Noțiuni de bază pentru învățarea întăririi prin procesul de decizie Markov
Acest articol a fost publicat ca parte a Blogathon Data Science.
Introducere
învățarea prin întărire (RL) este o metodologie de învățare prin care elevul învață să se comporte într-un mediu interactiv folosind propriile acțiuni și recompense pentru acțiunile sale. Elevul, adesea numit agent, descoperă ce acțiuni oferă recompensa maximă exploatându-le și explorându-le.

o întrebare cheie este – cum este RL diferit de învățarea supravegheată și nesupravegheată?
diferența vine în perspectiva interacțiunii. Învățarea supravegheată îi spune direct utilizatorului / agentului ce acțiune trebuie să efectueze pentru a maximiza recompensa folosind un set de date de instruire cu exemple etichetate. Pe de altă parte, RL permite direct agentului să folosească recompense (pozitive și negative) pe care le primește pentru a-și selecta acțiunea. Prin urmare, este diferit de învățarea nesupravegheată, deoarece învățarea nesupravegheată se referă la găsirea structurii ascunse în colecțiile de date neetichetate.
formularea învățării întăririi prin procesul de decizie Markov (MDP)
elementele de bază ale unei probleme de învățare a întăririi sunt:
- Mediu: lumea exterioară cu care interacționează agentul
- stat: situația actuală a agentului
- recompensă: semnal de feedback numeric din mediu
- politică: metodă de mapare a stării agentului la acțiuni. O politică este utilizată pentru a selecta o acțiune într-o anumită stare
- valoare: recompensa viitoare (recompensă întârziată) pe care un agent ar primi-o prin luarea unei acțiuni într-o anumită stare
procesul de decizie Markov (MDP) este un cadru matematic pentru a descrie un mediu în învățarea întăririi. Următoarea figură prezintă interacțiunea agent-mediu în MDP:
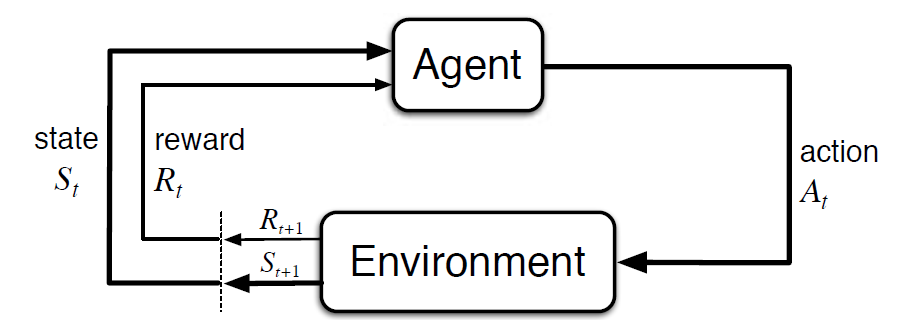
mai precis, agentul și mediul interacționează la fiecare pas de timp discret, t = 0, 1, 2, 3…At fiecare pas de timp, agentul primește informații despre starea de mediu St. pe baza stării de mediu la instant t, agentul alege o acțiune la. În următoarea clipă, agentul primește, de asemenea, un semnal numeric de recompensă Rt+1. Acest lucru dă naștere unei secvențe precum S0, a0, R1, S1, A1, R2…
variabilele aleatoare Rt și St au distribuții de probabilitate discrete bine definite. Aceste distribuții de probabilitate depind numai de starea și acțiunea precedentă în virtutea proprietății Markov. Fie ca S, a și R să fie seturi de stări, acțiuni și recompense. Apoi probabilitatea ca valorile St, Rt și At să ia valorile s’, r și a cu starea anterioară s este dată de,
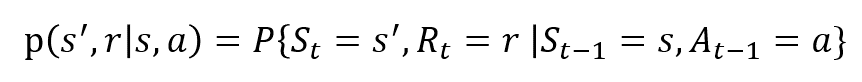
funcția p controlează dinamica procesului.
să înțelegem acest lucru folosind un exemplu
să discutăm acum un exemplu simplu în care RL poate fi utilizat pentru a implementa o strategie de control pentru un proces de încălzire.
ideea este de a controla temperatura unei camere în limitele de temperatură specificate. Temperatura din interiorul camerei este influențată de factori externi, cum ar fi temperatura exterioară, căldura internă generată etc.
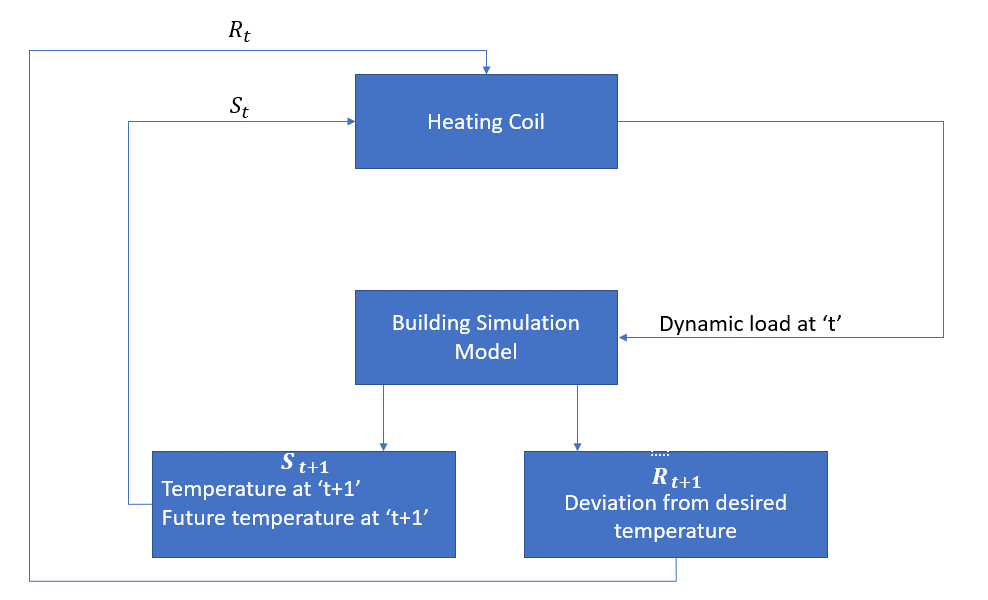
agentul, în acest caz, este bobina de încălzire care trebuie să decidă cantitatea de căldură necesară pentru a controla temperatura din interiorul camerei prin interacțiunea cu mediul și să se asigure că temperatura din interiorul camerei se încadrează în intervalul specificat. Recompensa, în acest caz, este practic costul plătit pentru abaterea de la limitele optime de temperatură.
acțiunea pentru agent este sarcina dinamică. Această sarcină dinamică este apoi alimentată simulatorului camerei, care este practic un model de transfer de căldură care calculează temperatura pe baza sarcinii dinamice. Deci, în acest caz, mediul este modelul de simulare. Variabila de stat St conține recompensele prezente și viitoare.
următoarea diagramă bloc explică modul în care MDP poate fi utilizat pentru controlul temperaturii într-o cameră:
limitările acestei metode
învățarea întăririi învață de la stat. Statul este contribuția pentru elaborarea politicilor. Prin urmare, intrările de stat ar trebui să fie date corect. De asemenea, după cum am văzut, există mai multe variabile, iar dimensionalitatea este imensă. Deci, folosind-o pentru sisteme fizice reale ar fi dificil!
lecturi suplimentare
pentru a afla mai multe despre RL, următoarele materiale ar putea fi de ajutor:
- învățarea întăririi: o introducere de Richard.S. Sutton și Andrew.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- prelegeri Video de David Silver disponibile pe YouTube
- https://gym.openai.com/ este un set de instrumente pentru explorare ulterioară
puteți citi și acest articol în aplicația noastră mobilă![]()
