere și operațiunile de optimizare. Aici folosim entropia încrucișată ca funcție de pierdere și Adam ca algoritm de optimizare.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opOptimizați funcția
Pasul 4
aici definim funcția train_nn, care preia parametri importanți, inclusiv numărul de epoci, dimensiunea lotului, funcția de pierdere, funcționarea optimizatorului și substituenții pentru imaginile de intrare, imaginile etichetelor, rata de învățare. Pentru procesul de instruire, setăm, de asemenea, keep_probability la 0,5 și learning_rate la 0,001. Pentru a urmări progresul, tipărim și pierderea în timpul antrenamentului.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Pasul 5
în cele din urmă, este timpul să ne antrenăm plasa! În această funcție run, ne construim mai întâi rețeaua folosind funcția load_vgg, layers și optimize. Apoi antrenăm plasa folosind funcția train_nn și salvăm datele de inferență pentru înregistrări.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)rulați funcția
despre parametrii noștri, alegem epochs = 40, batch_size = 16, num_classes = 2 și image_shape = (160, 576). După ce am făcut 2 treceri de încercare cu abandon = 0,5 și abandon = 0,75, am constatat că al 2-lea proces dă rezultate mai bune cu pierderi medii mai bune.

rezultatele eșantionului de formare pentru a vedea codul complet, consultați acest link: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
dacă ți-a plăcut această piesă, mi-ar plăcea să o împărtășesc și să răspândesc cunoștințele.
s-ar putea să vă intereseze ultimele noastre postări despre:
- AWS Textract
- extragerea datelor
începeți să utilizați Nanonete pentru automatizare
încercați modelul sau solicitați o demonstrație astăzi!
încercați acum
