Un instrument de analiză pap-frotiu (PAT) pentru detectarea cancerului de col uterin din imagini Pap-frotiu
analiza imaginii
conducta de analiză a imaginii pentru dezvoltarea unui instrument de analiză pap-frotiu pentru detectarea cancerului de col uterin din frotiuri pap prezentate în această lucrare este prezentată în Fig. 1.

abordarea pentru a realiza detectarea cancerului de col uterin din imagini Papanicolau
achiziție imagine
abordarea a fost evaluată folosind trei seturi de date. Setul de date 1 este format din 917 celule unice de imagini Papanicolau Harlev pregătite de Jantzen și colab. . Setul de date conține imagini Papanicolau luate cu o rezoluție de 0,201 unqqm/pixel de către citopatologi calificați folosind un microscop conectat la un grabber cadru. Imaginile au fost segmentate folosind software-ul comercial CHAMP și apoi clasificate în șapte clase cu caracteristici distincte, așa cum se arată în tabelul 2. Dintre aceste 200 de imagini au fost folosite pentru instruire și 717 imagini pentru testare.
setul de date 2 este format din 497 de imagini Papanicolau cu diapozitive complete pregătite de Norup și colab. . Dintre aceste 200 de imagini au fost folosite pentru instruire și 297 de imagini pentru testare. În plus, performanța Clasificatorului a fost evaluată pe setul de date 3 din eșantioane de 60 de frotiuri Papanicolau (30 normale și 30 anormale) obținute de la Spitalul Regional de recomandare Mbarara (MRRH). Specimenele au fost imaginate folosind un microscop Olympus Bx51 cu câmp luminos echipat cu un obiectiv de 40 de ani, 0,95 NA și o cameră monocromă Hamamatsu ORCA-05G de 1,4 Mpx, oferind o dimensiune a pixelilor de 0,25 de ani cu adâncime gri de 8 biți. Fiecare imagine a fost apoi împărțită în 300 de zone, fiecare zonă conținând între 200 și 400 de celule. Pe baza opiniilor citopatologilor, au fost selectate 10.000 de obiecte din imagini derivate din cele 60 de diapozitive Papanicolau diferite, dintre care 8000 au fost celule epiteliale cervicale libere (3000 de celule normale din frotiuri normale și 5000 de celule anormale din frotiuri anormale), iar restul de 2000 au fost obiecte de resturi. Această segmentare pap-frotiu a fost realizată folosind setul de instrumente de segmentare Weka Trainable pentru a construi un clasificator de segmentare la nivel de pixeli.
image enhancement
o egalizare a histogramei adaptive locale de contrast (CLAHE) a fost aplicată imaginii în tonuri de gri pentru îmbunătățirea imaginii . În CLAHE, selecția clip-limit care specifică forma dorită a histogramei imaginii este primordială, deoarece influențează critic calitatea imaginii îmbunătățite. Valoarea optimă a limitei de clip a fost selectată empiric folosind metoda definită de Joseph și colab. . O valoare limită optimă a clipului de 2.0 a fost determinat să fie adecvat pentru a oferi o îmbunătățire adecvată a imaginii, păstrând în același timp caracteristicile întunecate pentru seturile de date utilizate. Conversia în tonuri de gri a fost realizată folosind o tehnică în tonuri de gri implementată folosind Eq. 1 așa cum este definit în .
unde R = roșu, g = verde și B = contribuții de culoare albastră la noua imagine.
aplicarea CLAHE pentru îmbunătățirea imaginii a dus la modificări vizibile ale imaginilor prin ajustarea intensităților imaginii în care întunecarea nucleului, precum și limitele citoplasmei, au devenit ușor de identificat folosind o limită de clip de 2,0.
segmentarea scenei
pentru a realiza segmentarea scenei, a fost dezvoltat un clasificator de nivel pixel folosind setul de instrumente de segmentare Weka (TWS) Trainable. Majoritatea celulelor observate într-un frotiu Papanicolau nu sunt surprinzător de celule epiteliale cervicale . În plus, un număr variabil de leucocite, eritrocite și bacterii sunt de obicei evidente, în timp ce uneori se observă un număr mic de alte celule contaminante și microorganisme. Cu toate acestea, frotiul Papanicolau conține patru tipuri majore de celule cervicale scuamoase-superficiale, intermediare, parabazale și bazale—dintre care celulele superficiale și intermediare reprezintă majoritatea covârșitoare într—un frotiu convențional; prin urmare, aceste două tipuri sunt de obicei utilizate pentru o analiză convențională a frotiului Papanicolau . O segmentare Weka antrenabilă a fost utilizată pentru a identifica și segmenta diferitele obiecte de pe diapozitiv. În această etapă, un clasificator de nivel de pixeli a fost instruit pe nucleele celulare, citoplasma, identificarea fundalului și a resturilor cu ajutorul unui citopatolog calificat care utilizează setul de instrumente de segmentare Weka (TWS) Trainable . Acest lucru a fost realizat prin trasarea liniilor/selecției prin zonele de interes și atribuirea acestora unei anumite clase. Pixelii de sub linii / selecție au fost considerați reprezentativi pentru nuclee, citoplasmă, fundal și resturi.
contururile trasate în cadrul fiecărei clase au fost folosite pentru a genera un vector caracteristică, \(\mathop F\limits^{ \to }\) care a fost derivat din numărul de pixeli aparținând fiecărui contur. Vectorul de caracteristici din fiecare imagine (200 din setul de date 1 și 200 din setul de date 2) a fost definit de Eq. 2.
unde Ni, Ci, Bi și Di sunt numărul de pixeli din nucleu, citoplasmă, fundal și resturi ale imaginii \(i\) așa cum se arată în Fig. 2.

generarea vectorului de caracteristici din imaginile de antrenament
fiecare pixel extras din imagine reprezintă nu numai intensitatea sa, ci și un set de caracteristici de imagine care conțin o o mulțime de informații, inclusiv textura, marginile și culoarea într-o zonă de pixeli de 0,201 unktcm2. Alegerea unui vector de caracteristici adecvat pentru instruirea Clasificatorului a fost o mare provocare și o sarcină nouă în abordarea propusă. Clasificatorul de nivel pixel a fost instruit folosind un total de 226 de caracteristici de instruire de la TWS. Clasificatorul a fost instruit folosind un set de caracteristici de instruire TWS care includeau: (i) reducerea zgomotului: Kuwahara și filtrele bilaterale din setul de instrumente TWS au fost utilizate pentru a instrui clasificatorul cu privire la eliminarea zgomotului. S-a raportat că acestea sunt filtre excelente pentru eliminarea zgomotului, păstrând în același timp marginile, (ii) detectarea marginilor: un filtru Sobel, matricea hessiană și filtrul Gabor au fost utilizate pentru instruirea Clasificatorului la detectarea limitelor într-o imagine și (iii) filtrarea texturii: Pentru filtrarea texturii au fost utilizate filtrele medii, varianță, mediană, maximă, minimă și entropie.
îndepărtarea resturilor
principalul motiv pentru limitările actuale ale multor sisteme automate de analiză Papanicolau existente este că se luptă să depășească complexitatea structurilor Papanicolau, încercând să analizeze diapozitivul în ansamblu, care conțin adesea mai multe celule și resturi. Acest lucru are potențialul de a provoca eșecul algoritmului și necesită o putere de calcul mai mare . Probele sunt acoperite de artefacte—cum ar fi celulele sanguine, celulele suprapuse și pliate și bacteriile-care împiedică procesele de segmentare și generează un număr mare de obiecte suspecte. S-a demonstrat că clasificatorii concepuți pentru a diferenția între celulele normale și celulele precanceroase produc de obicei rezultate imprevizibile atunci când există artefacte în frotiul Papanicolau . În acest instrument, o tehnică de identificare a celulelor cervicale utilizând o schemă de eliminare secvențială trifazată (descrisă în Fig. 3) este folosit.

abordare de eliminare secvențială trifazată pentru respingerea resturilor
schema de eliminare trifazată propusă elimină secvențial resturile din testul Papanicolau dacă se consideră improbabil pentru a fi o celulă de col uterin. Această abordare este benefică, deoarece permite luarea unei decizii cu dimensiuni inferioare în fiecare etapă.
analiza dimensiunii
analiza dimensiunii este un set de proceduri pentru determinarea unei game de măsurători ale dimensiunii particulelor . Zona este una dintre cele mai de bază caracteristici utilizate în domeniul citologiei automate pentru a separa celulele de resturi. Analiza Papanicolau este un domeniu bine studiat, cu multe cunoștințe anterioare privind proprietățile celulare . Cu toate acestea, una dintre modificările cheie cu evaluarea zonei nucleului este că celulele canceroase suferă o creștere substanțială a dimensiunii nucleare . Prin urmare, determinarea unui prag de dimensiune superioară care nu exclude sistematic celulele de diagnostic este mult mai dificilă, dar are avantajul de a reduce spațiul de căutare. Metoda prezentată în această lucrare se bazează pe o dimensiune mai mică și un prag de dimensiune superioară a celulelor cervicale. Codul pseudo pentru abordare este prezentat în Eq. 3.
unde \(Area_{max} = 85,267\,{\upmu \text{m}}^{2}\) și \(Area_{min} = 625\,{\upmu \text{m}}^{2}\) derivate din tabelul 2.
obiectele din fundal sunt considerate resturi și astfel aruncate din imagine. Particulele care se încadrează între \(Area_{min}\) și \(Area_{max}\) sunt analizate în etapele următoare ale analizei texturii și formei.
analiza formei
forma obiectelor dintr-un frotiu Papanicolau este o caracteristică cheie în diferențierea dintre celule și resturi . Există o serie de metode pentru detectarea descrierii formei și acestea includ abordări bazate pe regiune și pe contur . Metodele bazate pe regiuni sunt mai puțin sensibile la zgomot, dar mai intensive din punct de vedere al calculului, în timp ce metodele bazate pe contur sunt relativ eficiente de calculat, dar mai sensibile la zgomot . În această lucrare, a fost utilizată o metodă bazată pe regiune (perimeter2/area (P2A)). Descriptorul P2A a fost ales pe meritul că descrie asemănarea unui obiect cu un cerc. Acest lucru îl face potrivit ca descriptor al nucleului celular, deoarece nucleele sunt în general circulare în aspectul lor. P2A este, de asemenea, menționată ca forma compactitate și este definit de Eq. 4.
unde c este valoarea compactității formei, A este zona și p este perimetrul nucleului. Resturile s-au presupus a fi obiecte cu o valoare P2A mai mare de 0,97 sau mai mică de 0,15 conform caracteristicilor de antrenament (descrise în tabelul 2).
analiza texturii
textura este o caracteristică caracteristică foarte importantă care poate face diferența între nuclee și resturi. Textura imaginii este un set de valori concepute pentru a cuantifica textura percepută a unei imagini . Într-un frotiu Papanicolau, distribuția intensității medii a petelor nucleare este mult mai restrânsă decât variația intensității petelor între obiectele de resturi . Acest fapt a fost folosit ca bază pentru îndepărtarea resturilor pe baza intensităților imaginii și a informațiilor despre culoare folosind momentele Zernike (ZM) . Momentele Zernike sunt utilizate pentru o varietate de aplicații de recunoaștere a modelelor și sunt cunoscute a fi robuste în ceea ce privește zgomotul și pentru a avea o putere bună de reconstrucție. În această lucrare, ZM prezentat de Malm și colab. de ordinul n cu repetarea i a funcției \(f \ stânga ({r, \ theta } \ dreapta)\), în coordonate polare în interiorul unui disc centrat în imagine pătrată\(i \stânga( {x,y}\ dreapta)\) de dimensiune \(M\ ori m\) dată de Eq. 5 a fost folosit.
\(v_{nl }^{*} \stânga( {r,\Theta } \dreapta)\) denotă conjugatul complex al polinomului Zernike \(V_{nl} \stânga( {r,\Theta } \dreapta)\). Pentru a produce o măsură de textură, magnitudinile din \(a_{nl}\) centrate la fiecare pixel din imaginea texturii sunt medii .
extragerea caracteristicilor
succesul unui algoritm de clasificare depinde foarte mult de corectitudinea caracteristicilor extrase din imagine. Celulele din frotiurile Papanicolau din setul de date utilizat sunt împărțite în șapte clase pe baza caracteristicilor precum dimensiunea, aria, forma și luminozitatea nucleului și citoplasmei. Caracteristicile extrase din imagini includeau caracteristici morfologice utilizate anterior de alții . În această lucrare trei caracteristici geometrice (soliditate, compactitate și excentricitate) și șase caracteristici textuale (medie, deviație standard, varianță, netezime, energie și entropie) au fost, de asemenea, extrase din nucleu, rezultând 29 de caracteristici în total, așa cum se arată în tabelul 3.
selecție caracteristică
selecția caracteristică este procesul de selectare subseturi ale caracteristicilor extrase care dau cele mai bune rezultate de clasificare. Printre aceste caracteristici extrase, unele ar putea conține zgomot în timp ce clasificatorul ales nu poate utiliza altele. Prin urmare, trebuie determinat un set optim de caracteristici, eventual prin încercarea tuturor combinațiilor. Cu toate acestea, atunci când există multe caracteristici, combinațiile posibile explodează în număr și acest lucru crește complexitatea computațională a algoritmului. Algoritmii de selecție a caracteristicilor sunt clasificați în general în filtru, înveliș și metode încorporate .
metoda utilizată de instrument combină recoacerea simulată cu o abordare a învelișului. Această abordare a fost propusă în dar, în această lucrare, performanța selecției caracteristicilor este evaluată folosind un algoritm forestier aleatoriu cu strategie dublă . Recoacerea simulată este o tehnică probabilistică pentru aproximarea optimului global al unei funcții date. Abordarea este potrivită pentru a se asigura că este selectat setul optim de caracteristici. Căutarea setului optim este ghidată de o valoare de fitness . Când recoacerea simulată este terminată, toate diferitele subseturi de caracteristici sunt comparate și cel mai adaptat (adică cel care are cele mai bune performanțe) selectat. Căutarea valorii de fitness a fost obținută cu un înveliș în care validarea încrucișată k-fold a fost utilizată pentru a calcula eroarea pe algoritmul de clasificare. Diferite combinații din caracteristicile extrase sunt pregătite, evaluate și comparate cu alte combinații. Un model predictiv este apoi utilizat pentru a evalua o combinație de caracteristici și pentru a atribui un scor bazat pe precizia modelului. Eroarea de fitness dată de înveliș este utilizată ca eroare de fitness de către algoritmul de recoacere simulat. Un algoritm fuzzy c-means a fost înfășurat într-o cutie neagră, din care a fost obținută o eroare estimată pentru diferitele combinații de caracteristici așa cum se arată în Fig. 4.

fuzzy c-means este înfășurat într-o cutie neagră din care se obține o eroare estimată
Fuzzy c-means permite Puncte de date în setul de date să aparțină tuturor clusterelor, cu abonamente în intervalul (0-1) așa cum se arată în EQ. 6.
unde \(m_{ik}\) este calitatea de membru pentru punctul de date k la Centrul de cluster i, \(D_{jk}\) este Distanța de la Centrul de cluster j la punctul de date k și q. Algoritmul fuzzy c-means a fost implementat folosind caseta de instrumente fuzzy din Matlab.
defuzzificarea
un algoritm fuzzy c-means nu ne spune ce informații conțin clusterele și cum trebuie utilizate aceste informații pentru clasificare. Cu toate acestea, definește modul în care punctele de date sunt atribuite membrilor diferitelor clustere și acest membru fuzzy este utilizat pentru a prezice clasa unui punct de date . Acest lucru este depășit prin defuzzificare. Există o serie de metode de defuzzificare . Cu toate acestea, în acest instrument, fiecare cluster are un membru fuzzy (0-1) din toate clasele din imagine. Datele de instruire sunt atribuite clusterului cel mai apropiat de acesta. Procentul de date de instruire din fiecare clasă aparținând clusterului a dă apartenența clusterului, clusterul a = diferitelor clase, unde i este izolarea în clusterul a și j în celălalt cluster. Măsura de intensitate se adaugă la funcția de membru pentru fiecare cluster folosind un algoritm de defuzzy clustering defuzzy. O abordare populară pentru defuzzificarea partiției fuzzy este aplicarea principiului gradului maxim de membru în care punctul de date k este atribuit clasei m dacă și numai dacă gradul său de membru \(m_{ik}\) La cluster i, este cel mai mare. Chuang și colab. a propus ajustarea statutului de membru al fiecărui punct de date folosind statutul de membru al vecinilor săi.
în abordarea propusă, o metodă de defuzzificare bazată pe Probabilitatea Bayesiană este utilizată pentru a genera un model probabilistic al funcției de membru pentru fiecare punct de date și pentru a aplica modelul imaginii pentru a produce informațiile de clasificare. Modelul probabilistic este calculat după cum urmează:
-
convertiți distribuțiile de posibilități din matricea de partiții (clustere) în distribuții de probabilitate.
-
construiți un model probabilistic al distribuțiilor de date ca în .
-
aplicați modelul pentru a produce informațiile de clasificare pentru fiecare punct de date folosind Eq. 7.
unde \(p\stânga( {a_{I} } \dreapta),i = 0 \ldots .C\) este probabilitatea anterioară a \(a_{i}\) care poate fi calculată folosind metoda în care probabilitatea anterioară este întotdeauna proporțională cu masa fiecărei clase.
Numărul de clustere de utilizat a fost determinat pentru a se asigura că modelul construit poate descrie datele în cel mai bun mod posibil. Dacă sunt alese prea multe clustere, atunci există riscul de suprasolicitare a zgomotului din date. Dacă sunt alese prea puține clustere, atunci un clasificator slab ar putea fi rezultatul. Prin urmare, a fost efectuată o analiză a numărului de clustere în raport cu eroarea testului de validare încrucișată. A fost atins un număr optim de 25 de clustere, iar supraantrenarea a avut loc peste acest număr de clustere. Un exponent defuzzification de 1.0930 a fost obținut cu 25 de clustere, validare încrucișată de zece ori și 60 de reluări și a fost utilizat pentru a calcula eroarea de fitness pentru selectarea caracteristicilor, unde un total de 18 caracteristici din cele 29 de caracteristici au fost selectate pentru construirea Clasificatorului. Caracteristicile selectate au fost: zona nucleului; nivelul nucleului gri; diametrul cel mai scurt al nucleului; nucleul cel mai lung; perimetrul nucleului; maxime în nucleu; minime în nucleu; zona citoplasmei; nivelul citoplasmei gri; perimetrul citoplasmei; raportul nucleu – citoplasmă; excentricitatea nucleului, abaterea standard a nucleului, varianța nivelului nucleului gri; entropia nivelului nucleului gri; poziția relativă a nucleului; nivelul mediu al nucleului gri și valorile nucleului gri energie.
evaluarea clasificării
în această lucrare, modelul ierarhic al eficacității sistemelor imagistice de diagnostic propus de Fryback și Thornbury a fost adoptat ca principiu director pentru evaluarea instrumentului așa cum se arată în tabelul 4.
sensibilitatea măsoară proporția de pozitive reale care sunt identificate corect ca atare, în timp ce specificitatea măsoară proporția de negative reale care sunt identificate corect ca atare. Sensibilitatea și specificitatea sunt descrise de Eq. 8.
unde TP = pozitive adevărate, FN = negative False, TN = negative adevărate și FP = pozitive False.
proiectare și integrare GUI
metodele de procesare a imaginilor descrise mai sus au fost implementate în Matlab și sunt executate printr-o interfață grafică de utilizator Java (gui) prezentată în Fig. 5. Instrumentul are un panou în care este încărcată o imagine Papanicolau și citotehnicianul Selectează o metodă adecvată pentru segmentarea scenei (bazată pe clasificatorul TWS), îndepărtarea resturilor (bazată pe abordarea cu trei eliminări secvențiale) și detectarea limitelor (dacă se consideră necesar, folosind metoda de detectare a marginilor Canny), după care caracteristicile sunt extrase folosind butonul extract features.
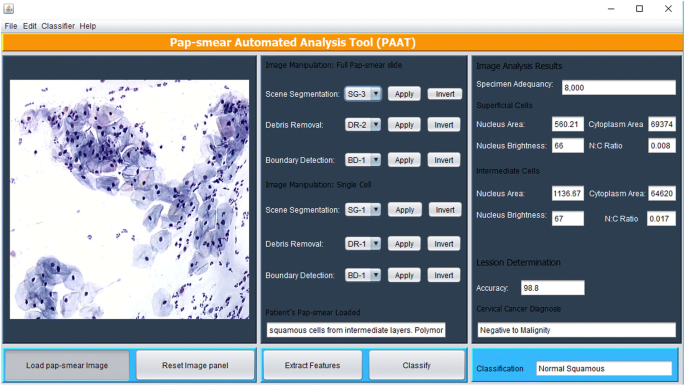
PAT interfață grafică de utilizator
Instrumentul scanează prin Pap-frotiu pentru a analiza toate obiectele care au rămas după îndepărtarea resturilor. Cele 18 caracteristici descrise în selectarea caracteristicilor sunt extrase din fiecare obiect și utilizate pentru a clasifica fiecare celulă folosind algoritmul fuzzy c-means descris în metoda de clasificare. Aleatoriu, caracteristicile extrase ale unei celule superficiale și ale unei celule intermediare sunt afișate în panoul rezultatelor analizei imaginii. Odată ce caracteristicile au fost extrase, citotehnicianul (utilizatorul) apasă butonul de clasificare și instrumentul emite un diagnostic (pozitiv la malignitate sau negativ la malignitate) și clasifică diagnosticul la una dintre cele 7 clase/etape ale cancerului de col uterin conform setului de date de formare.