Hur man gör semantisk segmentering med Deep learning
den här artikeln är en omfattande översikt inklusive en steg-för-steg-guide för att implementera en djupinlärningsbildsegmenteringsmodell.
Vi delade en ny uppdaterad blogg om semantisk segmentering här: en 2021-guide till semantisk segmentering
numera är semantisk segmentering ett av de viktigaste problemen inom datorsyn. När man tittar på den stora bilden är semantisk segmentering en av de höga uppgifterna som banar vägen mot fullständig scenförståelse. Betydelsen av scenförståelse som ett kärndatorsynsproblem framhävs av det faktum att ett ökande antal applikationer ger näring från att härleda kunskap från bilder. Några av dessa applikationer inkluderar självkörande fordon, interaktion mellan människa och dator, virtuell verklighet etc. Med populariteten för djupt lärande de senaste åren hanteras många semantiska segmenteringsproblem med hjälp av djupa arkitekturer, oftast Konvolutionella neurala nät, som överträffar andra tillvägagångssätt med stor marginal när det gäller noggrannhet och effektivitet.
- Vad är semantisk segmentering?
- Vad är de befintliga semantiska segmenteringsmetoderna?
- 1-Regionbaserad semantisk segmentering
- 2-helt Convolutional nätverksbaserad semantisk segmentering
- 3-svagt övervakad semantisk segmentering
- gör semantisk segmentering med full-Convolutional Network
- steg 1
- steg 2
- steg 3
- steg 4
- Steg 5
- du kanske är intresserad av våra senaste inlägg på:
Vad är semantisk segmentering?
semantisk segmentering är ett naturligt steg i progressionen från grov till fin slutsats:ursprunget kan lokaliseras vid klassificering, som består av att göra en förutsägelse för en hel ingång.Nästa steg är lokalisering / detektering, som inte bara ger klasserna utan också ytterligare information om den rumsliga platsen för dessa klasser.Slutligen uppnår semantisk segmentering finkornig inferens genom att göra täta förutsägelser som leder till etiketter för varje pixel, så att varje pixel är märkt med klassen av dess inneslutande objektmalmregion.
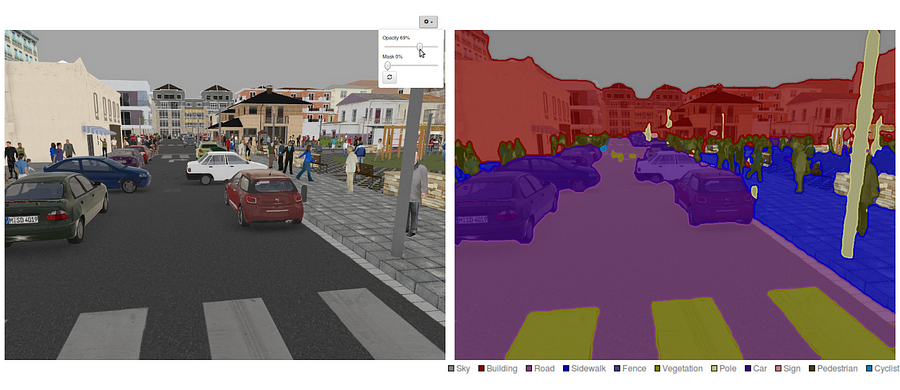
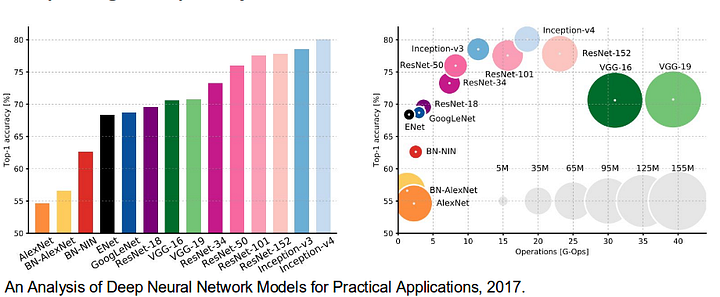
det är också värt att granska några vanliga djupa nätverk som har gjort betydande bidrag till datasynfältet, eftersom de ofta används som grund för semantiska segmenteringssystem:
- alexnet: Torontos banbrytande Deep CNN som vann ImageNet-tävlingen 2012 med en Testnoggrannhet på 84, 6%. Den består av 5 convolutional lager, max-pooling ettor, ReLUs som icke-linjäriteter, 3 helt convolutional lager, och dropout.
- VGG-16: denna Oxfords modell vann 2013 ImageNet-tävlingen med 92,7% noggrannhet. Den använder en stapel faltningslager med små mottagliga fält i de första lagren istället för få lager med stora mottagliga fält.
- GoogLeNet: detta Googles nätverk vann 2014 ImageNet-tävlingen med en noggrannhet på 93, 3%. Den består av 22 lager och en nyligen introducerad byggsten som heter inception module. Modulen består av ett nätverk-i-nätverkslager, en pooloperation, ett stort faltningslager och ett litet faltningslager.
- ResNet: denna Microsofts modell vann 2016 ImageNet-tävlingen med 96, 4% noggrannhet. Det är välkänt på grund av dess djup (152 lager) och införandet av kvarvarande block. De återstående blocken löser problemet med att träna en riktigt djup arkitektur genom att införa identitetshoppanslutningar så att lager kan kopiera sina ingångar till nästa lager.
Vad är de befintliga semantiska segmenteringsmetoderna?
en allmän semantisk segmenteringsarkitektur kan i stort sett betraktas som ett kodarnätverk följt av ett avkodningsnätverk:
- kodaren är vanligtvis ett förutbildat klassificeringsnätverk som VGG/ResNet följt av ett avkodningsnätverk.
- avkodarens uppgift är att semantiskt projicera de diskriminerande funktionerna (lägre upplösning) som kodaren lärt sig på pixelutrymmet (högre upplösning) för att få en tät klassificering.
Till skillnad från klassificering där slutresultatet av det mycket djupa nätverket är det enda viktiga, kräver semantisk segmentering inte bara diskriminering på pixelnivå utan också en mekanism för att projicera de diskriminerande funktionerna som lärt sig i olika stadier av kodaren på pixelutrymmet. Olika tillvägagångssätt använder olika mekanismer som en del av avkodningsmekanismen. Låt oss utforska de 3 huvudmetoderna:
1-Regionbaserad semantisk segmentering
de regionbaserade metoderna följer i allmänhet pipelinen” segmentering med igenkänning”, som först extraherar regioner med fri form från en bild och beskriver dem, följt av regionbaserad klassificering. Vid testtid omvandlas de regionbaserade förutsägelserna till pixelförutsägelser, vanligtvis genom att märka en pixel enligt den högsta poängregionen som innehåller den.
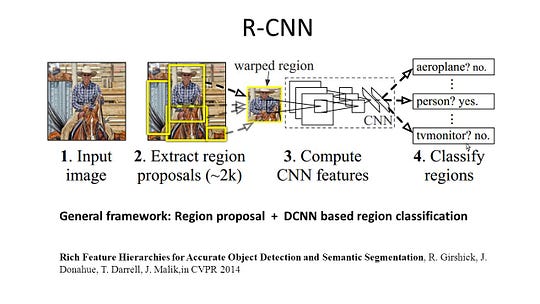
R-CNN (regioner med CNN-funktion) är ett representativt arbete för regionbaserade metoder. Den utför den semantiska segmenteringen baserat på objektdetekteringsresultaten. För att vara specifik använder R-CNN först selektiv sökning för att extrahera en stor mängd objektförslag och beräknar sedan CNN-funktioner för var och en av dem. Slutligen klassificerar den varje region med hjälp av de klassspecifika linjära SVM: erna. Jämfört med traditionella CNN-strukturer som huvudsakligen är avsedda för bildklassificering kan R-CNN ta itu med mer komplicerade uppgifter, såsom objektdetektering och bildsegmentering, och det blir till och med en viktig grund för båda fälten. Dessutom kan R-CNN byggas ovanpå alla CNN-benchmarkstrukturer, som AlexNet, VGG, GoogLeNet och ResNet.
för bildsegmenteringsuppgiften extraherade R-CNN 2 typer av funktioner för varje region: full regionfunktion och förgrundsfunktion och fann att det kunde leda till bättre prestanda när de sammanfogades som regionfunktionen. R-CNN uppnådde betydande prestandaförbättringar på grund av att använda de mycket diskriminerande CNN-funktionerna. Men det lider också av ett par nackdelar för segmenteringsuppgiften:
- funktionen är inte kompatibel med segmenteringsuppgiften.
- funktionen innehåller inte tillräckligt med rumslig information för exakt gränsgenerering.
- att generera segmentbaserade förslag tar tid och skulle i hög grad påverka den slutliga prestandan.
På grund av dessa flaskhalsar har ny forskning föreslagits för att ta itu med problemen, inklusive SDS, Hypercolumns, Mask R-CNN.
2-helt Convolutional nätverksbaserad semantisk segmentering
den ursprungliga fullt Convolutional Network (FCN) lär sig en kartläggning från pixlar till pixlar, utan att extrahera regionförslagen. FCN network pipeline är en förlängning av den klassiska CNN. Huvudideen är att få den klassiska CNN att ta in godtyckliga bilder som inmatning. Begränsningen av CNN: er att acceptera och producera etiketter endast för specifika ingångar kommer från de helt anslutna lagren som är fixerade. I motsats till dem har FCN bara fällnings-och poollager som ger dem möjlighet att göra förutsägelser om godtyckliga ingångar.
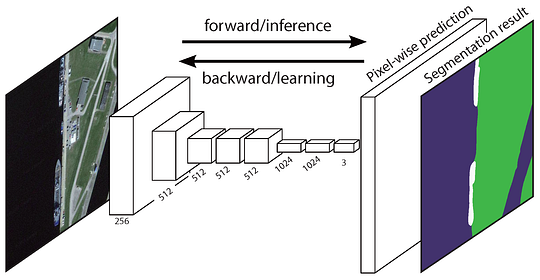
en fråga i denna specifika FCN är att genom att sprida sig genom flera alternerade convolutional och pooling lager, kommer den upplösningen av kartorna för utmatningsfunktionen är samplad. Därför är de direkta förutsägelserna av FCN vanligtvis i låg upplösning, vilket resulterar i relativt fuzzy objektgränser. En mängd mer avancerade FCN-baserade tillvägagångssätt har föreslagits för att ta itu med denna fråga, inklusive SegNet, DeepLab-CRF och utvidgade svängningar.
3-svagt övervakad semantisk segmentering
de flesta av de relevanta metoderna i semantisk segmentering är beroende av ett stort antal bilder med pixelvisa segmenteringsmasker. Att manuellt kommentera dessa masker är dock ganska tidskrävande, frustrerande och kommersiellt dyrt. Därför har några svagt övervakade metoder nyligen föreslagits, som är dedikerade till att uppfylla den semantiska segmenteringen genom att använda annoterade avgränsningsboxar.

till exempel använde Boxsup begränsningsboxen som en övervakning för att träna nätverket och iterativt förbättra de beräknade maskerna för semantisk segmentering. Simple behandlade den svaga övervakningsbegränsningen som en fråga om inmatningsmärkningsbrus och utforskade rekursiv träning som en de-noising-strategi. Pixelnivåmärkning tolkade segmenteringsuppgiften inom ramen för flera instanser och lade till ett extra lager för att begränsa modellen för att tilldela större vikt till viktiga pixlar för bildnivåklassificering.
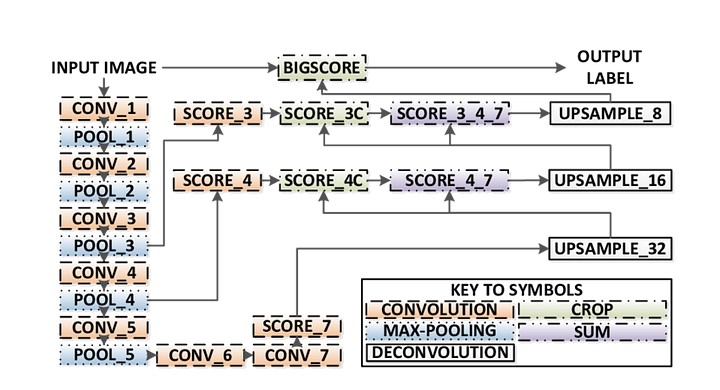
gör semantisk segmentering med full-Convolutional Network
i det här avsnittet, låt oss gå igenom en steg-för-steg — implementering av den mest populära arkitekturen för semantisk segmentering-Full-Convolutional Net (FCN). Vi implementerar det med TensorFlow-biblioteket i Python 3, tillsammans med andra beroenden som Numpy och Scipy.In denna övning kommer vi att märka pixlarna på en väg i bilder med FCN. Vi kommer att arbeta med Kitti Road Dataset för väg – / körfältsdetektering. Detta är en enkel övning från Udacitys självkörande bil Nano-grad program, som du kan lära dig mer om installationen i denna GitHub repo.

här är de viktigaste funktionerna i FCN-arkitekturen:
- FCN överför kunskap från vgg16 för att utföra semantisk segmentering.
- de helt anslutna lagren av VGG16 konverteras till helt faltningslager med 1×1 faltning. Denna process ger en klass närvaro värme karta i låg upplösning.
- uppsamplingen av dessa semantiska funktionskartor med låg upplösning görs med hjälp av transponerade omvälvningar (initialiserade med bilinära interpoleringsfilter).
- vid varje steg förfinas samplingsprocessen ytterligare genom att lägga till funktioner från grovare men högre upplösningskartor från lägre lager i VGG16.
- hoppa anslutning införs efter varje faltning block för att möjliggöra efterföljande blocket för att extrahera mer abstrakta, klass-framträdande funktioner från de tidigare sammanslagna funktioner.
det finns 3 versioner av FCN (FCN-32, FCN-16, FCN-8). Vi implementerar FCN-8, som detaljerat steg för steg nedan:
- Encoder: en förutbildad VGG16 används som en kodare. Avkodaren startar från lager 7 i VGG16.
- FCN Layer-8: Det sista helt anslutna lagret av VGG16 ersätts av en 1×1-faltning.
- FCN Layer-9: FCN Layer-8 är samplad 2 gånger för att matcha dimensioner med lager 4 av VGG 16, med användning av transponerade faltning med parametrar: (kernel=(4,4), stride=(2,2), paddding=’samma’). Därefter tillsattes en hoppanslutning mellan lager 4 i VGG16 och FCN Layer-9.
- FCN Layer-10: FCN Layer-9 är samplad 2 gånger för att matcha dimensioner med lager 3 av VGG16, med användning av transponerade faltning med parametrar: (kernel=(4,4), stride=(2,2), paddding=’samma’). Därefter tillsattes en hoppanslutning mellan lager 3 i VGG 16 och FCN Layer-10.
- FCN Layer-11: FCN Layer – 10 är samplad 4 gånger för att matcha dimensioner med inmatningsbildstorlek så vi får den faktiska bilden tillbaka och djupet är lika med antalet klasser, med hjälp av transponerade faltning med parametrar:(kernel=(16,16), stride=(8,8), paddding=’samma’).
steg 1
vi laddar först den förutbildade vgg-16-modellen i TensorFlow. Med TensorFlow-sessionen och sökvägen till vgg-mappen (som kan laddas ner här) returnerar vi tupeln av tensorer från VGG-modellen, inklusive bildingången, keep_prob (för att kontrollera bortfallshastighet), layer 3, layer 4 och layer 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7vgg16 funktion
steg 2
nu fokuserar vi på att skapa lager för en FCN, med hjälp av tensorer från vgg-modellen. Med tanke på tensorer för vgg-lagerutgång och antalet klasser att klassificera, returnerar vi tensorn för det sista lagret av den utgången. I synnerhet tillämpar vi en 1×1-faltning på kodarlagren och lägger sedan till avkodningslager i nätverket med hoppa över anslutningar och sampling.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11lagerfunktion
steg 3
nästa steg är att optimera vårt neurala nätverk, även bygga Tensorflödesförlustfunktioner och optimeringsoperationer. Här använder vi cross entropi som vår förlustfunktion och Adam som vår optimeringsalgoritm.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opoptimera funktion
steg 4
här definierar vi train_nn-funktionen, som tar in viktiga parametrar inklusive antal epoker, batchstorlek, förlustfunktion, optimeringsoperation och platshållare för inmatningsbilder, etikettbilder, inlärningshastighet. För träningsprocessen ställer vi också in keep_probability till 0.5 och learning_rate till 0.001. För att hålla reda på framstegen skriver vi också ut förlusten under träningen.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Steg 5
slutligen är det dags att träna vårt nät! I den här körfunktionen bygger vi först vårt nät med funktionen load_vgg, layers och optimize. Sedan tränar vi nätet med train_nn-funktionen och sparar inferensdata för poster.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)kör funktion
om våra parametrar väljer vi epoker = 40, batch_size = 16, num_classes = 2 och image_shape = (160, 576). Efter att ha gjort 2 provpass med dropout = 0.5 och dropout = 0.75 fann vi att 2: a försöket ger bättre resultat med bättre genomsnittliga förluster.

för att se hela koden, kolla in den här länken: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
om du gillade det här stycket, skulle jag älska det dela det med dig och sprida kunskapen.
du kanske är intresserad av våra senaste inlägg på:
- AWS Textract
- Data Extraction
börja använda Nanonets för automatisering
prova modellen eller begär en demo idag!
försök nu
