seaborn.histplot¶
seaborn.histplot(data=Geen, *, x=Geen, y=Geen, hue=Geen, gewicht=Geen, stat=’aantal’, silo ‘ =’auto’, binwidth=Geen, binrange=Geen, discrete=Geen, cumulatief=Onwaar, common_bins=True, common_norm=True, meerdere=’laag’, element=’bars’, vul=True, krimpen=1, kde=False, kde_kws=Geen, line_kws=Geen, dorsen=0, pthresh=Geen, pmax=Geen, cbar=False, cbar_ax=Geen, cbar_kws=Geen, palet=Geen, hue_order=Geen, hue_norm=Geen, kleur=Geen, log_scale=Geen, legend=True, ax=Geen, **kwargs)¶
Plot univariate of bivariate histogrammen tonen distributies van gegevensreeks.
een histogram is een klassieke visualisatietool die de verdeling van een of meer variabelen weergeeft door het aantal waarnemingen te tellen die met afzonderlijke bakken vallen.
Deze functie kan de in elke bin berekende statistiek normaliseren om Frequentie, dichtheid of waarschijnlijkheidsmassa te schatten, en het kan een vloeiende kromme toevoegen die is verkregen met behulp van een schatting van de kerneldichtheid, vergelijkbaar met kdeplot().
meer informatie vindt u in de gebruikershandleiding.
Parameters datapandas.DataFramenumpy.ndarray, mapping, or sequence
input data structure. Ofwel een lange-vorm collectie van vectoren die kunnen worden ondertekend aan benoemde variabelen of een breed-vorm dataset die intern zal worden geherformuleerd.
X, yvectors of sleutels indata
variabelen die posities op de x-en y-assen specificeren.
huevector of sleutel indata
semantische variabele die is toegewezen om de kleur van plotelementen te bepalen.
gewichtsvector of sleutel indata
indien gegeven, de bijdrage van het corresponderende gegevenspunt naar de telling in elke bak met deze factoren afwegen.
stat {“count”, “frequency”, “density”, “probability”}
geaggregeerde statistiek om in elke bin te berekenen.
-
counttoont het aantal waarnemingen -
frequencytoont het aantal waarnemingen gedeeld door het bin breedte -
densitynormaliseert telt dus dat de oppervlakte van het histogram 1 -
probabilitynormaliseert telt zo dat de som van de bar heights is 1
binsstr, getal, vector, of een paar van dergelijke waarden
Algemene bin parameter, die u de naam van een referentie-regel,het aantal bins, of de einden van de bakken.Doorgegeven aan numpy.histogram_bin_edges().
binwidthnumber of paar getallen
breedte van elke bin, overschrijft bins maar kan worden gebruikt metbinrange.
binrangepair van getallen of een paar paren
laagste en hoogste waarde voor bin-randen; kan worden gebruikt met bins of binwidth. Standaard data extremen.
discretebool
indien waar, standaard binwidth=1 en teken de balken zo dat ze worden gecentreerd op hun overeenkomstige gegevenspunten. Dit vermijdt “hiaten” die anders kunnen verschijnen bij het gebruik van discrete (integer) gegevens.
cumulatief blok
indien waar, plot de cumulatieve tellingen als bakken toenemen.
common_binsbool
indien waar, gebruik dezelfde bins wanneer semantische variabelen multipleplots produceren. Als een referentieregel wordt gebruikt om de bakken te bepalen, wordt deze berekend met de volledige dataset.
common_normbool
indien waar en met behulp van een genormaliseerde statistiek, zal de normalisatie van toepassing zijn over de volledige dataset. Anders, normaliseren elk histogram onafhankelijk.
multiple {“layer”, “dodge”, “stack”, “fill”}
aanpak voor het oplossen van meerdere elementen wanneer semantische toewijzing subsets creëert.Alleen relevant voor univariate data.
element {“bars”, “step”, “poly”}
Visuele weergave van de histogram statistiek.Alleen relevant voor univariate data.
fillbool
indien waar, vul de spatie in onder het histogram.Alleen relevant voor univariate data.
shrinknumber
schalen de breedte van elke bar ten opzichte van de binbreedte met deze factor.Alleen relevant voor univariate data.
kdebool
indien True, Bereken een schatting van de kerneldichtheid om de distributie glad te strijken en op de plot te tonen als (een of meer) regel(en).Alleen relevant voor univariate data.
Kde_kwsdict
Parameters die de KDE-berekening bepalen, zoals in kdeplot().
line_kwsdict
Parameters die de KDE visualisatie controleren, doorgegeven aanmatplotlib.axes.Axes.plot().
drempelaantal of geen
cellen met een statistiek kleiner dan of gelijk aan deze waarde zullen transparant zijn.Alleen relevant met bivariate data.
pthreshnumber of geen
zoals thresh, maar een waarde die zodanig is dat cellen met geaggregeerde tellingen(of andere statistieken, indien gebruikt) tot dit deel van het totaal transparant zijn.
pmaxnumber or None
een waarde die het verzadigingspunt voor de kleurenkaart instelt op een waarde die zodanig is dat onderstaande cellen dit deel van het totale aantal vormen (of een andere statistiek, indien gebruikt).
cbarbool
indien ingeschakeld, voeg een kleurbalk toe om de kleurtoewijzing in een bivariate plot te annoteren.Opmerking: ondersteunt momenteel geen plots met een hue variabele well.
cbar_axmatplotlib.axes.Axes
bestaande assen voor de kleurbalk.
Cbar_kwsdict
aanvullende parameters doorgegeven aan matplotlib.figure.Figure.colorbar().
palettestring, list, dict, or
matplotlib.colors.Colormap
methode voor het kiezen van de kleuren die gebruikt worden bij het toewijzen van de hue semantisch.Tekenreekswaarden worden doorgegeven aan color_palette(). Lijst of dict-waardeenimply categorische toewijzing, terwijl een kleurenkaart-object numerieke toewijzing impliceert.
hue_ordervector van strings
specificeer de volgorde van verwerking en plotten voor categorische niveaus van dehue semantisch.
hue_normtuple ofmatplotlib.colors.Normalize
ofwel een paar waarden die het normalisatiebereik in data-eenheden instellen of een object dat van data-eenheden in een interval afbeeldt. Het gebruik beperkt numerieke mapping.
colormatplotlib color
enkele kleurspecificatie voor wanneer tintafbeelding niet wordt gebruikt. Anders zal de plot proberen te haken in de matplotlib eigenschap cyclus.
log_scalebool of getal, of paar bools of getallen
Stel een logschaal in op de gegevensas (of assen, met bivariate data) met de gegeven basis (standaard 10), en evalueer de KDE in logruimte.
legendabool
indien onwaar, onderdrukt u de legenda voor semantische variabelen.
axmatplotlib.axes.Axes
bestaande assen voor het perceel. Anders moet matplotlib.pyplot.gca()intern worden aangeroepen.
kwargs
andere trefwoordargumenten worden doorgegeven aan een van de volgende matplotlibfuncties:
-
matplotlib.axes.Axes.bar()(univariate, element=”bars”) -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
Plot univariate of bivariate distributies met behulp van kerneldichtheidsschatting.
rugplot
teken een teek bij elke waarnemingswaarde langs de x-en/of y-assen.
ecdfplot
Plot empirische cumulatieve distributiefuncties.
jointplot
teken een bivariate plot met univariate marginale distributies.
opmerkingen
de keuze van bakken voor het berekenen en plotten van een histogram kan een aanzienlijke invloed hebben op de inzichten die men uit devisualisatie kan putten. Als de bakken te groot zijn, kunnen ze belangrijke functies wissen.Aan de andere kant, bakken die te klein zijn kunnen worden gedomineerd door randomvariabiliteit, het verdoezelen van de vorm van de ware onderliggende distributie. De standaard bin-grootte wordt bepaald met behulp van een referentieregel die afhankelijk is van de steekproefgrootte en variantie. Dit werkt goed in veel gevallen, (dat wil zeggen, met “goed gedragen” gegevens) maar het mislukt in anderen. Het is altijd goed om verschillende binmaten te proberen om er zeker van te zijn dat je niet iets belangrijks mist.Met deze functie kunt u bakken op verschillende manieren opgeven, bijvoorbeeld door het totale aantal te gebruiken bakken in te stellen, de breedte van elke bak of de specifieke locaties waar de bakken moeten breken.
voorbeelden
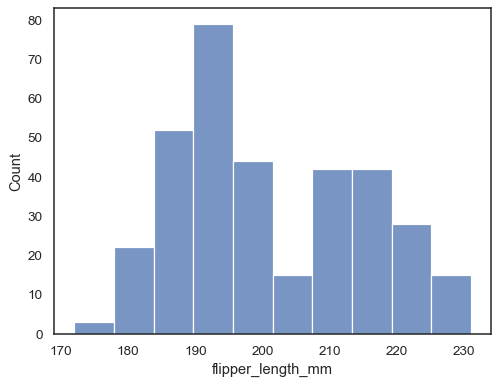
Wijs een variabele toe aan x om een univariate verdeling langs de x-as te plotten:
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
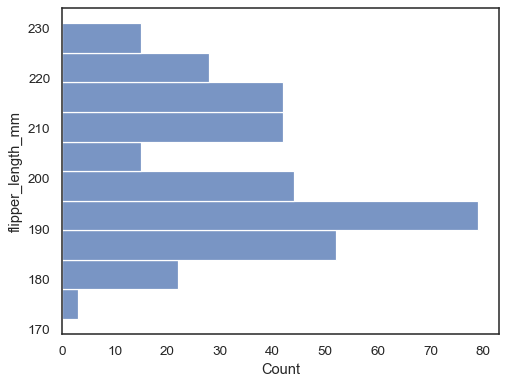
draai de plot om door de gegevensvariabele toe te wijzen aan de y-as:
sns.histplot(data=penguins, y="flipper_length_mm")
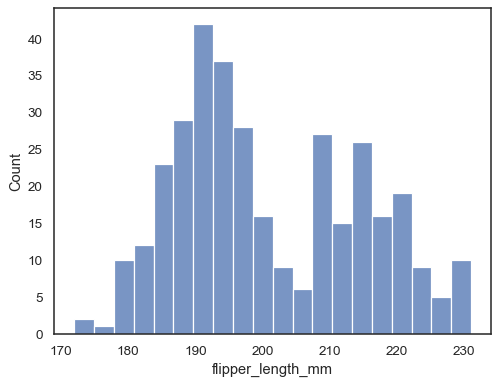
Controleer hoe goed het histogram de gegevens weergeeft door een andere binbreedte op te geven:
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
u kunt ook het totale aantal te gebruiken bins definiëren:
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
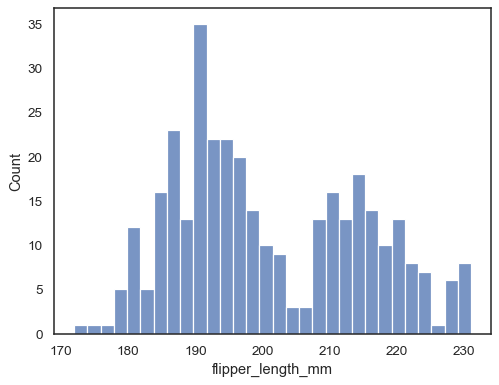
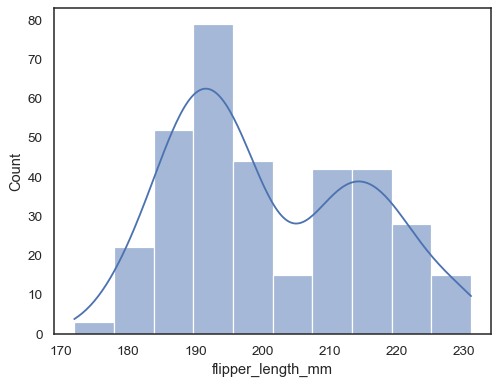
voeg een schatting van de kerneldichtheid toe om het histogram glad te maken, met aanvullende informatie over de vorm van de distributie:
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
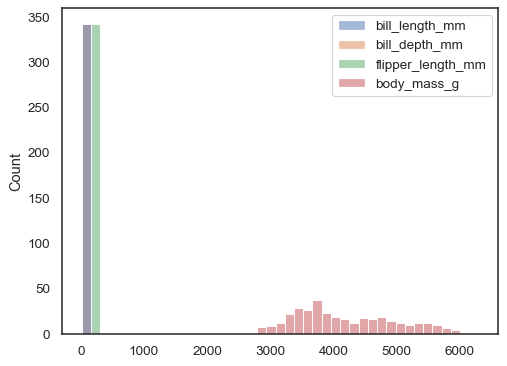
indien noch x noch y is toegewezen, wordt de dataset behandeld als wide-form en wordt voor elke numerieke kolom een histogram getekend:
sns.histplot(data=penguins)
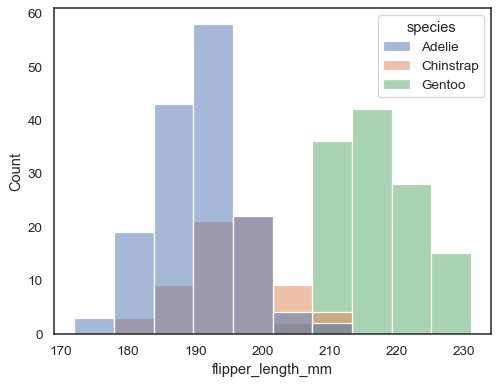
u kunt anders meerdere histogrammen tekenen uit een dataset met lange vorm methue-toewijzing:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
De standaard aanpak voor het plotten van meerdere distributies is om ze te “laag”, maar je kunt ze ook “stack”:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
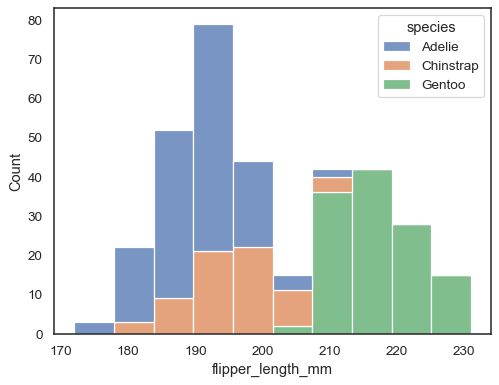
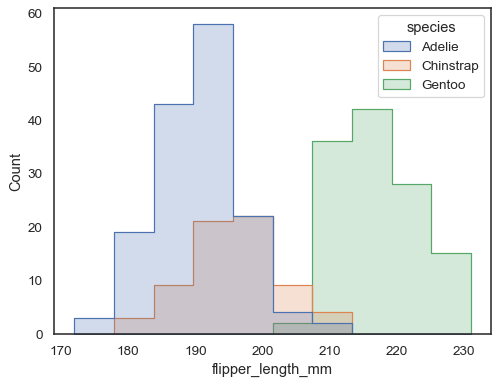
overlappende balken kunnen moeilijk visueel op te lossen zijn. Een andere benadering zou zijn om een step-functie te tekenen:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
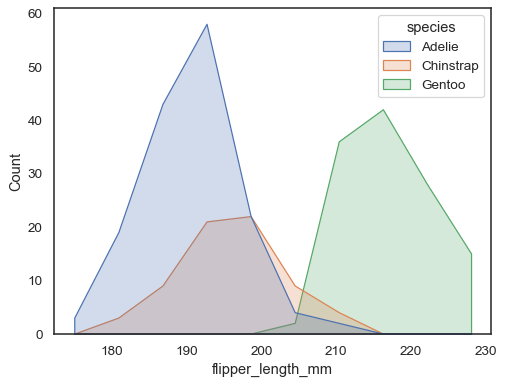
u kunt nog verder weg van bars gaan door een veelhoek te tekenen metvertices in het midden van elke bin. Dit kan het gemakkelijker maken om de vorm van de distributie te zien, maar wees voorzichtig: het zal minder evidouou voor uw publiek dat ze kijken naar een histogram:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
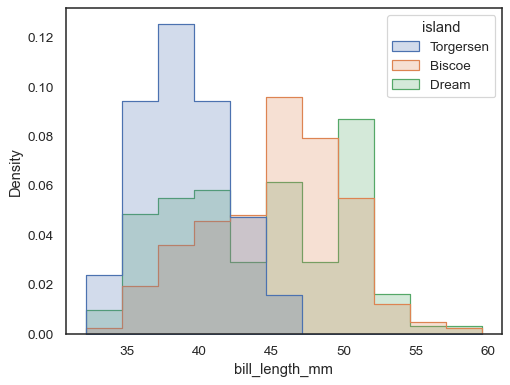
om de verdeling van subsets die wezenlijk verschillen te vergelijken, gebruik independent density normalization:
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
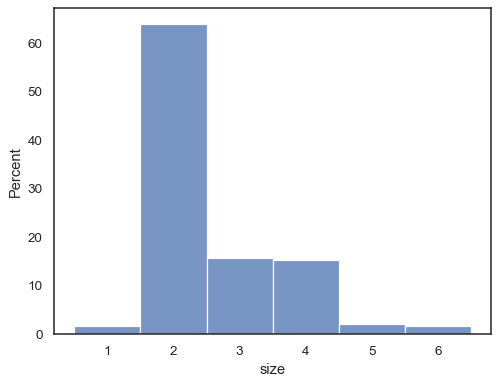
Het is ook mogelijk om zo te normaliseren dat de hoogte van elke maat eenbetekenis laat zien, wat zinvoller is voor discrete variabelen:
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
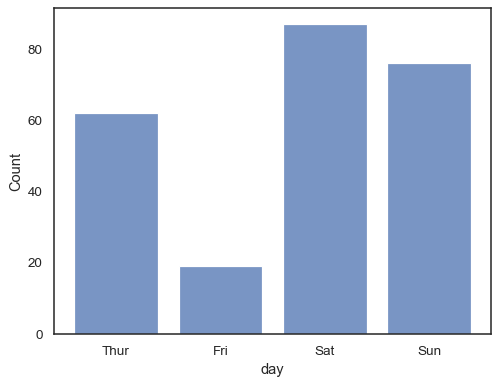
u kunt zelfs een histogram tekenen over categorische variabelen (hoewel dit een experimentele functie is):
sns.histplot(data=tips, x="day", shrink=.8)
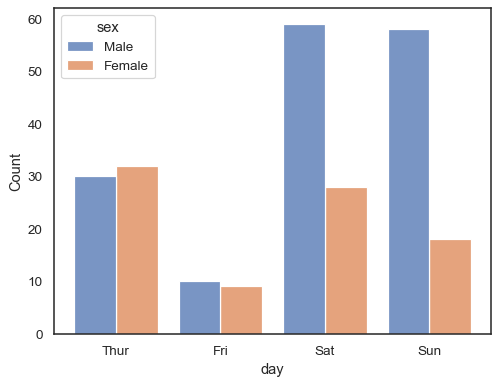
wanneer een hue semantisch met discrete gegevens wordt gebruikt, kan het zinvol zijn om de niveaus te”ontwijken”:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
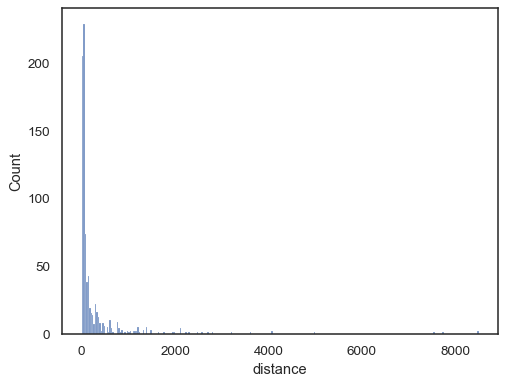
Real-world data is vaak scheef. Voor sterk scheef verdeelde distributies is het beter om de bakken in de logruimte te definiëren. Vergelijken:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
To the log-scale version:
sns.histplot(data=planets, x="distance", log_scale=True)
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
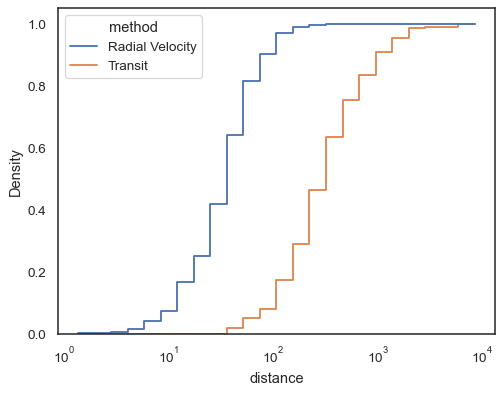
Stapfuncties, esepciaal wanneer ze niet gevuld zijn, maken het gemakkelijk om cumulatieve histogrammen te compareren:
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
wanneer zowel x en y zijn toegewezen, wordt een bivariaathistogram berekend en weergegeven als een heatmap:
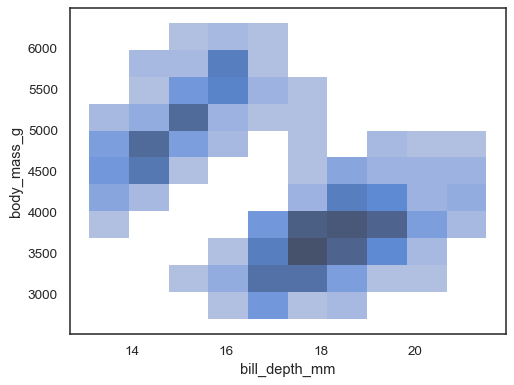
het is mogelijk om ook een hue variabele toe te wijzen, hoewel dit niet goed werkt als gegevens van de verschillende niveaus aanzienlijke overlap hebben:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
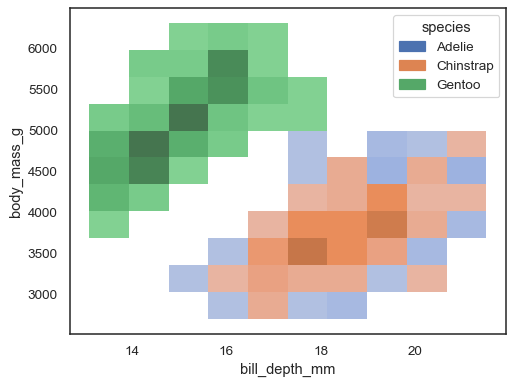
meerdere kleurenafbeeldingen kunnen zinvol zijn wanneer een van de variabelen wordt onderscheiden:
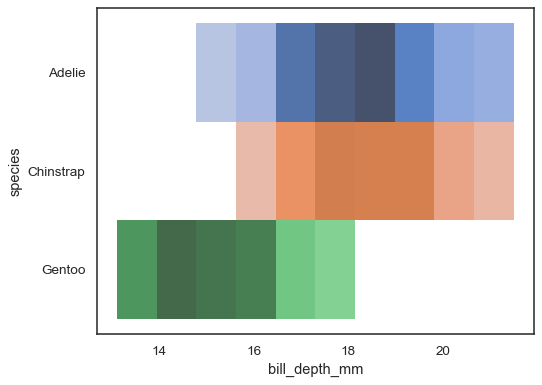
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
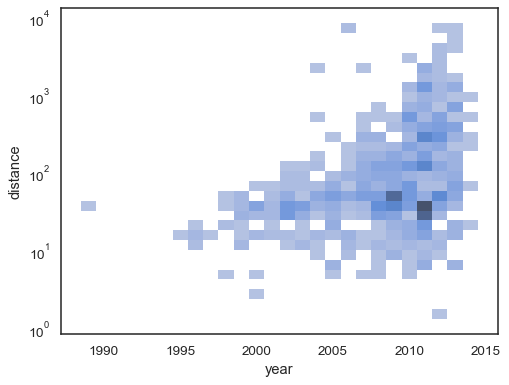
het bivariate histogram accepteert alle dezelfde opties voor berekening als zijn univariate tegenhanger, met tupels om x eny onafhankelijk van elkaar:
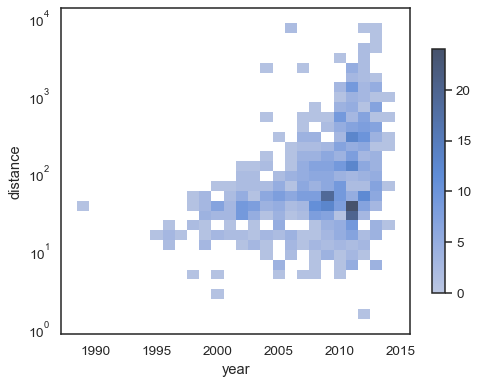
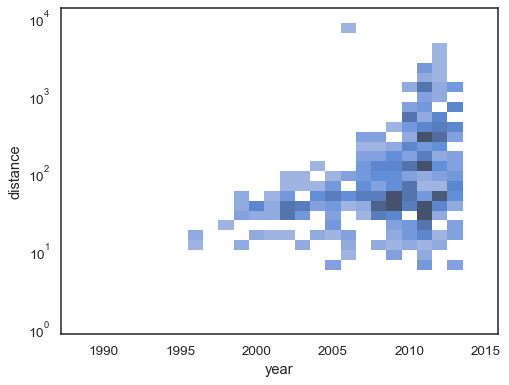
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
het standaardgedrag maakt cellen zonder waarnemingen transparant, hoewel dit kan worden uitgeschakeld:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
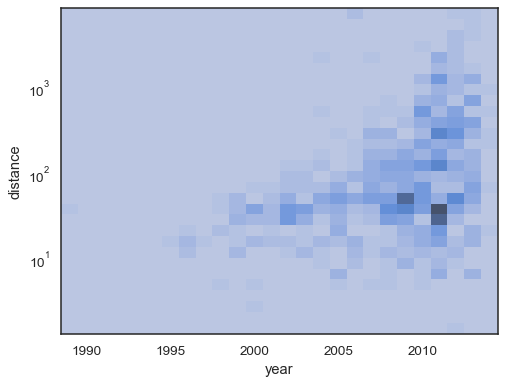
Het is ook mogelijk om de drempelwaarde en het kleurenkaartverzadigingspunt interms in te stellen van de verhouding cumulatieve tellingen:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
om de kleurenkaart te annoteren, voegt u een kleurbalk toe:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)