ett Pap-smear analysis tool (PAT) för detektion av livmoderhalscancer från pap-smear images
bildanalys
bildanalysrörledningen för utveckling av ett Pap-smear analysverktyg för detektion av livmoderhalscancer från pap-smears som presenteras i detta dokument visas i Fig. 1.

tillvägagångssättet för att uppnå upptäckt av livmoderhalscancer från pap-smear-bilder
bildförvärv
tillvägagångssättet bedömdes med tre datamängder. Dataset 1 består av 917 enstaka celler av Harlev pap-smear bilder framställda av Jantzen et al. . Datauppsättningen innehåller pap-smear-bilder som tagits med en upplösning på 0,201 occurm / pixel av skickliga cytopatologer med hjälp av ett mikroskop anslutet till en ramgrabber. Bilderna segmenterades med CHAMP kommersiell programvara och klassificerades sedan i sju klasser med distinkta egenskaper som visas i Tabell 2. Av dessa 200 bilder användes för träning och 717 bilder för testning.
Dataset 2 består av 497 pap-smear-bilder som utarbetats av Norup et al. . Av dessa användes 200 bilder för träning och 297 bilder för testning. Vidare utvärderades klassificerarens prestanda på Dataset 3 av prover av 60 Pap-utstryk (30 normala och 30 onormala) erhållna från Mbarara Regional Referral Hospital (MRRH). Proverna avbildades med hjälp av ett Olympus BX51 ljusfältmikroskop utrustat med en 40 kg, 0,95 NA-lins och en Hamamatsu ORCA-05G 1,4 Mpx monokrom kamera, vilket ger en pixelstorlek på 0,25 kg med 8-bitars grått djup. Varje bild delades sedan upp i 300 områden där varje område innehöll mellan 200 och 400 celler. Baserat på åsikter från cytopatologerna valdes 10 000 objekt i bilder härledda från de 60 olika Pap-smear-bilderna, varav 8000 var fria liggande livmoderhalsepitelceller (3000 normala celler från normala utstryk och 5000 onormala celler från onormala utstryk) och de återstående 2000 var skräpobjekt. Denna Pap-smear segmentering uppnåddes med hjälp av Trainable Weka segmentering toolkit för att konstruera en pixel nivå segmentering klassificerare.
bildförbättring
en kontrast lokal adaptiv histogramutjämning (CLAHE) applicerades på gråskalebilden för bildförbättring . I CLAHE är valet av klippgräns som anger önskad form av bildens histogram av största vikt, eftersom det kritiskt påverkar kvaliteten på den förbättrade bilden. Det optimala värdet av klippgränsen valdes empiriskt med användning av metoden definierad av Joseph et al. . Ett optimalt klippgränsvärde på 2.0 var fast besluten att vara lämplig för att tillhandahålla adekvat bildförbättring samtidigt som de mörka funktionerna för de använda datamängderna bevarades. Omvandling till gråskala uppnåddes med hjälp av en gråskaleteknik implementerad med Eq. 1 enligt definitionen i .
där R = Röd, G = grön och B = blå färg bidrag till den nya bilden.
tillämpning av CLAHE för bildförbättring resulterade i märkbara förändringar i bilderna genom att justera bildintensiteter där mörkningen av kärnan, liksom cytoplasmgränserna, blev lätt identifierbar med hjälp av en klippgräns på 2.0.
Scensegmentering
för att uppnå scensegmentering utvecklades en pixelnivåklassificerare med hjälp av Trainable Weka Segmentation (TWS) toolkit. Majoriteten av celler som observeras i en Pap-smear är inte överraskande livmoderhalsepitelceller . Dessutom är varierande antal leukocyter, erytrocyter och bakterier vanligtvis uppenbara, medan ett litet antal andra förorenande celler och mikroorganismer ibland observeras. Emellertid innehåller Pap-smear fyra huvudtyper av squamous cervical celler-ytliga, mellanliggande, parabasala och basala—varav ytliga och mellanliggande celler representerar den överväldigande majoriteten i ett konventionellt smet; följaktligen används dessa två typer vanligtvis för en konventionell Pap-smear-analys . En träningsbar Weka-segmentering användes för att identifiera och segmentera de olika objekten på bilden. I detta skede utbildades en pixelnivåklassificerare på cellkärnor, cytoplasma, Bakgrunds-och skräpidentifiering med hjälp av en skicklig cytopatolog med hjälp av Trainable Weka Segmentation (TWS) toolkit . Detta uppnåddes genom att rita linjer/urval genom intresseområdena och tilldela dem till en viss klass. Pixlarna under linjerna / urvalet togs för att vara representativa för kärnor, cytoplasma, bakgrund och skräp.
konturerna ritade inom varje klass användes för att generera en funktionsvektor, \(\mathop F\limits^{ \to }\) som härleddes från antalet pixlar som tillhör varje kontur. Funktionsvektorn från varje bild (200 från Dataset 1 och 200 från Dataset 2) definierades av Eq. 2.
där Ni, Ci, Bi och Di är antalet pixlar från kärnan, cytoplasman, bakgrunden och skräp av bilden \(i\) som visas i Fig. 2.

generering av funktionsvektorn från träningsbilderna
varje pixel som extraheras från bilden representerar inte bara dess intensitet utan också en uppsättning bildfunktioner som innehåller mycket information, inklusive textur, gränser och färg inom ett pixelområde på 0,201 occurm2. Att välja en lämplig funktionsvektor för att träna klassificeraren var en stor utmaning och en ny uppgift i det föreslagna tillvägagångssättet. Pixelnivåklassificeraren utbildades med totalt 226 träningsfunktioner från TWS. Klassificeraren utbildades med hjälp av en uppsättning TWS-träningsfunktioner som inkluderade: (i) brusreducering: Kuwahara och bilaterala filter i TWS toolkit användes för att träna klassificeraren vid brusborttagning. Dessa har rapporterats vara utmärkta filter för att ta bort brus samtidigt som kanterna bevaras, (ii) kantdetektering: ett Sobel-filter, Hessian-matris och Gabor-filter användes för att träna klassificeraren vid gränsdetektering i en bild och (iii) texturfiltrering: Medel -, varians -, median -, Max -, minimi-och entropifiltret användes för texturfiltrering.
avlägsnande av skräp
den främsta orsaken till de nuvarande begränsningarna hos många av de befintliga automatiserade pap-smear-analyssystemen är att de kämpar för att övervinna komplexiteten hos Pap-smear-strukturerna genom att försöka analysera bilden som helhet, som ofta innehåller flera celler och skräp. Detta har potential att orsaka fel i algoritmen och kräver högre beräkningskraft . Prover omfattas av artefakter—såsom blodceller, överlappande och vikta celler och bakterier-som hindrar segmenteringsprocesserna och genererar ett stort antal misstänkta föremål. Det har visats att klassificerare som är utformade för att skilja mellan normala celler och precancerösa celler vanligtvis ger oförutsägbara resultat när artefakter finns i pap-smear . I detta verktyg, en teknik för att identifiera livmoderhalsceller med hjälp av ett trefas sekventiellt elimineringsschema (avbildat i Fig. 3) används.

trefas Sekventiell elimineringsmetod för avstötning av skräp
det föreslagna trefaselimineringsschemat avlägsnar sekventiellt skräp från pap-smear om anses osannolikt att vara en livmoderhalscell. Detta tillvägagångssätt är fördelaktigt eftersom det gör det möjligt att fatta ett lägre dimensionellt beslut i varje steg.
storleksanalys
storleksanalys är en uppsättning procedurer för att bestämma ett antal storleksmätningar av partiklar . Området är en av de mest grundläggande funktionerna som används inom automatiserad cytologi för att separera celler från skräp. Pap-smear-analysen är ett väl studerat område med mycket förkunskaper om Cellegenskaper . En av de viktigaste förändringarna med kärnområdesbedömning är dock att cancerceller genomgår en väsentlig ökning av kärnstorleken . Därför är det mycket svårare att bestämma en övre storlekströskel som inte systematiskt utesluter diagnostiska celler, men har fördelen att minska sökutrymmet. Metoden som presenteras i detta dokument är baserad på en lägre storlek och övre storleksgräns för livmoderhalscellerna. Pseudokoden för tillvägagångssättet visas i Eq. 3.
där \(Area_{max} = 85,267\,{\upmu \text{m}}^{2}\) och \(Area_{min} = 625\,{\upmu \text{m}}^{2}\) härledd från Tabell 2.
objekten i bakgrunden betraktas som skräp och kasseras därmed från bilden. Partiklar som faller mellan\ (Area_{min}\) och\ (Area_{max}\) analyseras vidare under nästa steg av textur-och formanalys.
Formanalys
formen på objekten i en Pap-smear är en nyckelfunktion i differentieringen mellan celler och skräp . Det finns ett antal metoder för formbeskrivningsdetektering och dessa inkluderar regionbaserade och konturbaserade metoder . Regionbaserade metoder är mindre känsliga för buller men mer beräkningsintensiva, medan konturbaserade metoder är relativt effektiva att beräkna men mer känsliga för buller . I detta dokument har en regionbaserad metod (perimeter2/area (P2A)) använts . P2A-deskriptorn valdes på grund av att den beskriver likheten mellan ett objekt och en cirkel. Detta gör den väl lämpad som en cellkärnbeskrivare eftersom kärnor i allmänhet är cirkulära i sitt utseende. P2A kallas också formens kompakthet och definieras av Eq. 4.
där c är värdet av formens kompaktitet, A är området och p är kärnans omkrets. Skräp antogs vara föremål med ett P2A-värde större än 0,97 eller mindre än 0,15 enligt träningsfunktionerna (avbildad i Tabell 2).
texturanalys
textur är en mycket viktig egenskap som kan skilja mellan kärnor och skräp. Bildtextur är en uppsättning mätvärden som är utformade för att kvantifiera den upplevda strukturen i en bild . Inom en Pap-smear är fördelningen av genomsnittlig kärnfläckintensitet mycket smalare än fläckintensitetsvariationen bland skräpobjekt . Detta faktum användes som grund för att ta bort skräp baserat på deras bildintensiteter och färginformation med Zernike moments (ZM) . Zernike moments används för en mängd olika mönsterigenkänningsapplikationer och är kända för att vara robusta med avseende på buller och att ha en bra rekonstruktionskraft. I detta arbete, ZM som presenterats av Malm et al. funktion \ (f \ vänster ({r, \ theta } \ höger)\), i polära koordinater inuti en skiva centrerad i fyrkantig bild \(I\vänster( {x,y} \höger)\) av storlek \(m \gånger m\) ges av Eq. 5 användes.
\(v_{nl }^{*} \left( {r,\Theta } \right)\) betecknar det komplexa konjugatet av Zernike polynomet \(v_{nl} \left( {r,\Theta } \right)\). För att producera ett texturmått är magnituder från \(a_{nl}\) centrerade vid varje pixel i texturbilden i genomsnitt .
Feature extraction
framgången för en klassificeringsalgoritm beror i hög grad på korrektheten hos de funktioner som extraheras från bilden. Cellerna i pap-utstryk i datamängden som används är uppdelade i sju klasser baserat på egenskaper som storlek, yta, form och ljusstyrka hos kärnan och cytoplasman. Funktionerna extraherade från bilderna inkluderade morfologifunktioner som tidigare använts av andra . I detta dokument extraherades också tre geometriska egenskaper (soliditet, kompaktitet och excentricitet) och sex textfunktioner (medelvärde, standardavvikelse, varians, jämnhet, energi och entropi) från kärnan, vilket resulterade i totalt 29 funktioner som visas i tabell 3.
Feature selection
Feature selection är processen att välja delmängder av de extraherade funktionerna som ger de bästa klassificeringsresultaten. Bland de funktioner som extraheras kan vissa innehålla brus medan den valda klassificeraren kanske inte använder andra. Därför måste en optimal uppsättning funktioner bestämmas, eventuellt genom att försöka alla kombinationer. Men när det finns många funktioner exploderar de möjliga kombinationerna i antal och detta ökar algoritmens beräkningskomplexitet. Funktionsvalsalgoritmer klassificeras i stort sett i filter, omslag och inbäddade metoder .
metoden som används av verktyget kombinerar simulerad glödgning med en omslagsmetod. Detta tillvägagångssätt har föreslagits i men, i detta dokument, utförandet av funktionsvalet utvärderas med hjälp av en slumpmässig skogsalgoritm med dubbel strategi . Simulerad glödgning är en probabilistisk teknik för att approximera det globala optimumet för en given funktion. Tillvägagångssättet är väl lämpat för att säkerställa att den optimala uppsättningen funktioner väljs. Sökningen efter den optimala uppsättningen styrs av ett träningsvärde . När simulerad glödgning är klar jämförs alla olika delmängder av funktioner och den starkaste (det vill säga den som utför bäst) väljs. Fitness value search erhölls med ett omslag där k-faldig korsvalidering användes för att beräkna felet på klassificeringsalgoritmen. Olika kombinationer från de extraherade funktionerna framställs, utvärderas och jämförs med andra kombinationer. En prediktiv modell används sedan för att utvärdera en kombination av funktioner och tilldela en poäng baserat på modellnoggrannhet. Fitnessfelet som ges av omslaget används som fitnessfel av den simulerade glödgningsalgoritmen. En fuzzy C-means-algoritm lindades in i en svart låda, från vilken ett uppskattat fel erhölls för de olika funktionskombinationerna som visas i Fig. 4.

det fuzzy C-medlet är inslaget i en svart låda från vilken ett uppskattat fel erhålls
Fuzzy C-medel tillåter datapunkter i dataset att tillhöra alla kluster, med medlemskap i intervallet (0-1) som visas i EQ. 6.
där \(m_{ik}\) är medlemskapet för datapunkt k till klustercenter i, \(d_{jk}\) är avståndet från klustercenter j till datapunkt k och q exporten är en exponent som bestämmer hur starka medlemskapen ska vara. Den fuzzy C-means algoritmen implementerades med hjälp av fuzzy toolbox i Matlab.
defuzzifieringen
en fuzzy C-means-algoritm berättar inte vilken information klustren innehåller och hur den informationen ska användas för klassificering. Det definierar dock hur datapunkter tilldelas medlemskap i de olika klustren och detta fuzzy-medlemskap används för att förutsäga klassen för en datapunkt . Detta övervinns genom defuzzification. Ett antal defuzzifieringsmetoder finns . Men i det här verktyget har varje kluster ett fuzzy medlemskap (0-1) av alla klasser i bilden. Träningsdata tilldelas klustret närmast det. Procentandelen träningsdata för varje klass som tillhör kluster a ger klustrets medlemskap, kluster A = till de olika klasserna, där i är inneslutningen i kluster A och j i det andra klustret. Intensitetsmåttet läggs till i medlemsfunktionen för varje kluster med hjälp av en fuzzy clustering defuzzification algoritm. Ett populärt tillvägagångssätt för defuzzification av fuzzy partition är tillämpningen av principen om maximal medlemsgrad där datapunkt k tilldelas klass m om, och endast om, dess medlemsgrad \(m_{ik}\) till kluster i, är den största. Chuang et al. föreslog att justera medlemskapsstatus för varje datapunkt med hjälp av medlemskapsstatus för sina grannar.
i det föreslagna tillvägagångssättet används en defuzzifieringsmetod baserad på Bayesian Sannolikhet för att generera en probabilistisk modell av medlemsfunktionen för varje datapunkt och tillämpa modellen på bilden för att producera klassificeringsinformationen. Den probabilistiska modellen beräknas enligt nedan:
-
konvertera möjlighetsfördelningarna i partitionsmatrisen (kluster) till sannolikhetsfördelningar.
-
konstruera en probabilistisk modell av datafördelningarna som i .
-
använd modellen för att producera klassificeringsinformationen för varje datapunkt med hjälp av Eq. 7.
där \(p\vänster( {a_{i} } \höger),i = 0 \ldots .c\) är den tidigare sannolikheten för \(a_{i}\) som kan beräknas med metoden där den tidigare sannolikheten alltid är proportionell mot massan för varje klass.
antalet kluster att använda bestämdes för att säkerställa att den byggda modellen kan beskriva data på bästa möjliga sätt. Om för många kluster väljs, finns det risk för överfitting av bruset i data. Om för få kluster väljs kan en dålig klassificerare vara resultatet. Därför utfördes en analys av antalet kluster mot korsvalideringstestfelet. Ett optimalt antal 25 kluster uppnåddes och överträning inträffade över dessa antal kluster. En defuzzification exponent av 1.0930 erhölls med 25 kluster, tiofaldig korsvalidering och 60 omprogrammeringar och användes för att beräkna fitnessfelet för funktionsval där totalt 18 funktioner av de 29 funktionerna valdes för konstruktion av klassificeraren. De valda funktionerna var: nucleus area; nucleus grå nivå; nucleus Kortaste diameter; nucleus längsta; nucleus perimeter; maxima i nucleus; minima i nucleus; cytoplasm area; cytoplasma grå nivå; cytoplasma perimeter; nucleus till cytoplasma ratio; nucleus excentricitet, nucleus standardavvikelse, nucleus grå nivå varians; nucleus grå nivå entropi; nucleus relativ position; nucleus grå nivå medelvärde och nucleus grå värden energi.
Klassificeringsutvärdering
i detta dokument antogs den hierarkiska modellen för effekten av diagnostiska bildsystem som föreslagits av Fryback och Thornbury som en vägledande princip för utvärderingen av verktyget som visas i Tabell 4.
känslighet mäter andelen faktiska positiva effekter som identifieras korrekt som sådana medan specificitet mäter andelen faktiska negativa effekter som identifieras korrekt som sådana. Känslighet och specificitet beskrivs av Eq. 8.
där TP = sanna positiva, FN = falska negativa, TN = sanna negativa och FP = falska positiva.
GUI design och integration
bildbehandlingsmetoderna som beskrivs ovan implementerades i Matlab och exekveras via ett Java grafiskt användargränssnitt (GUI) som visas i Fig. 5. Verktyget har en panel där en Pap-smear-bild laddas och cytoteknikern väljer en lämplig metod för scensegmentering (baserat på TWS-klassificerare), borttagning av skräp (baserat på den tre sekventiella elimineringsmetoden) och gränsdetektering (om det anses nödvändigt, med hjälp av kantig kantdetekteringsmetod), varefter funktioner extraheras med knappen extract features.
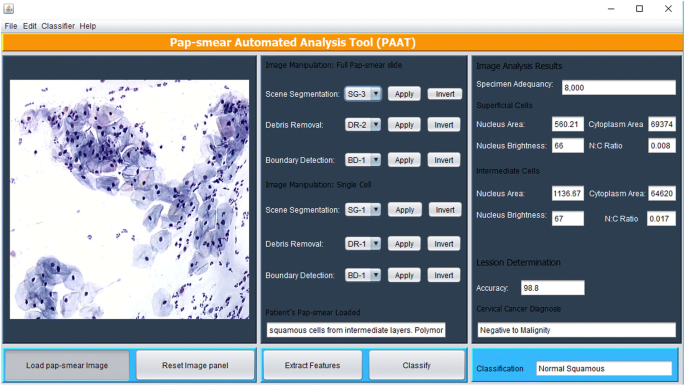
PAT grafiskt användargränssnitt
verktyget skannar genom pap-smear för att analysera alla objekt som återstod efter borttagning av skräp. De 18 funktioner som beskrivs i funktionsval extraheras från varje objekt och används för att klassificera varje cell med hjälp av den fuzzy C-means-algoritmen som beskrivs i klassificeringsmetoden. Slumpmässigt visas extraherade egenskaper hos en ytlig cell och en mellanliggande cell i resultatpanelen för bildanalys. När funktionerna har extraherats trycker cytotechnician (användaren) på klassificeringsknappen och verktyget avger en diagnos (positiv till malignitet eller negativ till malignitet) och klassificerar diagnosen till en av de 7 klasserna/stadierna av livmoderhalscancer enligt träningsdatasatsen.