komma till rätta med Reinforcement Learning via Markov Decision Process
denna artikel publicerades som en del av Data Science Blogathon.
introduktion
Reinforcement Learning (RL) är en inlärningsmetodik genom vilken eleven lär sig att bete sig i en interaktiv miljö med sina egna handlingar och belöningar för sina handlingar. Eleven, ofta kallad agent, upptäcker vilka åtgärder som ger maximal belöning genom att utnyttja och utforska dem.

en nyckelfråga är – hur skiljer sig RL från övervakat och oövervakat lärande?
skillnaden kommer i interaktionsperspektivet. Övervakad inlärning berättar användaren / agenten direkt vilken åtgärd han måste utföra för att maximera belöningen med hjälp av en träningsdataset med märkta exempel. Å andra sidan gör RL direkt agenten att utnyttja belöningar (positiva och negativa) det blir att välja sin åtgärd. Det skiljer sig alltså från oövervakat lärande också eftersom oövervakat lärande handlar om att hitta struktur dold i samlingar av omärkta data.
formulering av Förstärkningsinlärning via Markov Decision Process (MDP)
de grundläggande elementen i ett förstärkningsinlärningsproblem är:
- miljö: omvärlden med vilken agenten interagerar
- tillstånd: nuvarande situation för agenten
- belöning: numerisk återkopplingssignal från miljön
- Policy: metod för att kartlägga agentens tillstånd till åtgärder. En policy används för att välja en åtgärd vid ett givet tillstånd
- värde: framtida belöning (försenad belöning) som en agent skulle få genom att vidta en åtgärd i ett givet tillstånd
Markov Decision Process (MDP) är en matematisk ram för att beskriva en miljö i förstärkningsinlärning. Följande figur visar agent – miljö interaktion i MDP:
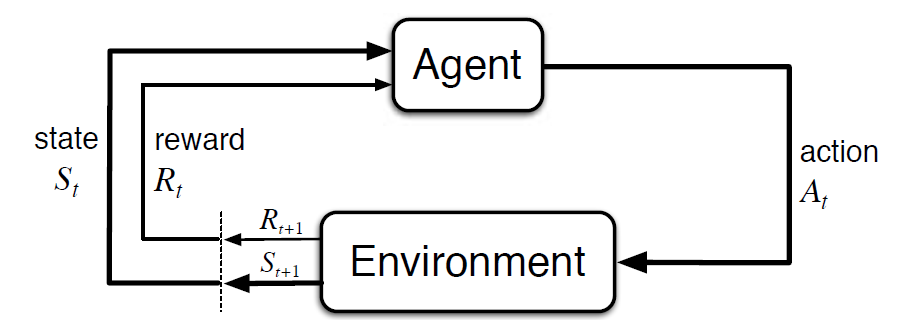
Mer specifikt interagerar agenten och miljön vid varje diskret tidssteg, t = 0, 1, 2, 3…At varje gång steg, agenten får information om miljötillståndet St.baserat på miljötillståndet vid omedelbar t, agenten väljer en åtgärd vid. I följande ögonblick får agenten också en numerisk belöningssignal Rt + 1. Detta ger således upphov till en sekvens som S0, A0, R1, S1, A1, R2…
de slumpmässiga variablerna Rt och St har väldefinierade diskreta sannolikhetsfördelningar. Dessa sannolikhetsfördelningar är endast beroende av föregående tillstånd och handling på grund av Markov-egendom. Låt S, A och R vara uppsättningarna av stater, handlingar och belöningar. Då är sannolikheten att värdena för St, Rt och vid värden s’, r och a med tidigare tillstånd s ges av,
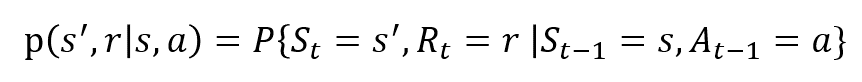
funktionen p styr processens dynamik.
Låt oss förstå detta med ett exempel
låt oss nu diskutera ett enkelt exempel där RL kan användas för att implementera en kontrollstrategi för en uppvärmningsprocess.
tanken är att kontrollera temperaturen i ett rum inom de angivna temperaturgränserna. Temperaturen inuti rummet påverkas av yttre faktorer som utetemperatur, den inre värmen som genereras etc.
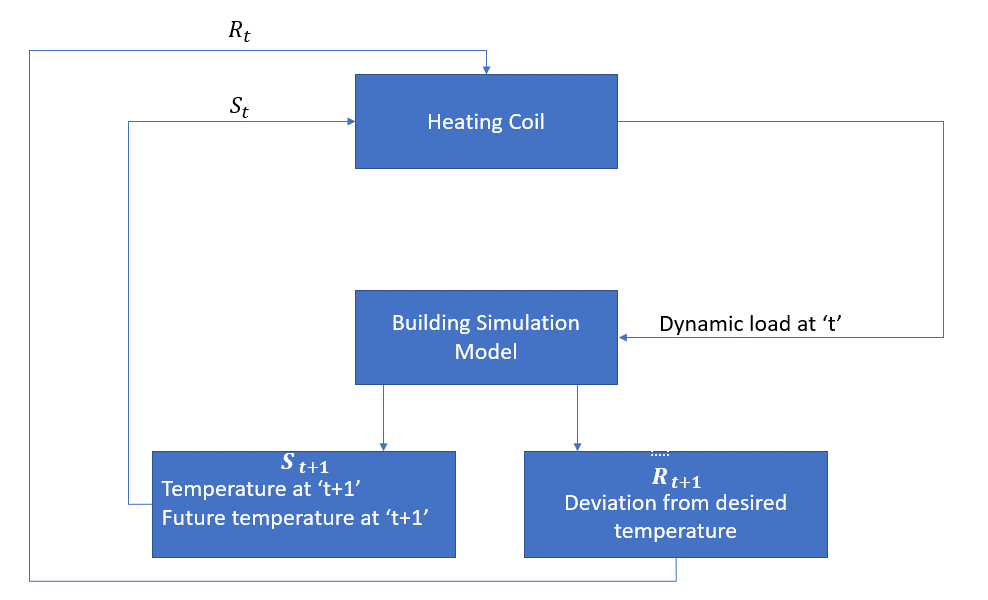
agenten är i detta fall värmespolen som måste bestämma mängden värme som krävs för att styra temperaturen inuti rummet genom att interagera med miljön och se till att temperaturen inuti rummet ligger inom det angivna intervallet. Belöningen är i detta fall i grunden den kostnad som betalas för att avvika från de optimala temperaturgränserna.
åtgärden för agenten är den dynamiska belastningen. Denna dynamiska belastning matas sedan till rumssimulatorn som i grunden är en värmeöverföringsmodell som beräknar temperaturen baserat på den dynamiska belastningen. Så i detta fall är miljön simuleringsmodellen. Den statliga variabeln St innehåller både nuvarande och framtida belöningar.
följande blockschema förklarar hur MDP kan användas för att styra temperaturen i ett rum:
begränsningar av denna metod
Förstärkningsinlärning lär av staten. Staten är input för beslutsfattande. Därför bör de statliga ingångarna ges korrekt. Som vi har sett finns det flera variabler och dimensionen är enorm. Så att använda det för riktiga fysiska system skulle vara svårt!
Vidare läsning
för att veta mer om RL kan följande material vara till hjälp:
- Reinforcement Learning: En introduktion av Richard.S. Sutton och Andrew.G. Barto: http://incompleteideas.net/book/the-book-2nd.html
- videoföreläsningar av David Silver finns på YouTube
- https://gym.openai.com/ är en verktygslåda för vidare utforskning
du kan också läsa den här artikeln på vår mobilapp ![]()
