Detectarea obiectelor pentru manechine Partea 3: Familia R-CNN
în partea 3, vom examina patru modele de detectare a obiectelor: R-CNN, Fast R-CNN, Faster R-CNN și Mask R-CNN. Aceste modele sunt foarte înrudite, iar noile versiuni prezintă o îmbunătățire mare a vitezei în comparație cu cele mai vechi.
în seria „detectarea obiectelor pentru manechine”, am început cu concepte de bază în procesarea imaginilor, cum ar fi vectorii de gradient și porcul, în partea 1. Apoi am introdus modele clasice de arhitectură convoluțională a rețelei neuronale pentru clasificare și modele pioneer pentru recunoașterea obiectelor, Overfeat și DPM, în partea 2. În cea de-a treia postare a acestei serii, suntem pe cale să revizuim un set de modele din familia R-CNN („CNN pe bază de regiune”).
link-uri către toate postările din serie: .
aici este o listă de lucrări acoperite în acest post 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
R-CNN
R-CNN (Girshick et al., 2014) is short for „Region-based Convolutional Neural Networks”. The main idea is composed of two steps. În primul rând, folosind căutarea selectivă, identifică un număr gestionabil de candidați pentru regiunea obiectului de delimitare („regiune de interes” sau „RoI”). Și apoi extrage caracteristicile CNN din fiecare regiune independent pentru clasificare.
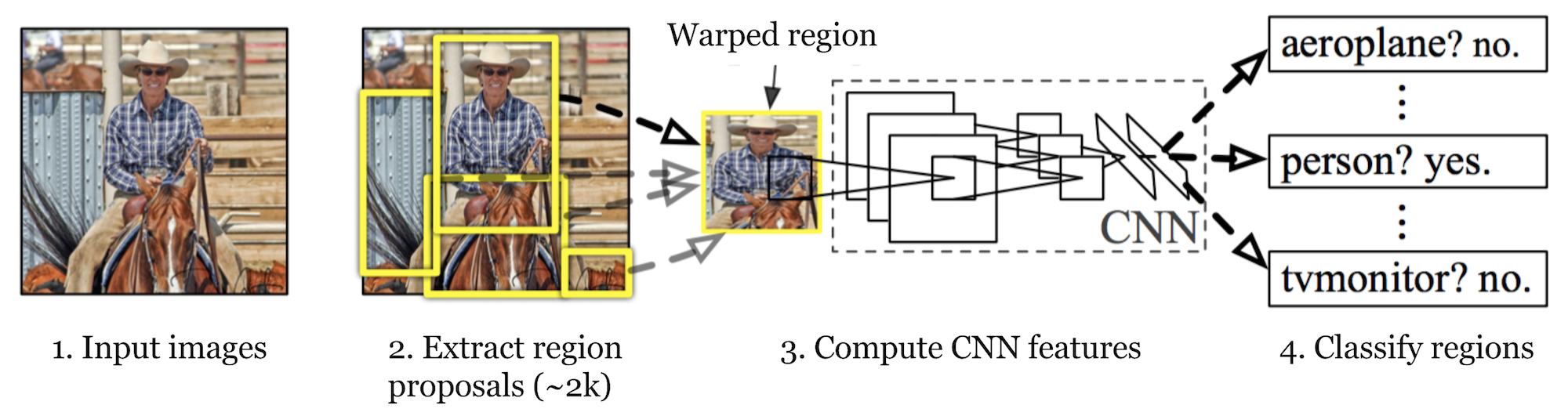
Fig. 1. Arhitectura R-CNN. (Sursa imaginii: Girshick și colab., 2014)
model Workflow
cum funcționează R-CNN pot fi rezumate după cum urmează:
- pre-instruiți o rețea CNN pe sarcini de clasificare a imaginilor; de exemplu, VGG sau ResNet instruiți pe setul de date ImageNet. Sarcina de clasificare implică n clase.
Notă: Puteți găsi un AlexNet pre-instruit în Caffe model Zoo. Nu cred că îl puteți găsi în Tensorflow, dar Tensorflow-slim model library oferă ResNet pre-instruit, VGG și altele.
- Propuneți regiuni de interes independente de categorie prin căutare selectivă (~2K candidați pe imagine). Aceste regiuni pot conține obiecte țintă și au dimensiuni diferite.
- candidații din regiune sunt deformați pentru a avea o dimensiune fixă, conform cerințelor CNN.
- continuați reglarea fină a CNN pe regiunile de propunere deformate pentru clasele K + 1; clasa suplimentară se referă la fundal (fără obiect de interes). În etapa de reglaj fin, ar trebui să folosim o rată de învățare mult mai mică, iar mini-lotul supraeșantionează cazurile pozitive, deoarece majoritatea regiunilor propuse sunt doar fundal.
- având în vedere fiecare regiune de imagine, o propagare înainte prin CNN generează un vector caracteristică. Acest vector caracteristică este apoi consumat de un SVM binar instruit pentru fiecare clasă independent.
probele pozitive sunt regiuni propuse cu IoU (intersecție peste Uniune) se suprapun prag>= 0,3, și probele negative sunt altele irelevante. - pentru a reduce erorile de localizare, un model de regresie este instruit pentru a corecta fereastra de detectare prezisă pe compensarea corecției cutiei de delimitare folosind caracteristicile CNN.
regresia cutiei de încadrare
dată fiind o coordonată a cutiei de încadrare prezisă \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (coordonata centrală, lățimea, înălțimea) și coordonatele corespunzătoare ale cutiei de adevăr la sol \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , regresorul este configurat să învețe transformarea invariantă la scară între două centre și transformarea lățimi și înălțimi. Toate funcțiile de transformare iau \(\mathbf{p}\) ca intrare.
\
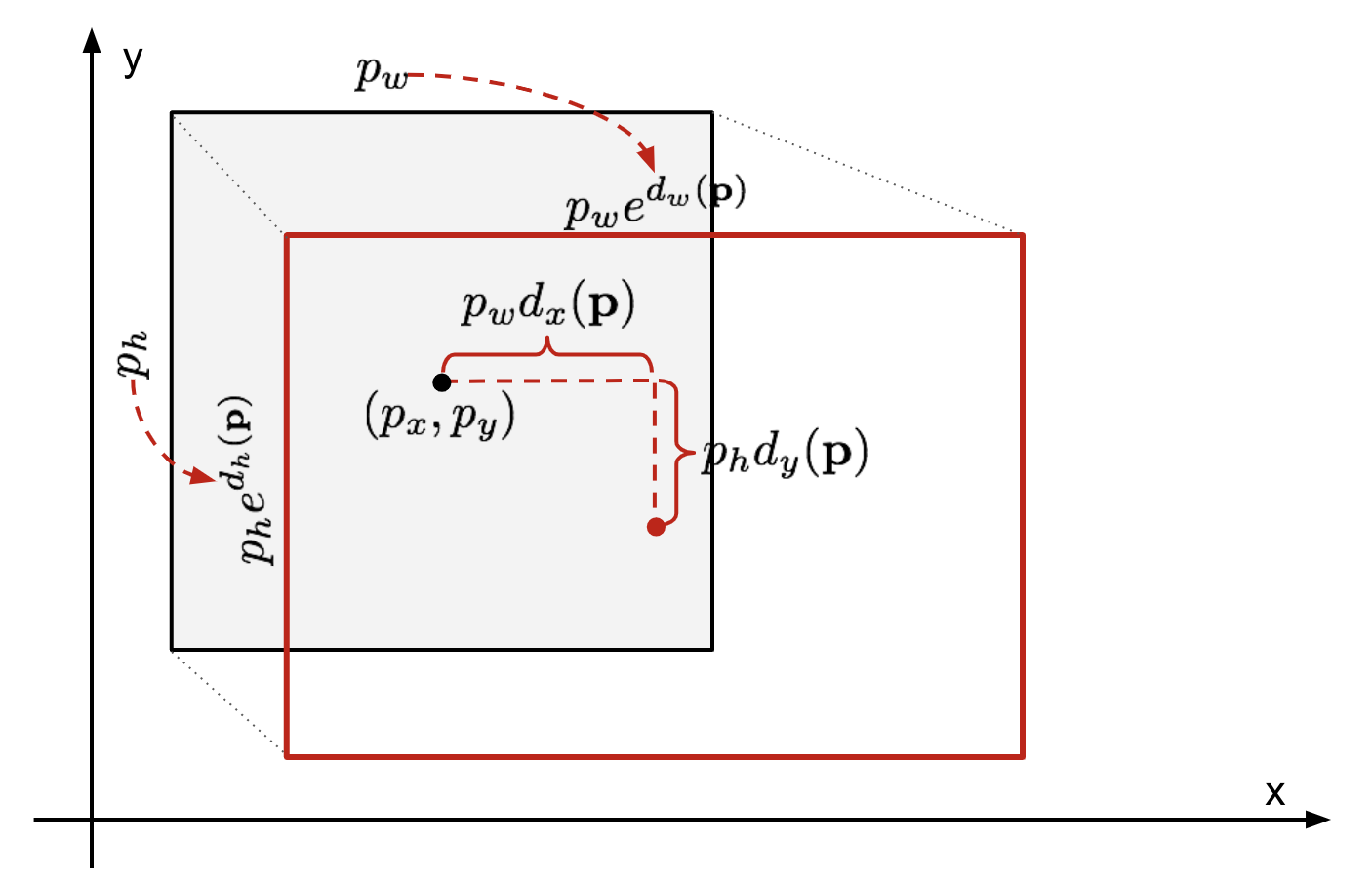
Fig. 2. Ilustrare a transformării între cutiile de delimitare a adevărului prezis și a Pământului.
un beneficiu evident al aplicării unei astfel de transformări este că toate funcțiile de corecție a casetei de încadrare, \(d_i(\mathbf{p})\) unde \(i \în \{ x, y, w, h \}\), pot lua orice valoare între . Țintele pe care trebuie să le învețe sunt:
\
Un model de regresie standard poate rezolva problema prin minimizarea pierderii SSE cu regularizare:
\
termenul de regularizare este critic aici și hârtia RCNN a ales cel mai bun Ecuator prin validare încrucișată. De asemenea, este demn de remarcat faptul că nu toate casetele de delimitare prezise au cutii de adevăr la sol corespunzătoare. De exemplu, dacă nu există nicio suprapunere, nu are sens să rulați regresia bbox. Aici, doar o cutie prezisă cu o cutie de adevăr la sol din apropiere cu cel puțin 0,6 IoU este păstrată pentru instruirea modelului de regresie bbox.
trucuri comune
Mai multe trucuri sunt utilizate în mod obișnuit în rcnn și alte modele de detectare.
suprimarea non-maximă
probabil modelul este capabil să găsească mai multe cutii de încadrare pentru același obiect. Suprimarea Non-max ajută la evitarea detectării repetate a aceleiași instanțe. După ce obținem un set de cutii de încadrare potrivite pentru aceeași categorie de obiecte:Sortați toate casetele de încadrare după scorul de încredere.Aruncați cutii cu scoruri de încredere scăzute.În timp ce există o cutie de încadrare rămasă, repetați următoarele:selectați cu lăcomie cel cu cel mai mare scor.Săriți casetele rămase cu IoU ridicat (adică > 0,5) cu una selectată anterior.

Fig. 3. Mai multe cutii de încadrare detectează mașina din imagine. După suprimarea non-maximă, numai cele mai bune rămășițe și restul sunt ignorate, deoarece au suprapuneri mari cu cea selectată. (Sursa imaginii: hârtie PDM)
minerit negativ greu
considerăm cutii de încadrare fără obiecte ca exemple negative. Nu toate exemplele negative sunt la fel de greu de identificat. De exemplu, dacă deține fundal gol pur, este probabil un „negativ ușor”; dar dacă caseta conține textură zgomotoasă ciudată sau obiect parțial, ar putea fi greu de recunoscut și acestea sunt „negative dure”.
exemplele negative dure sunt ușor clasificate greșit. Putem găsi în mod explicit acele eșantioane fals pozitive în timpul buclelor de antrenament și le putem include în datele de antrenament pentru a îmbunătăți clasificatorul.
Speed Bottleneck
privind prin etapele de învățare R-CNN, ai putea găsi cu ușurință că formarea unui model R-CNN este scump și lent, ca următorii pași implică o mulțime de muncă:
- rularea de căutare selectivă pentru a propune 2000 candidați regiune pentru fiecare imagine;
- generarea vectorului caracteristica CNN pentru fiecare regiune imagine (n imagini * 2000).
- întregul proces implică trei modele separat, fără prea multe calcule partajate: rețeaua neuronală convoluțională pentru clasificarea imaginilor și extragerea caracteristicilor; clasificatorul SVM de top pentru identificarea obiectelor țintă; și modelul de regresie pentru strângerea cutiilor de delimitare a regiunii.
Fast R-CNN
pentru a face R-CNN mai rapid, Girshick (2015) a îmbunătățit procedura de instruire prin unificarea a trei modele independente într-un cadru instruit în comun și creșterea rezultatelor de calcul comune, numite Fast R-CNN. În loc să extragă vectori de caracteristici CNN independent pentru fiecare propunere de regiune, acest model îi agregă într-o singură trecere înainte CNN pe întreaga imagine, iar propunerile de regiune împărtășesc această matrice de caracteristici. Apoi, aceeași matrice caracteristică este ramificată pentru a fi utilizată pentru învățarea Clasificatorului de obiecte și a regresorului casetei de încadrare. În concluzie, partajarea calculului accelerează R-CNN.
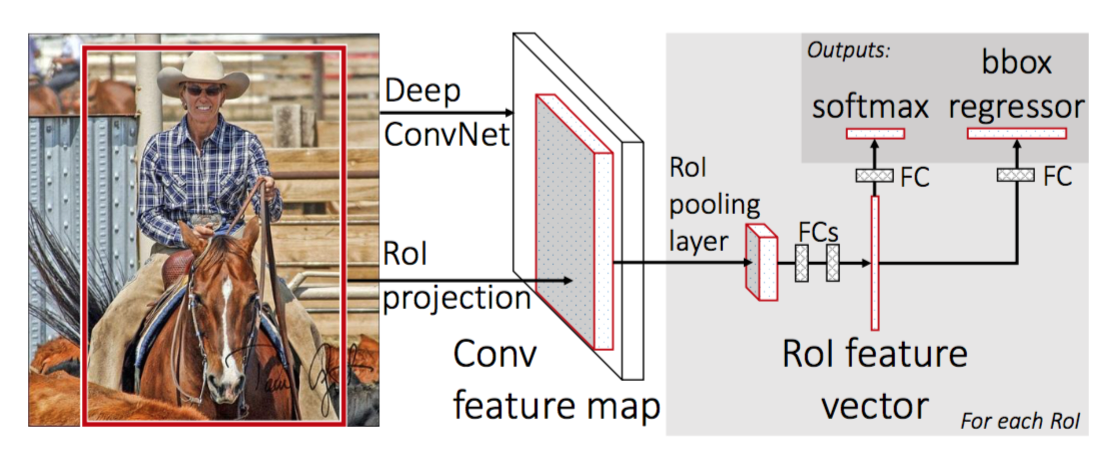
Fig. 4. Arhitectura Fast R-CNN. (Sursa imaginii: Girshick, 2015)
Roi Pooling
este un tip de max pooling pentru a converti caracteristicile din regiunea proiectată a imaginii de orice dimensiune, h x w, într-o fereastră fixă mică, H x W. regiunea de intrare este împărțită în grile H x W, aproximativ fiecare subfereastră de dimensiune h/H x w/W. apoi aplicați max-pooling în fiecare grilă.
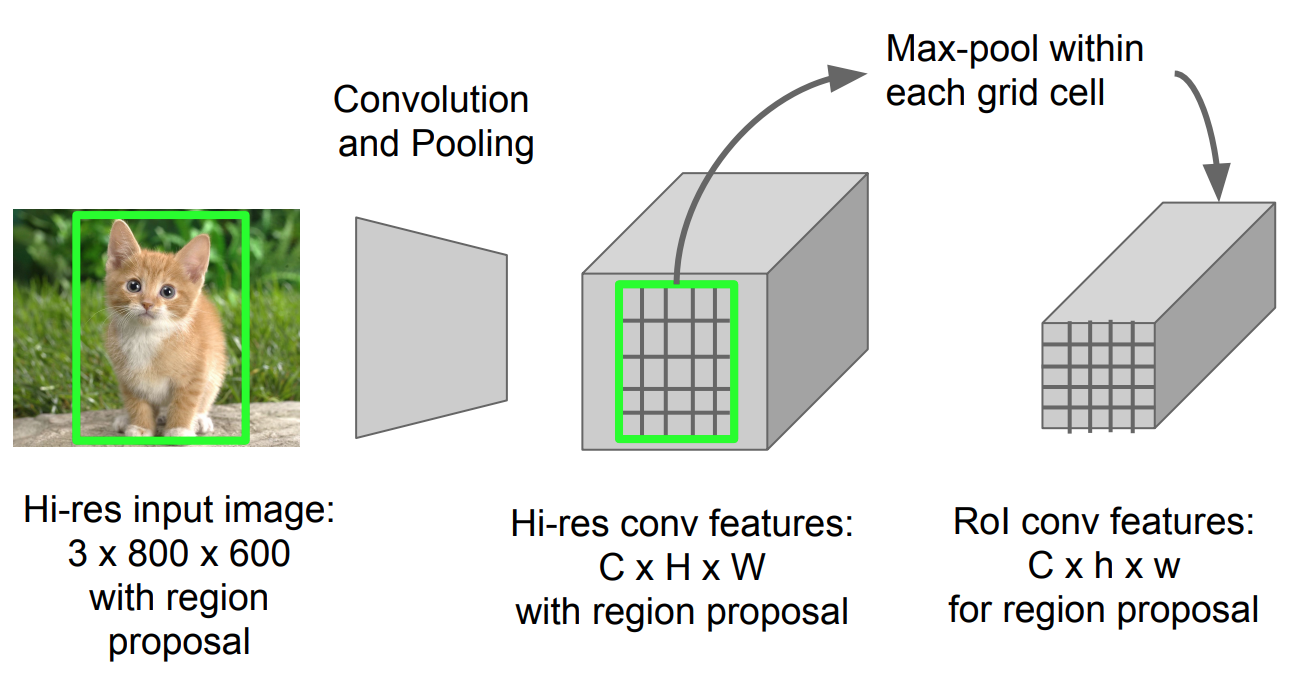
Fig. 5. ROI pooling (sursa imaginii: Stanford cs231n slide-uri.)
model de flux de lucru
cât de repede funcționează R-CNN este rezumată după cum urmează; mulți pași sunt aceiași ca în R-CNN:
- În primul rând, pre-antrenați o rețea neuronală convoluțională pe sarcini de clasificare a imaginilor.
- Propuneți regiuni prin căutare selectivă (~2K candidați pe imagine).
- modificați CNN-ul pre-instruit:
- înlocuiți ultimul strat maxim de punere în comun al CNN-ului pre-instruit cu un strat de punere în comun RoI. Stratul de punere în comun a RoI produce vectori de caracteristici de lungime fixă ale propunerilor de regiune. Partajarea calculului CNN are mult sens, deoarece multe propuneri de regiuni ale acelorași imagini sunt foarte suprapuse.
- înlocuiți ultimul strat complet conectat și ultimul strat softmax (clasele K) cu un strat complet conectat și softmax peste clasele K + 1.
- În cele din urmă, modelul se ramifică în două straturi de ieșire:
- un estimator softmax al claselor K + 1 (la fel ca în R-CNN, +1 este clasa „fundal”), producând o distribuție discretă a probabilității pe RoI.
- un model de regresie a cutiei de încadrare care prezice compensări în raport cu RoI-ul inițial pentru fiecare dintre clasele K.
funcția de pierdere
modelul este optimizat pentru o pierdere care combină două sarcini (clasificare + localizare):
| simbol | explicație |
| \(u\) | etichetă de clasă adevărată, \(u \în 0, 1, \puncte, K\); prin convenție, clasa de fundal catch-all are \(u = 0\). |
| \(p\) | distribuție de probabilitate discretă (per RoI) peste clasele K + 1: \(p = (p_0, \dots, p_K)\), calculată de un softmax peste ieșirile K + 1 ale unui strat complet conectat. |
| \(v\) | caseta de încadrare adevărată \(v = (v_x, v_y, v_w, v_h)\). |
| \(t^u\) | corecție caseta de încadrare prezis, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Vezi mai sus. |
funcția de pierdere însumează costul de clasificare și de încadrare caseta de predicție: \(\mathcal{l} = \mathcal{l}_\text{cls} + \mathcal{l}_\text{box}\). Pentru” fundal ” RoI, \(\mathcal{l} _ \ text{box}\) este ignorat de funcția indicator \(\mathbb{1}\), definită ca:
\ = \begin{cases} 1 & \text{if } u \geq 1\\ 0 & \text{otherwise}\end{cases}\]
funcția generală de pierdere este:
\ \mathcal{l}_\text{box}(t^u, v) \\\mathcal{l}_\text{cls}(p, u) &= -\log p_u \\\mathcal{l}_\text{box}(t^u, v) &= \sum_{i \în \{X, Y, W, H\}} l_1^\text{smooth} (t^u_i – v_i)\end{align*}\]
caseta de delimitare pierdere \(\mathcal{l}_{box}\) ar trebui să măsoare diferența dintre \(t^u_i\) și \(v_i\) folosind o funcție de pierdere robustă. Pierderea L1 netedă este adoptată aici și se pretinde a fi mai puțin sensibilă la valori aberante.
\
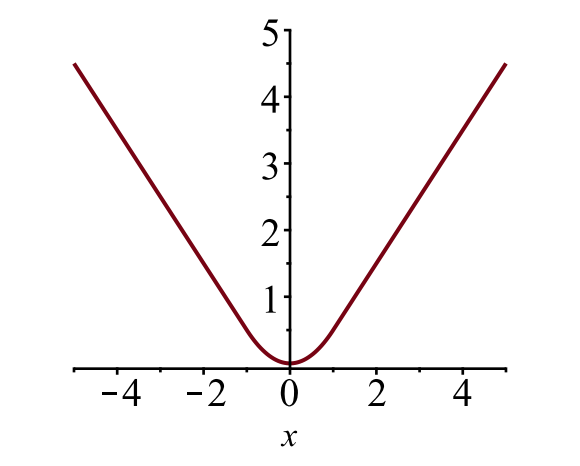
Fig. 6. Intriga pierderii L1 netede, \(y = l_1^\text{smooth} (x)\). (Sursa imaginii: link)
blocaj de viteză
fast R-CNN este mult mai rapid atât în timpul antrenamentului, cât și în timpul testării. Cu toate acestea, îmbunătățirea nu este dramatică, deoarece propunerile din regiune sunt generate separat de un alt model și acest lucru este foarte scump.
Faster R-CNN
o soluție intuitivă de accelerare este integrarea algoritmului de propunere a regiunii în modelul CNN. Mai rapid R-CNN (Ren și colab., 2016) face exact acest lucru: construiește un singur model unificat compus din RPN (rețeaua de propuneri de regiune) și R-CNN rapid cu straturi de caracteristici convoluționale partajate.

Fig. 7. O ilustrare a modelului R-CNN mai rapid. (Sursa imaginii: Ren și colab., 2016)
model de flux de lucru
- pre-instruiți o rețea CNN cu privire la sarcinile de clasificare a imaginilor.
- reglați fin RPN (rețeaua de propuneri de regiune) end-to-end pentru sarcina de propunere de regiune, care este inițializată de clasificatorul de imagini pre-tren. Probele pozitive au IoU (intersecție-supra-Uniune)> 0,7, în timp ce probele negative au IoU< 0,3.
- glisați o mică fereastră spațială n x n peste harta caracteristică conv a întregii imagini.
- în centrul fiecărei ferestre glisante, prezicem mai multe regiuni de diferite scări și rapoarte simultan. O ancoră este o combinație de (centru de ferestre glisante, scară, raport). De exemplu, 3 scale + 3 rapoarte => k=9 ancore la fiecare poziție de alunecare.
- antrenează un model rapid de detectare a obiectelor R-CNN folosind propunerile generate de actualul RPN
- apoi folosește rețeaua rapidă R-CNN pentru a inițializa instruirea RPN. Păstrând straturile convoluționale partajate, reglați doar straturile specifice RPN. În această etapă, RPN și rețeaua de detectare au împărtășit straturi convoluționale!
- în cele din urmă ajusta straturile unice de rapid R-CNN
- pasul 4-5 poate fi repetat pentru a instrui RPN și rapid r-CNN alternativ, dacă este necesar.
funcția de pierdere
mai rapid R-CNN este optimizat pentru o funcție de pierdere multi-sarcină, similar cu rapid R-CNN.
| simbol | explicație |
| \(p_i\) | Probabilitatea prezisă ca ancora i să fie un obiect. |
| \(p^*_i\) | etichetă de adevăr la sol (binar) dacă ancora i este un obiect. |
| \(t_i\) | a prezis patru coordonate parametrizate. |
| \(t^*_i\) | coordonatele adevărului la sol. |
| \(n_\text{cls}\) | termen de normalizare, setat la dimensiunea mini-lot (~256) în lucrare. |
| \(n_\text{box}\) | termen normalizare, setat la numărul de locații de ancorare (~2400) în lucrare. |
| \(\lambda\) | un parametru de echilibrare, setat la ~10 în lucrare (astfel încât ambii termeni \(\mathcal{l}_\text{cls}\) și \(\mathcal{l}_\text{box}\) sunt aproximativ la fel de ponderați). |
funcția multi-task loss combină pierderile de clasificare și regresia casetei de încadrare:
\
unde \(\mathcal{l}_\text{cls}\) este funcția log loss pe două clase, deoarece putem traduce cu ușurință o clasificare multi-clasă într-o clasificare binară un eșantion fiind un obiect țintă versus NU. \(L_1 ^ \ text{smooth}\) este pierderea L1 netedă.
\
masca R-CNN
masca R-CNN (el și colab., 2017) extinde mai rapid R-CNN la segmentarea imaginii la nivel de pixeli. Punctul cheie este decuplarea clasificării și a sarcinilor de predicție a măștii la nivel de pixeli. Pe baza cadrului R-CNN mai rapid, a adăugat o a treia ramură pentru prezicerea unei măști de obiecte în paralel cu ramurile existente pentru clasificare și localizare. Ramura de mască este o mică rețea complet conectată aplicată fiecărui RoI, prezicând o mască de segmentare într-o manieră pixel-la-pixel.
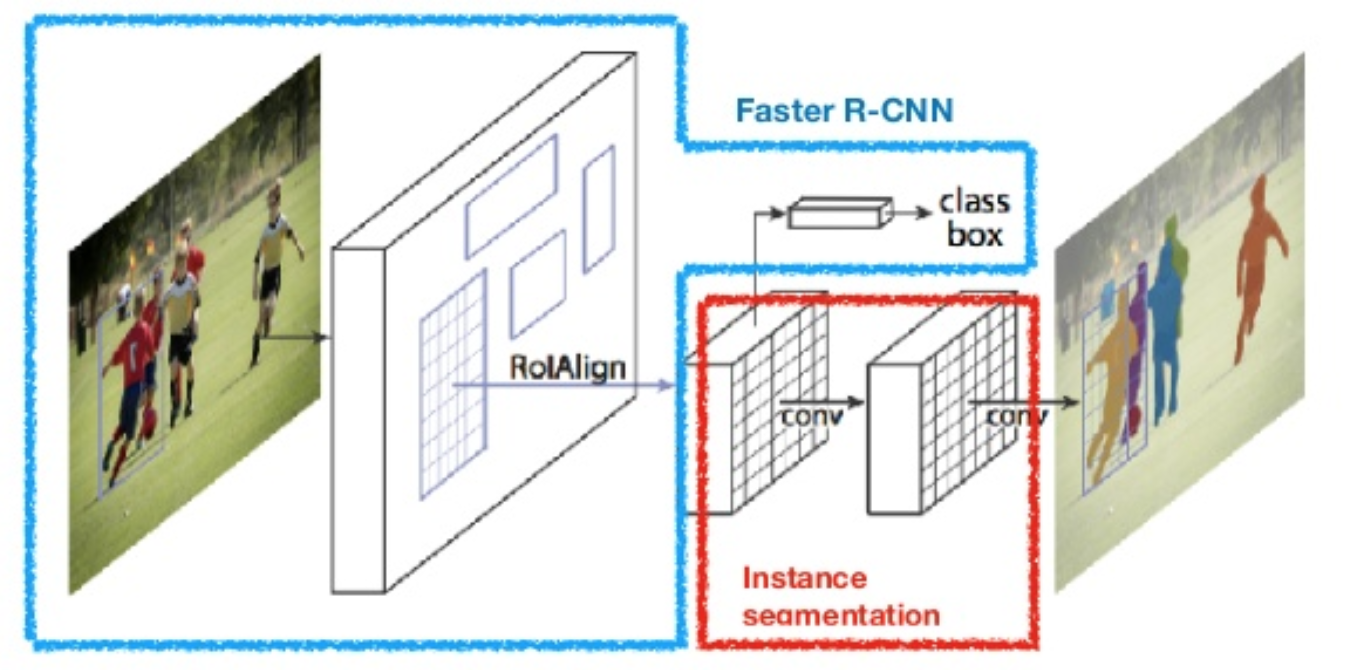
Fig. 8. Masca R-CNN este mai rapid modelul R-CNN cu segmentarea imaginii. (Sursa imaginii: el și colab., 2017)
deoarece segmentarea la nivel de pixeli necesită o aliniere mult mai fină decât casetele de delimitare, mask R-CNN îmbunătățește stratul de punere în comun a RoI (denumit „strat RoIAlign”), astfel încât RoI să poată fi mapat mai bine și mai precis la regiunile imaginii originale.

Fig. 9. Predicții de Mask R-CNN pe setul de testare COCO. (Sursa imaginii: el și colab., 2017)
RoIAlign
stratul RoIAlign este conceput pentru a remedia nealinierea locației cauzată de cuantificare în gruparea RoI. RoIAlign elimină cuantificarea hash , de exemplu, prin utilizarea x/16 în loc de, astfel încât caracteristicile extrase pot fi aliniate în mod corespunzător cu pixelii de intrare. Interpolarea biliniară este utilizată pentru calcularea valorilor de locație în virgulă mobilă din intrare.
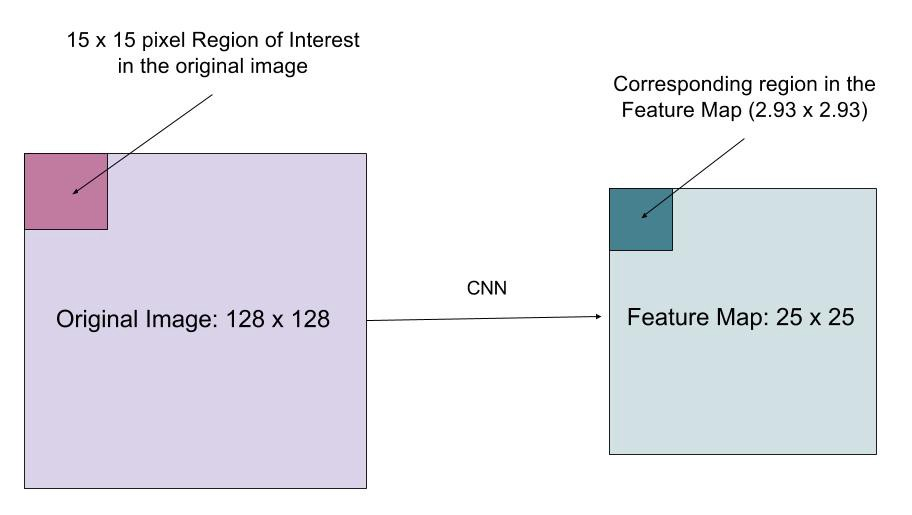
Fig. 10. O regiune de interes este mapată cu precizie din imaginea originală pe harta caracteristică fără rotunjire până la numere întregi. (Sursa imaginii: funcția de pierdere multi-sarcină a măștii R-CNN combină pierderea clasificării, localizării și segmentării măștii: \(\mathcal{l} = \mathcal{l}_\text{cls} + \mathcal{l}_\text{box} + \mathcal{l}_\text{mask}\), unde \(\mathcal{l}_\text{cls}\) și \(\mathcal{l}_\Text{box}\) sunt aceleași ca în mai rapid R-CNN.
ramura mască generează o mască de dimensiune m x m pentru fiecare RoI și fiecare clasă; k clase în total. Astfel, producția totală este de dimensiune \(K \ cdot m^2\). Deoarece modelul încearcă să învețe o mască pentru fiecare clasă, nu există concurență între clase pentru generarea de măști.
\(\mathcal{l}_\text{mask}\) este definită ca pierderea medie binară a entropiei încrucișate, incluzând doar masca k dacă regiunea este asociată cu clasa adevărului de la sol k.
\\]
unde \(Y_{ij}\) este eticheta unei celule (i, j) din masca adevărată pentru regiunea de mărime m x m; \(\hat{y}_{ij}^k\) este valoarea prezisă a aceleiași celule din masca învățat pentru sol-adevăr clasa K.
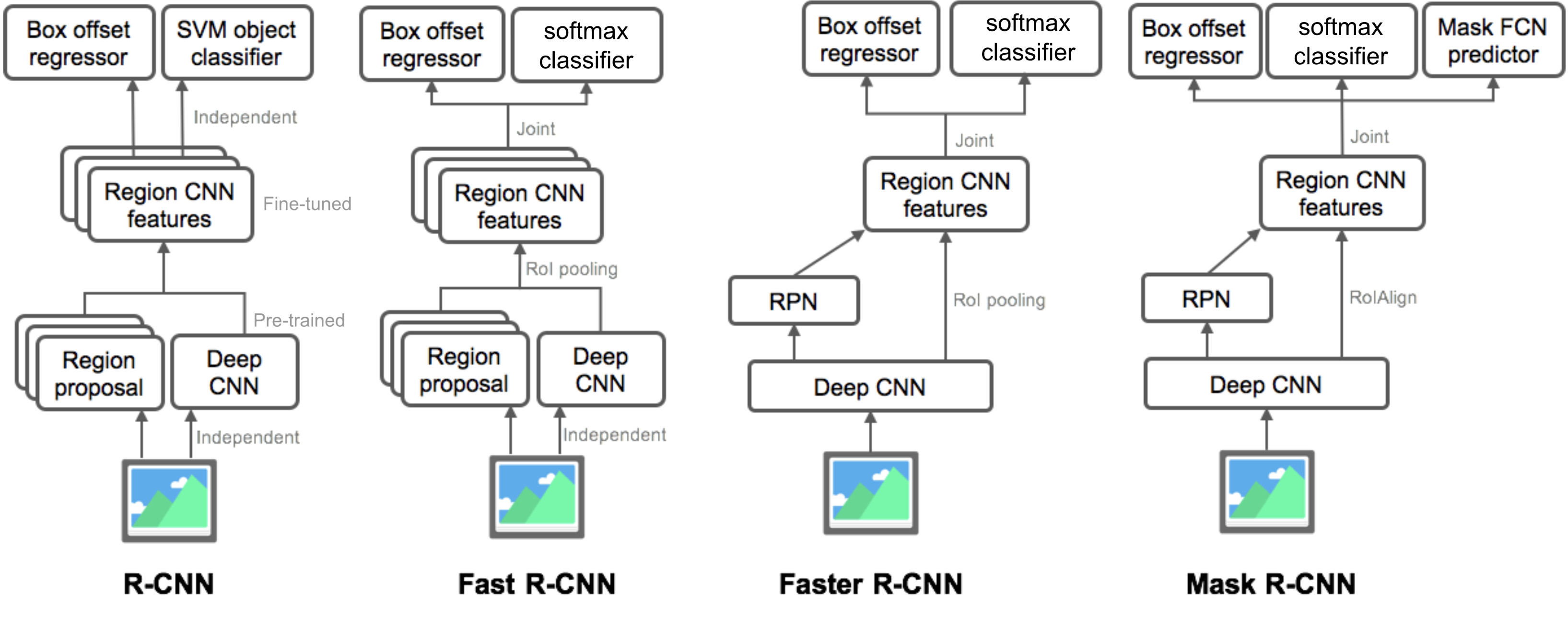
Rezumatul modelelor din familia R-CNN
aici ilustrez modele de modele de R-CNN, Fast R-CNN, Faster R-CNN și Mask R-CNN. Puteți urmări modul în care un model evoluează la următoarea versiune comparând diferențele mici.
citat ca:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}referință
Ross Girshick, Jeff Donahue, Trevor Darrell și Jitendra Malik. „Ierarhii de caracteristici bogate pentru detectarea precisă a obiectelor și segmentarea semantică.”În Proc. IEEE Conf. despre computer vision și pattern recognition (CVPR), PP.580-587. 2014.
Ross Girshick. „Rapid R-CNN.”În Proc. IEEE Intl. Conf. despre viziunea computerului, PP. 1440-1448. 2015.Shaoqing Ren, Kaiming He, Ross Girshick și Jian Sun. „Mai rapid R-CNN: spre detectarea obiectelor în timp real cu rețele de propuneri de regiune.”În progrese în sistemele de procesare a informațiilor neuronale (NIPS), PP.91-99. 2015.
Kaiming He, Georgia Gkioxari, Piotr Doll Ouxtr și Ross Girshick. „Masca R-CNN.”arXiv preimprimare arXiv:1703.06870, 2017.
Joseph Redmon, Santosh Divvala, Ross Girshick și Ali Farhadi. „Arăți o singură dată: detectarea obiectelor unificate, în timp real.”În Proc. IEEE Conf. despre viziunea computerizată și recunoașterea modelelor (CVPR), PP.779-788. 2016.
„o scurtă istorie a CNN-urilor în segmentarea imaginilor: de la R-CNN la masca R-CNN” de Athelas.
pierderea L1 netedă: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf